










Many clients have asked me, “When do I use AWS DynamoDB streams vs Kinesis?” It’s a great question, since both services are very similar, especially when you process their records with Lambda functions.
So let’s break it down and look at the key differences between Kinesis and DynamoDB streams.

AWS Kinesis Streams
When it comes to streaming and processing real-time events on AWS, Kinesis is the de facto solution in AWS.
You have a lot of flexibility in terms of how you can process the data. You can subscribe Lambda functions to a stream to process events in real-time. If you want to ship the data to Amazon ElasticSearch or S3, you can also connect the stream to a Firehose Delivery Stream. Firehose would manage the batching and delivery of the data for you without you having to write any custom code. If you want to run more complex queries over these data, you can also add Athena to the mix. You can also create Kinesis Analytics apps to filter and aggregate the data in real-time. You can even use Kinesis Analytics to fan out the source Kinesis stream too!
You scale a Kinesis stream with the number of shards. There is no upper limit on how many shards you can have in a stream. It’s possible to have thousands of shards for large scale applications. Netflix, for instance, used Kinesis to ingest VPC flow logs at a massive scale. Of all the AWS services out there, Kinesis is perhaps one of the most scalable.
Interestingly, there is also a 1-to-1 mapping between the number of shards and the number of concurrent executions of a subscribed Lambda function. This means you can precisely control the concurrency of the processing function with the number of shards. Which is very handy when you need to integrate with third-party systems that are not as scalable as you. It allows you to implement a flexible rate-limiting system to suit your needs.
On the other hand, there is no built-in auto-scaling mechanism. You can, however, build a custom solution using Lambda functions and the built-in CloudWatch metrics.
Finally, the default data retention is 24 hours, but you can extend it to up to 7 days at extra cost. This means when you subscribe a new Lambda function to the stream, it can have access to data for the previous 7 days, w. Which is useful for bootstrapping a new service with some data, more on this in a separate post.

AWS DynamoDB Streams
Compared with Kinesis Streams, DynamoDB streams are mainly used with Lambda. There is no direct integration with Kinesis Firehose or Kinesis Analytics.
In terms of data retention, you are also limited to the default 24 hours. There is no option to extend this any further.
From an the operational point of view, DynamoDB Streams also differs in that it auto-scales the number of shards based on traffic. That is if you enable any of the available auto-scaling options on the DynamoDB table. The number of shards in a DynamoDB stream is tied to the number of partitions in the table.
DynamoDB auto-scales the number of partitions for:
- on-demand tables
- provisioned capacity tables with auto-scaling enabled
The number of shards in the corresponding DynamoDB streams would auto-scale as well. This is a double-edged sword. Because there is still a 1-to-1 relationship between the number of shards in the stream and the number of concurrent executions of a subscriber function. It means you no longer have precise control of the concurrency of its subscriber Lambda functions. In return, you don’t need to build a custom auto-scaling solution.
AWS DynamoDB Streams’s pricing model is also slightly different from Kinesis Streams. Whereas Kinesis charges you based on shard hours as well as request count, DynamoDB Streams only charges for the number of read requests. Interestingly, when processing DynamoDB Streams events with Lambda, the read requests are free! Of course, you still have to pay for the read and write throughput units for the table itself.
One important limitation of DynamoDB Streams is that a stream only has events related to the entities in the table. And the events are not modeled as domain events from your domain – e.g. UserCreated, UserProfileUpdated. Instead, they are domain events for DynamoDB – INSERT, MODIFY, and REMOVE. I find this to be a constant cognitive dissonance when working with DynamoDB Streams.

