- Guide Content
AWS Lambda Architecture: What You Need to Know
Serverless architecture is becoming a popular pattern for deploying applications on the cloud. It offers a pay-as-you-go model in which infrastructure provisioning and maintenance are managed by cloud providers and developers only have to worry about functional code.
Applications that use AWS Lambda are built on the same pattern, which enables an event-driven architecture. An event-driven architecture uses events to trigger and communicate between two services. An event can be a change in state, an update to a record, or a new data record. An event-driven architecture has three main components: event producers, event routers, and event consumers. An event producer generates the event and publishes it to the router. The router filters, processes and sends the event to the consumer for further processing. Producers and consumers are fully decoupled and unaware of each other.
In this article
AWS Lambda Architecture Components
{kind=link}
Event Sources
As described above, the producer is a starting point for an event-driven architecture and is also known as an event source in AWS Lambda architecture. An event source is going to publish the event to a Lambda function and can be of various types:
- A REST API method call (It can be done through an API gateway such as AWS API Gateway, or Apigee)
- A CloudWatch Event triggering a Lambda function with the change in the state of an AWS resource (e.g., invoking a Lambda function to log the change in the state of the EC2 instance)
- A new record in a DynamoDB table stream. Lambda polls the stream and invokes the function linked with the DynamoDB stream with any change in the record.
- An S3 event notification for a new file upload or update to an existing file can trigger a Lambda function.
- An event can be a CloudWatch scheduler using a cron job
Tips from the experts
-
Optimize function packaging
Reduce the size of your deployment packages by using minimal libraries and dependencies. Use AWS Lambda Layers to manage common dependencies separately, which can help reduce cold start times and improve deployment speeds. -
Use asynchronous invocations wisely
While asynchronous invocations can decouple your system and improve performance, monitor the dead-letter queue (DLQ) usage carefully to handle failures. Always configure retries and error handling policies explicitly to avoid unexpected data loss or application downtime. -
Implement fine-grained IAM policies
Instead of using broad permissions, create least-privilege IAM policies specific to each Lambda function's needs. Regularly audit and refine these permissions to minimize security risks and follow the principle of least privilege. -
Optimize VPC connectivity
To minimize latency when your Lambda functions are within a VPC, use the latest ENI and hyperplane enhancements from AWS. Place your Lambda functions in subnets with adequate IP capacity to avoid runtime failures due to ENI limitations, and ensure NAT gateways are optimally configured to handle outbound traffic. -
Design for idempotency and statelessness
Make sure your Lambda functions are idempotent, especially when dealing with retries in event-driven systems. Design your functions to be stateless, storing any necessary state externally in services like DynamoDB, S3, or ElastiCache, to ensure scalability and resilience. -
Use custom metrics and alerts
While CloudWatch offers basic monitoring, enhance your observability with custom metrics. Use these metrics to create detailed dashboards and set up alarms for key performance indicators (KPIs) such as memory usage, duration, and error rates, allowing proactive responses to performance bottlenecks. -
Automate deployment pipelines
Integrate AWS Lambda deployments with CI/CD pipelines using tools like AWS CodePipeline, AWS CodeBuild, or third-party tools like Jenkins. Use infrastructure-as-code (IaC) tools like AWS CloudFormation, Serverless Framework, or Terraform to manage Lambda function versions and aliases systematically. -
Monitor cold start performance
Regularly test and monitor cold start performance, particularly for languages like Java and .NET, which can have higher startup times. Use provisioned concurrency where necessary, or consider optimizing initialization code and reducing package sizes to mitigate cold start impacts.

The Lambda Function
The Lambda function is at the heart of the Lambda architecture. It enables implementing a Function-as-a-Service approach. You simply write the business logic as a function and implement a handler method. It accepts the events being passed by event sources, then processes them based on the logic written. Eventually, it publishes the events to other services.
Once you deploy the function on the AWS Lambda service, it zips the code and uploads it to an S3 bucket. When it is invoked, it downloads the code from S3 and unzips it. It starts the instance, installs any dependencies, and executes the code.
Lambda supports several languages including NodeJS, Java, Python, and GO. If a function connects to the VPC resources, it takes a minute or so as it needs to create ENI at runtime.
Versioning and Alias
A Function can have multiple versions or aliases. A version can have two states: unpublished or published. The unpublished version changes when we make code or configuration changes. Once we publish the version, it becomes a snapshot and can’t be changed.
An alias is a named resource that maps to a particular version. It can be changed to map to a different version. For example, you can create an alias with the name ‘Prod’ that maps it to a version meant for production deployment.
Concurrency
In an AWS Lambda architecture, scalability is achieved horizontally by spinning up multiple instances to handle the events, also known as concurrency. There are 3 types of concurrencies:
Unreserved Concurrency
If a Lambda function doesn’t define the concurrency limit, it uses the default 1000 for an account per region. This is the default option you get when creating any Lambda function.
Reserved Concurrency
This option enables you to configure the max limit for a function. It can be max 900 to ensure that the rest of the limit is kept for the functions that didn’t define the concurrency at the function level. Configuring this is a good practice to ensure that one function’s scaling doesn’t impact the performance of other functions.
Provisioned Concurrency
Provisioned concurrency is introduced to reduce the latency and minimize the cold start time of a Lambda invocation. You can configure how many instances of Lambda functions should be readily available to serve the requests at a given time. This will ensure the instances are warm with very low latency and serve the events in bulk. Once the function reaches the threshold of the provisioned concurrency, further scaling is done using the defined reserved concurrency.
Environment Variables
Lambda can store credentials using environment variables. Environment variables can also be used to store application configuration information and can be accessed through the AWS SDK code. Variables can be encrypted using KMS CMKs (customer-managed keys).
Lambda VPC Configurations
Lambda functions are deployed on a VPC owned and managed by AWS. If the function needs access to your own VPC resources, it can be configured. It uses ENI and hyperplane features of AWS to have the network connectivity between the two VPCs. All VPC-level settings such as subnets, Availability Zones, and security groups are applied to it.

