
- Guide Content
AWS Lambda and Serverless: An Introduction
What Is AWS Lambda?
AWS Lambda is a serverless compute service that permits you to run code without controlling or provisioning servers. Lambda uses highly available, elastic infrastructure to run your code. It carries out compute resources-administration tasks, such as automatic scaling and capacity provisioning, operating system and server maintenance. Lambda can run code for almost any form of backend or application service.
In a serverless model, code needs to be organized into functions. Lambda only runs your functions when necessary. It scales automatically, varying from several requests a day through to thousands a second. You only pay for the compute time you use—you won’t be charged when code is not run.
Lambda can run your functions when triggered by events from different AWS services. You can also utilize your Lambda function via the Lambda API.
This is part of an extensive series of guides about [microservices].
In this article
How Does AWS Lambda Work?
The following are several key principles to help you become familiar with AWS Lambda.
AWS Lambda components:
- Lambda functions—standalone functions invoked by the AWS Lambda engine, and terminated when they finish their work.
- Packaging functions—responsible for compressing Lambda functions, including their dependencies, and transferring them to AWS. The function must first be zipped and uploaded to an S3 bucket.
AWS Lambda execution model:
- Container—an operational unit that contains a Lambda function, and makes use of AWS-managed resources to run the function
- Instances—containers are immutable, meaning you cannot use them after they terminate. To allow for on-demand usage, instances—or replicas—of the container, are created by AWS Lambda.
- Stateless functions—each Lambda function is optimized and controlled by AWS and typically invoked once for each container instantiation.
- Events—requests that are served by one instance of a Lambda function. Events typically stream from other parts of the Amazon ecosystem—for example from databases like DynamoDB, CloudWatch events, or changes to files on S3—and trigger a Lambda function which processes the data in the event.
Supported Languages, Specs and Limitations
Here are the basic technical specifications of the AWS Lambda runtime engine:
- Lambda’s supports the following runtimes: Python: 3.7, 3.6, and 2.7, Java 8, Go 1.x, .NET Core: 1.0.1 and 2.1, Node.js: v10.15 and v8.10, Ruby 2.5, and Rust. Learn more in our guide to Lambda supported languages
- Function containers use a 64-bit Amazon Linux AMI
- CPU power of the function container is determined in relation to memory capacity. You may increase or decrease CPU resources by adding or removing memory. A container may be scaled up to 10 GB of memory and 6 vCPUs.
- A Lambda function may run for up to 15 minutes (this is called the Lambda timeout), meaning Lambda is not suited to long-running processes
- The /tmp directory acts as ephemeral disk space—it is cleaned after every invocation.
- Uncompressed function packages are restricted to 250MB. Compressed function packages are restricted to 50MB
Learn how to use AWS Lambda with different programming languages and frameworks:
- AWS Lambda with Kotlin
- AWS Lambda with Python
- AWS Lambda with NodeJS
- AWS Lambda with Java
- AWS Lambda with BOTO3
Learn more in our detailed guide to AWS Lambda limits
What Is Provisioned Concurrency?
If you are attempting to use Lambda for a use case that is latency-sensitive, cold starts are likely to be your main concern. A cold start is the time required for a Lambda function container to start up, before it can start serving function invocations. During that time, the function is not accessible and users may experience slowdown or service failure.
AWS is aware of the cold start issue and has developed the Provisioned Concurrency mechanism to address it. With Provisioned Concurrency, Lambda containers are pre-warmed to serve a predetermined level of concurrency.
For example, if you anticipate you’ll need to serve 100 concurrent requests to a function at 8am every day, you can set Provisioned Concurrency to pre-launch 100 containers for that function at that time, and remove them when no longer needed.
Provisioned Concurrency allows functions to be available instantaneously, with no cold start delay, avoiding latency issues. Using the AWS Management Console, command line or API, developers can configure any existing or new function to use Provisioned Concurrency.
You can use Application Auto Scaling for automatically configuring the needed concurrency for the functions. You can also make use of the AWS Serverless Application Model (SAM) and SAM CLI to check, manage and deploy serverless applications which employ Provisioned Concurrency. Also, Provisioned Concurrency is integrated with AWS CodeDeploy for complete automated and managed software deployments.
