










How do SQS and Lambda Work Together?
Amazon SQS is a lightweight, fully-managed message queueing service. You can use SQS to decouple and scale microservices, serverless applications, and distributed systems. SQS makes it easy to store, receive, and send messages between software components.
AWS Lambda offers a fully-managed serverless runtime. Lambda enables you to run code in multiple different languages without having to provision servers. The service lets you configure a Lambda function, which executes in response to certain events or as part of an orchestrated process. Lambda runs code in parallel and processes invocations individually, scaling with the size of the workload.
You can configure SQS queues as event sources for Lambda. Once you set this up, Lambda functions are automatically triggered when messages arrive to an SQS queue. Lambda can then automatically scale up and down according to the number of inflight messages in a queue.
This means Lambda takes charge and automates tasks like polling, reading and removing messages from a queue. Messages that are successfully processed are removed and failed messages are forwarded to the DLQ or returned to the queue. There is no need to explicitly configure these steps inside a Lambda function.
In this article, you will learn:
- How do SQS and Lambda Work Together?
- SQS Lambda Benefits and Limitations
- Quick Tutorial: Setting Up a Lambda Function with SQS Triggers
- SQS Lambda: 4 Failure Modes and How to Handle Them
- No DLQs
- SQS Lambda Visibility Timeout
- Partial Failures
- SQS Over-scaling
- SQS Overpulling

SQS Lambda Benefits and Limitations
Running Lambda functions with SQS triggers can provide the following compelling benefits:
- Fewer moving parts – instead of using multiple services, such as Kinesis with SQS or SNS with SQS augmented by custom code, you can use one SQS queue to achieve the same behavior.
- Reduced cost – by replacing several services with one, you reduce ongoing cloud costs and also development, debugging, and maintenance time.
- Improved fault tolerance – in previous implementations, retries were complex to achieve. With SQS you have a built-in retry capability, with the ability to use Dead Letter Queues (DLQ) for improved resilience.
- Improved user experience – the simplicity and improved resilience of SQS with Lambda means less production faults, and faster debugging and recovery when errors happen.
You should also note a important limitations of using SQS with Lambda:
- Visibility timeouts – once a Lambda function finishes running, messages are deleted. You must ensure you set the visibility timeout for queues and messages, to ensure that all associated tasks can be finished. Otherwise, messages may reappear in the queue and trigger another Lambda invocation before they are processed. Learn more in our detailed guide to serverless timeouts.
- SQS triggers come at a cost – Lambda long-polls SQS queues, then triggers the Lambda function when messages appear. When Lambda makes SQS API calls, they are charged at the regular price. Lambda may also add additional pollers as needed, which can incur additional cost.
Quick Tutorial: Setting Up a Lambda Function with SQS Triggers
This is abbreviated from the full tutorial by Adrian Hornsby. It will show you how to set up your first Lambda function with an SQS trigger.
Step 1: Create SQS queue
In the AWS Console, navigate to Simple Queue Service, create a new SQS queue and name it TestMySQSLambda. Select the type Standard Queue and click Quick-Create Queue.
Step 2: Create IAM role
Navigate to Amazon Identity and Access Management (IAM), and add the following policy to your Lambda execution role, naming it SQSLambda:
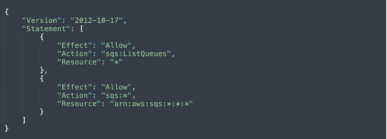
Step 3: Create a basic Lambda function
In the AWS Console, navigate to AWS Lambda and create a new function named MySQSTriggerTest. Edit the function and add basic function code, something like the below.
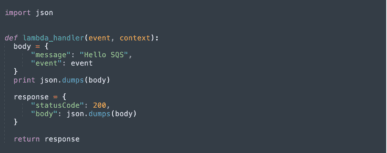
Under Execution Role, select the role we defined earlier, SQSLambda.
Step 4: Select SQS as a trigger
Under function configuration, in the Designer, scroll through the list of triggers on the left, and add the new SQS queue we created, TestMySQSLambda. Click Add and then Save.
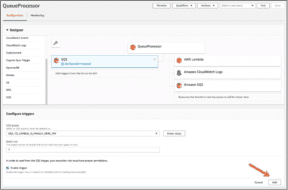
Source: AWS
{kind=link}
Step 5: Test your trigger by creating a test event
At the top right of the screen, select Configure test event. From the Event template drop down, select SQS. Keep the default event template. Click Create > Test.
You should see the message Execution result: succeeded. If so, congrats – you just sent a test SQS event which was captured and processed by your Lambda function!
SQS Lambda: 4 Failure Modes and How to Handle Them
Since Lambda added SQS as an event source, there has been a misconception that SQS is now a “push-based” service. This seems true from the perspective of your function because you no longer have to poll SQS yourself. However, SQS itself hasn’t changed – it is still very much a “poll-based” service. The difference is that the Lambda service is managing the pollers (and paying for them!) on your behalf.
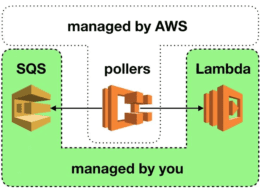
Although these managed pollers are invisible to us, they still introduce failure modes that affect our application. Indeed, others have written extensively about using SQS with Lambda – architecture patterns, use cases, and so on. I want to instead look at common failure modes we need to consider when using SQS with Lambda.