Kinesis vs DynamoDB Streams
So, in summary, these are the key differences between Kinesis and DynamoDB Streams:
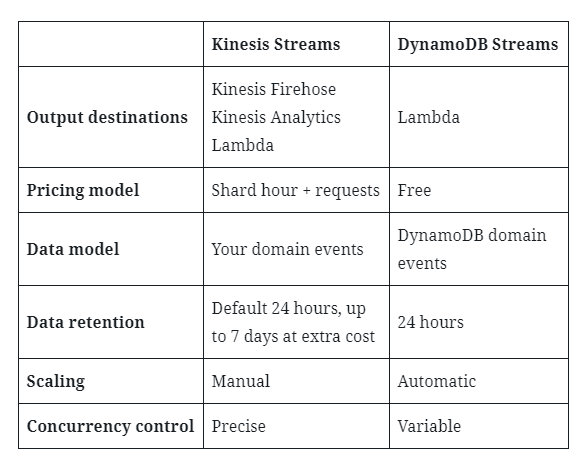
Understanding these technical differences is important for choosing the right service for your workload. However, I think the best reason to use DynamoDB Streams is the fact that it can remove many distributed transactions from your system.
Let me explain.

No distributed transactions, no problem!
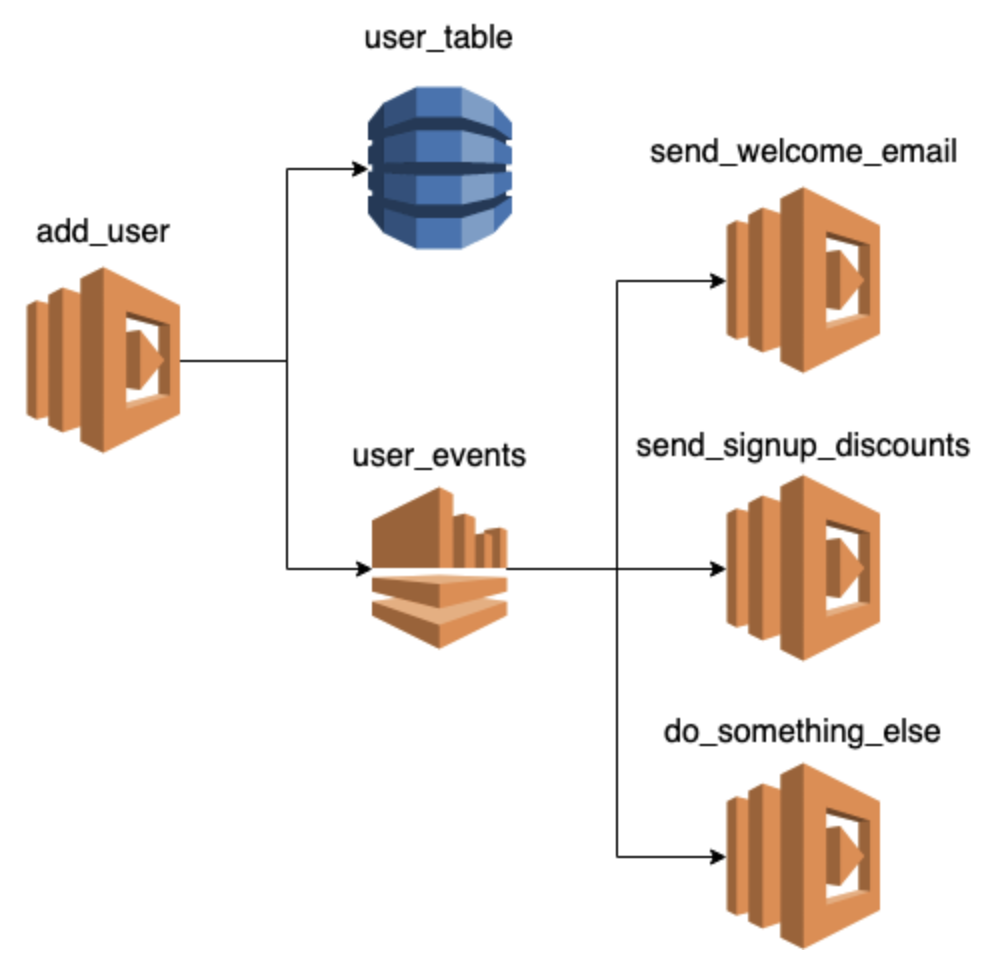
Imagine the scenario. A Lambda functions adds a new user to the user_table in DynamoDB and then publishes a UserCreated domain event to the user_events Kinesis stream. This seems innocent enough. But, whenever you have to update the state of two separate systems in synchrony, you are dealing with a distributed transaction.