Learn more in our detailed guide to AWS Lambda concurrency
AWS Lambda Pricing
AWS Lambda functions are generally charged according to two factors—the amount of requests carried out, and the work undertaken throughout those requests.
Free tier
Initially, AWS Lambda provides a free usage tier with 1 million free requests a month and 400,000 GB-seconds of compute.
Billing for usage
When you run through free tier usage, requests are priced at a flat rate of $0.20 for each 1 million requests. Usage time is charged according to GB-seconds. In the US-East region, the cost is $0.0000166667 per GB-second.
AWS prices usage time in blocks of 100 milliseconds. It is important to realize that while you are only charged for the actual time the function executes, you are charged for the full memory and compute resources of the container, even if the function does not fully utilize them. The greater the size of memory assigned to a function, the greater every 100 millisecond block will cost.
Data transfer costs
You are charged for any data transfer from beyond the region of your function (for instance from other AWS services or from the internet) at standard AWS transfer rates.
Provisioned concurrency costs
You could permit Provisioned Concurrency for the Lambda functions to better manage the performance of serverless applications and avoid cold starts. You pay according to how much concurrency you configure, and for the amount of time functions are available at the required level of concurrency.
Provisioned Concurrency is calculated from the moment you permit it on your functions until you disable it, rounded up to the closest five-minute mark. The price is calculated according to the amount of concurrency you configure on it and the quantity of memory you assign to your function.
Learn more in our detailed guide to AWS Lambda cost
What Are AWS Lambda Applications?
An AWS Lambda application comprises event sources, Lambda functions and other tools that work in unison to carry out tasks. Structuring your AWS Lambda functions as applications ensures that your Lambda projects are portable. This lets you integrate them with other developer tools, including AWS CodePipeline, the AWS Serverless Application Model command line interface (SAM CLI) and AWS CodeBuild.
Serverless Application Repository
This offers a variety of ready-made samples and production-ready Lambda applications, which you may deploy in an account. You can use these applications as a template to get a head start on your projects. You can also submit projects you created to the repository.
Automating Deployment with CloudFormation
You can employ AWS CloudFormation or other resources to define your application’s components as a single package, which may be managed and deployed as a unified resource.
AWS CloudFormation lets you develop a template that specifies your application’s resources and allows you to control the application as a stack. You can then safely modify or add resources in your application stack. If a portion of an update fails, AWS CloudFormation automatically goes back to the earlier configuration.
You can use AWS CloudFormation parameters to specify conditions for your template, enabling you to run an application on several environments with the same template. If you use AWS SAM, you can manage CloudFormation templates for Lambda applications with simplified commands that focus on Lambda development needs.
Management via CLI
The SAM CLI and AWS CLI are command-line systems used to manage Lambda application stacks. The AWS CLI can be used alongside the CloudFormation API to simplify high-level tasks, like updating CloudFormation templates and uploading deployment packages. The AWS SAM CLI also offers other functionalities, such as testing locally and validating templates.
To learn more about AWS SAM, read our guide
Integrating with Git repositories
When developing an application, you can establish its Git repository via an AWS CodeStar connection to GitHub or CodeCommit. CodeCommit lets you use the IAM console to control HTTP credentials and SSH keys for your user.
What Is AWS Lambda@Edge?
AWS Lambda@Edge is an add-on to AWS Lambda, which lets you deploy Lambda functions on all distributed AWS regions globally, rather than in one specific geographic area. While Lambda supports multiple programming languages, Lambda@Edge functions only support Node.js.
When a Lambda@Edge function is activated, it runs in the AWS region nearest to the area of the triggering event. This means that it runs as near as possible to the individual or machine making use of the application.
For instance, consider a user in Chicago who asks for certain information via an application using a serverless architecture. If the infrastructure of the serverless application is hosted via the use of AWS Lambda within the US-East-1 region (Virginia), the request must travel to the AWS center in Virginia, and the response will be transferred from there to Chicago.
However, if the application is hosted via AWS Lambda@Edge, then the request for information and the answer will just have to travel to and from the nearest AWS region (US-East-2) located in Ohio. This reduction in distance lowers latency, in comparison to regular AWS Lambda.