E-Book: Learn best practices for monitoring serverless applications
1. No DLQs
The most common mistake when using SQS and Lambda is not configuring a dead letter queue (DLQ). It would expose you to the poison message problem where an invalid message is retrieved repeatedly and causes the SQS function to err. These messages are incredibly difficult to track down and debug and were the reason for introducing DLQs to SQS.
As a rule of thumb, you should always configure a DLQ for every SQS queue.
2. SQS Lambda Visibility Timeout
Another common mistake is to not align the SQS visibility timeout (which can be overridden for each message) with the Lambda timeout. The SQS visibility timeout should always be greater than the Lambda function’s timeout.
Even if you expect a message should be processed within a few seconds, many AWS users would give SQS functions higher timeout “just in case”. This is understandable. You want to give the function the best chance to succeed, even if things occasionally take longer. Databases and other systems can experience performance problems under load. Even AWS SDK’s built-in retry and exponential backoff can be problematic at times too. The DynamoDB client for Node.js auto-retries up to 10 times with a max delay of 25.6s between retries (on the last retry)!
However, the default visibility timeout for an SQS queue is 30 seconds. If the SQS function has a higher timeout value then in-flight messages can be available again and processed more than once.
But it gets worse.
SQS functions receive messages in batches, and the messages are deleted from the queue only after the function completes successfully. It means that even if only one message was slow to process, the entire batch can elapse their visibility timeout and become available again in the queue.
3. Partial Failures
Because messages are deleted only after the SQS function completes successfully, it means batches always succeed or fail together. This makes handling partial failures an important consideration when using SQS and Lambda.
Here are some solutions for handling partial failures:
Use a batchSize of 1. This eliminates the problem of partial failures altogether but limits the throughput of how quickly you are able to process messages. In low traffic scenarios, it can be a simple and yet effective solution.
Ensure idempotency. This allows messages to be safely processed more than once. But in processing a message, if you have to update multiple systems then it’s difficult to achieve idempotency. You might find yourself reaching out for solutions such as saga patterns, which adds much complexity to the system.
My personal preference is to:
- Catch errors when processing each message.
- At the end of the batch, check if there are any partial failures.
- If no then do nothing. The poller would delete the messages from the queue for me.
- If there are partial failures, then:
- call the DeleteMessage API on the successful messages to manually delete them from the queue.
- throw an aggregate error with information about the message IDs that failed and their corresponding errors. This leaves the erroneous messages on the queue, so they can be processed again after the visibility timeout.
4. SQS Over-scaling
Lambda auto-scales the number of pollers based on traffic. This is great until the SQS function uses up too much of the available concurrent executions in the region. When the regional concurrency limit is breached, any Lambda invocations can be throttled. This includes functions that are serving user-facing API requests or processing payments, which would negatively impact the user experience.
This is an undesirable scenario because SQS functions are usually less critical parts of a system. And yet, they are capable of taking down other more critical components.
Fortunately, there are mitigation strategies you can adopt.
Increase the concurrency limit to give you more headroom for spikes. This is by far the simplest solution, but it’s not bullet-proof. If a surge of 1000 msg/s won’t take you down, a surge of 2000 msg/s might. Still, your chances of survival have just gone up significantly with little effort.
Set reserved concurrency on the SQS function. Another simple solution, but exposes you to the SQS overpulling problem discussed below. That said, if there isn’t a huge difference between the reserved concurrency and the no. of pollers (you have no control of this) then this solution would likely have minimal impact. In the worst case, at least it limits the blast radius to just the SQS function.
Implement backpressure control in front of the SQS queue. If you control the publisher then rate limit how many messages you publish to the queue. Otherwise, consider putting API Gateway in front of the SQS queue. This lets you leverage API Gateway’s built-in rate-limiting capability. If you have multiple publishers, then also consider using API Keys and Usage Plans. They give you fine control over the rate limits and quotas for each publisher. The drawback is that you have to introduce another moving part, and pay for API Gateway usage, and potentially have to write VTL code! If you use the Serverless framework, the serverless-apigateway-service-proxy plugin makes this a snap.
SQS Overpulling
To better understand this particular problem, you should read this and this article by Zac Charles. The heart of the problem is that Lambda scales the number of pollers irrespective of the reserved concurrency on the SQS function.
When there are more pollers than concurrent executions of the SQS function then invocation requests (from the poller to the SQS function) can be throttled. The messages in the throttled requests go back to the queue after the visibility timeout. This can happen to the same messages multiple times. If you have a DLQ (and you should) configured then in unlikely events messages can end up there without ever being processed.
Conclusion – SQS and Lambda
So that’s it, a rundown of the common failure modes you should consider when using SQS with Lambda. This is not an exhaustive list, and if I have missed some common failure modes please let us know in the comments.
One thing I would like you to take away from this post is that, even when AWS is autoscaling our SQS functions and their pollers, we still have to understand the scalability needs of our own systems. And equally, we need to understand the failure scenarios and how we can best mitigate their impact on our users. Embrace your curiosity and ask “I wonder what would happen to my system if X happens”. The overhead of running these learning experiments in AWS is very low, and the reward is immense.
Related content: Read our guide to serverless testing.