Say, if the write to the Kinesis stream fails, should you roll back the insert to DynamoDB too? Do you bring out the big guns and implement the Saga pattern here? If you don’t, then various systems are going to be out-of-synch! For example, the user might not receive his/her welcome email, or new sign-up discount codes, or any number of things that should happen after a new user joins.
It’s great that we have separated these responsibilities into multiple functions. And we do these operations outside of the critical path so our add_user function can respond to the user promptly. But, we still have to contend with all the complexities of distributed transactions!
We can remove the distributed transaction by using DynamoDB Streams instead of publishing to another Kinesis stream from the add_user function.
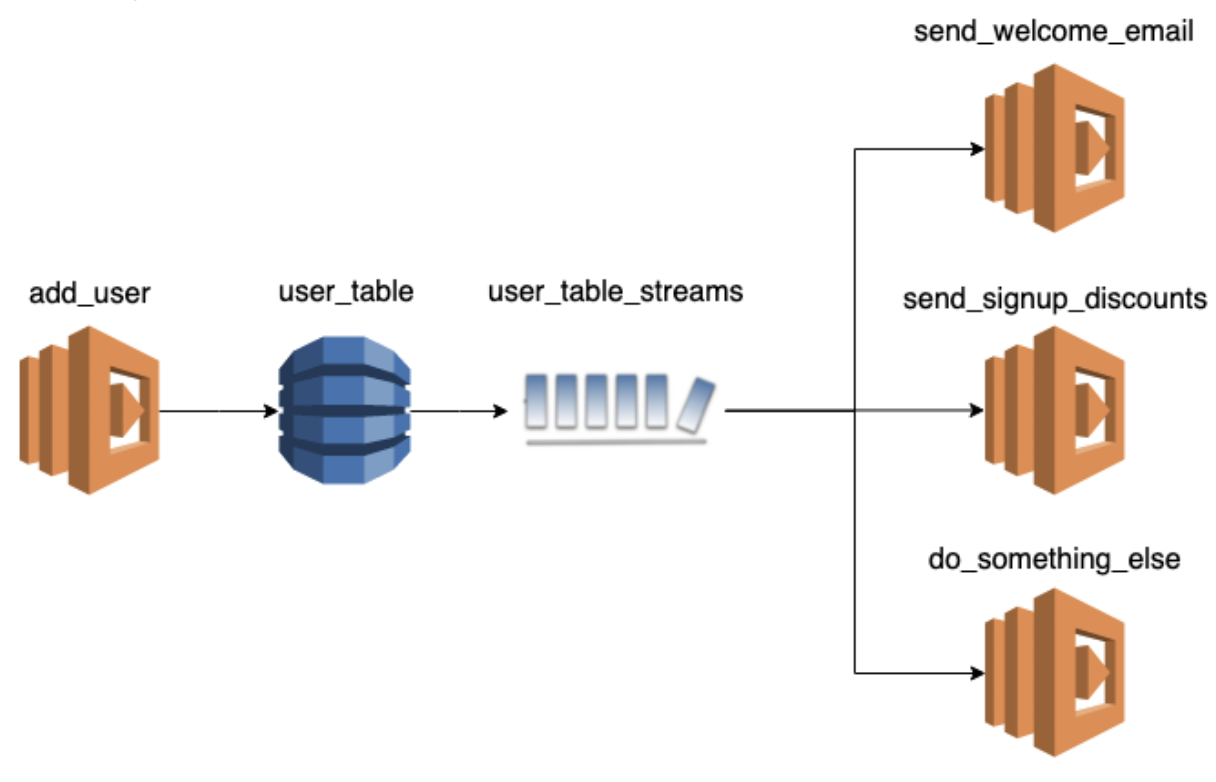
And that is the most compelling reason I have found for using AWS DynamoDB Streams in place of Kinesis Streams. Despite Kinesis Streams being arguably the better option for streaming events in realtime in general.