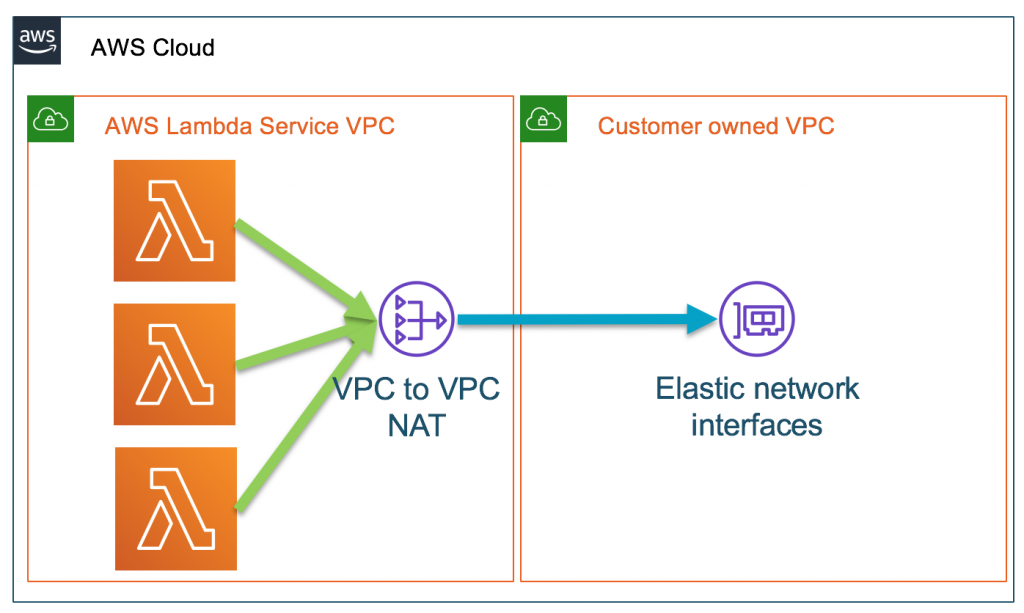{kind=link}
Lambda Destinations
Lambda’s new feature — Lambda Destination — enables the function to integrate with other AWS services without any glue code. It works only for asynchronous and stream invocations. It can connect the function to SQS, another Lambda function, and the AWS EventBridge service.
IAM Access
Lambda functions need certain accesses to execute and integrate with other AWS services. This is enabled through IAM roles. It needs the default AWSLambdaBasicExecutionRole to execute itself. Besides, it needs an IAM role for accessing CloudWatch Logs, X-Ray and other AWS services to complete the serverless workflow.
AWS Lambda Monitoring
By default, Lambda functions send their log events to the CloudWatch Logs service. It just needs to enable IAM access to this service. It creates a LogGroup for each function and based on the invocation of functions, it groups them together in several LogStreams. The function also sends metrics data to CloudWatch Logs and you can build graphs and dashboards from these metrics. You can monitor invocation metrics, performance metrics, and concurrency metrics.
A Lambda function can be configured and enabled for X-Ray distributed tracing. For example, If a Lambda function calls an S3 bucket and you want to see what is the latency performance of the S3 service response for GET and PUT calls, it can be seen using X-Ray graphs and traces. You just need to enable X-Ray tracing. If you want to see the detailed events for each service, you need to use the AWS SDK to write the events in the handler method.
A better option than both CloudWatch and X-Ray is the Lumigo serverless monitoring platform. Lumigo features one-click auto-tracing for Lambdas and other services. Once it starts monitoring your application, it brings all of the information you need to debug errors and solve performance issues in an extremely easy way that saves many hours and headaches.
Testing Lambda Functions
Lambda provides a testing option in the AWS console in which you can set the events data and run the test. It can be very useful for unit testing the function and ensuring it works as expected. You can test a specific version, alias, or the latest function code, even if it is not published yet.
Event Consumers
Last but not least is the third major component of an AWS Lambda architecture: event consumers. Lambda functions alone are not sufficient to implement business logic. It requires several different types of services such as databases, messaging queues, streams, object storage, and 3rd-party services, such as Stripe, Twilio, and Paypal. These services are the consumers of the events published by the Lambda function. They can include DyanmoDB, S3, SQS, SNS, another Lambda function, and any REST APIs hosted on AWS or outside of it.

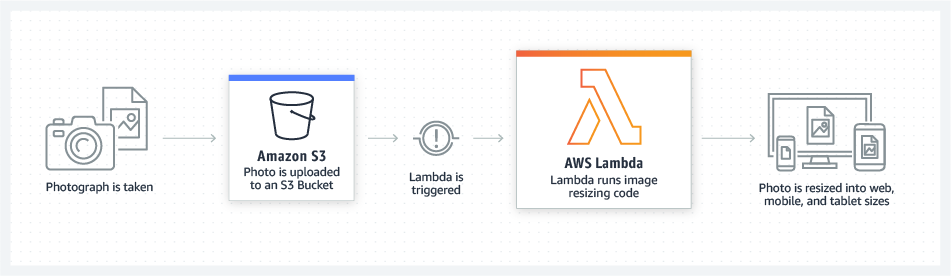{kind=link}
Summary
In this article, we have talked through all the building blocks of an AWS Lambda architecture. It is a very vast product and has all the features required to implement a serverless architecture. It has a smooth integration with many AWS services and enables an event-driven architecture. With the introduction of new features like provisioned concurrency, Lambda destinations have made it a much more mature product compared to those from other cloud providers.