Learn more in our detailed guide to Lambda@Edge
Monitoring AWS Lambda: Key Metrics to Watch
Serverless applications are highly distributed, and it can be difficult to detect operational errors, identify their root cause and debug them. Here are a few core metrics you should watch to become aware of problems with Lambda functions, and get basic info to assist you when resolving the problem.
Duration
This metric calculates the time taken to execute a function, using milliseconds. As this metric calculates the whole operation (from start to finish), you may use it to measure performance, akin to latency metrics used in a traditional application.
Errors
This metric notes the amount of Lambda executions that ended up as an error. If you notice a rise in the error rate, you can look into this further by viewing your Lambda logs— which can show you the precise cause of the problem (for example, timeout, out-of-memory exception, or permissions error).
Throttles
AWS Lambda has a configurable concurrency limit—this is the maximum number of invocations that can be carried out at the same time for the same Lambda function.
This metric offers a count of the invocation tries that were throttled as they went over the concurrent execution restrictions. Keeping track of this metric may help you fine-tune concurrency limits to most accurately align with your Lambda workload. For instance, a great number of throttles may show that you should increase the limits of your concurrency to decrease the number of innovations that have failed.
ProvisionedConcurrencyUtilization
Monitoring provisioned concurrency utilization lets you see when a function is effectively making use of its provisioned concurrency. A function that continuously hits its utilization limit and makes use of all its available provisioned concurrency could require additional concurrency. Alternatively, if utilization is continuously low, you could have overprovisioned the function, which may result in an increase of costs.
Learn more in our detailed guide to Lambda performance
AWS Lambda Challenges and Solutions
There are many benefits to serverless computing, but solutions like AWS Lambda also present important challenges you should be aware of.
Monitoring, Logging and Tracing
When it comes to monitoring and logging applications in Lambda, you cannot count on background daemons to continuously monitor a web server.
Lambda function code runs on ephemeral containers, which means that application logs cannot be persisted locally for later inspection.
Amazon provides partial solutions to these challenges:
- Monitoring—AWS CloudWatch can integrate with Lambda to offer runtime and simple performance metrics for Lambda functions.
- Logging—Lambda outputs every log to AWS CloudWatch Logs by default. However, it is not a platform created explicitly for serverless debugging, so it can be difficult to investigate Lambda logs to identify root causes and debug issues.
- Tracing—AWS offers a distributed tracing service called X-Ray, which is integrated with AWS Lambda.
Debugging
It can be hard to debug Lambda functions for several reasons:
- Logs from multiple distinct invocations are combined in AWS CloudWatch Logs. It is also difficult to make sense of logs from all executions in a time-ordered manner.
- The execution of a specific job or business rule is scattered over multiple message buffer systems and functions.
- Logs are similarly scattered in multiple locations, making it difficult to discover the root cause of issues in Lambda functions.
Avoiding Timeouts
A common problem with Lambda functions is unexpected timeouts. Here are a few ways to avoid functions timing out when you least expect it.
API Gateway-related timeouts
If your Lambda function is triggered through an API Gateway, yet you’re having timeouts and noticing a rise in your error counts, this could be due to the following: if “Use Default Timeout” is allowed in your API Gateway Integration Request settings (i.e. is 29 seconds) and the Lambda function’s timeout setting is greater than 29 sections.
All you should do is disable the setting or lessen the timeout of your Lambda function to ≤ 29 seconds. If you decide to disable the setting, make sure you redeploy your API.
Low memory timeouts
Not all Lambda invocations consume an identical quantity of memory, which is why you must set an accurate size of memory for the function.
For instance, if MemorySetInMB for a specific invocation is lower than MemoryUsedInMB, the result is a timeout. This indicates that your script used more memory than it was permitted to.
Define CloudWatch alerts to identify invocations where MemorySetInMB is close to MemoryUsedInMB, and increase the allotted memory of the Lambda function.
VPC-related timeouts
AWS recommends that you maintain your lambda functions without a VPC, except if you have a solid reason for doing so. This is because if you place a Lambda function in a VPC, its internet connection is lost.
You can overcome this issue but it will demand some networking aptitude and permissions. You will need to deal with public/private subnets, Internet Gateways, NAT Gateways and VPCs.
Generally, if your function is inside a VPC, this won’t result in a timeout straight away. However, if you want your functions to send requests to the internet, including placing an API call to Firebase Cloud Messaging, you’ll run into problems. Requests will not have a transport path, and thus will not receive a response. Keep in mind that functions running in a VPC can only communicate with resources within that VPC.
Learn more in our detailed guide to Lambda timeouts
Improve Cold Start Performance
Provisioned Concurrency
Say you require a reliable function start time for a workload, Provisioned Concurrency is a suitable solution to see to the minimal possible latency. This feature makes sure your functions are kept warm and initialized and can react in double-digit milliseconds, in keeping with the scale provisioned. As distinct from on-demand Lambda functions, this runs the initialization and indicates that all the setup activities occur before invocation.
For instance, a function that has a Provisioned Concurrency of 5 has five execution environments ready before the invocations take place. In the period from initialization to invocation, an execution environment is prepped and ready.

Image Source: AWS
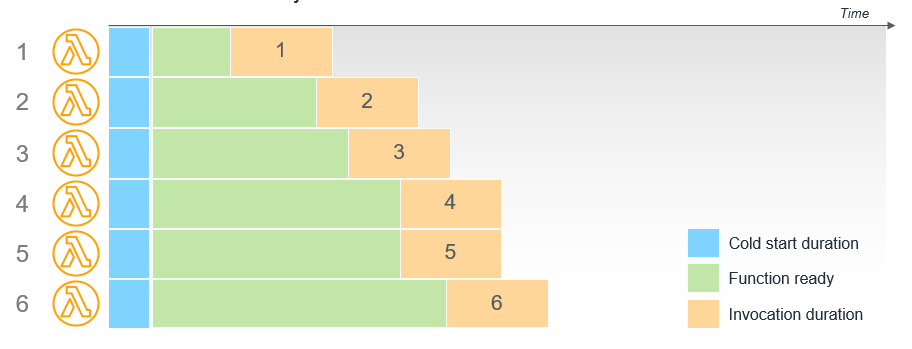{kind=link}
Functions with Provisioned Concurrency are distinct from on-demand functions in key ways:
- Initialization code doesn’t require optimization—this occurs prior to invocation, so extended initialization doesn’t affect latency. If you use runtimes that generally take more time to initialize, such as Java, the performance of such might benefit from the use of Provisioned Concurrency
- Initialization code you run more often than the overall number of invocations—Lambda is highly available, so for each unit of Provisioned Concurrency, there are at least 2 execution environments created in distinct Availability Zones. This is to make sure that the code is accessible if a service disruption takes place. As environments are utilized with load balancing, Lambda over-provisions environments to make sure they are accessible. You don’t have to control this process. If your code initializer executes logging, you could view other log files whenever the code is running, despite the fact that the central handler isn’t invoked.
- Provisioned Concurrency may not be utilized with the $LATEST version—this attribute may only be employed with aliases of a function and published versions. If you notice cold starts in relation to functions configured for use of Provisioned Concurrency, you could be invoking the $LATEST version, rather than the version of alias with Provisioned Concurrency configured.
Avoid HTTP/HTTPS Calls Inside Lambda
HTTPS calls initiate cold starts in serverless applications, thus increasing a function’s invoking time. In simple terms, when an HTTPS call occurs, security-related calls and SSL (Secure Socket Layer) handshake take place simultaneously. These tasks are increasingly limited by CPU power prompting a cold start.
AWS SDK will always ship with a bunch of HTTP client libraries, which you can use to place an SDK call. Every library can carry out connection pooling, yet, Lambda functions can take care of multiple requests at the same time, while serving just one request at a time. This means that most HTTP connections can’t be used. As such, you must only use the HTTP client from AWS SDK.
Continuous Monitoring Using Log Data
Each second that is not used in a cold start increases the cost—notwithstanding the non-productive computing time, you will pay a large amount. If you can use log data in different serverless monitoring applications, however, you are likely to stay clear of trouble.
You can assess the performance of your Lambda function through use of instrumentation tools such as AWS X-Ray and Gatling. They track performance effectively and point out areas of improvement, which minimizes cold starts. Monitoring Lambda functions has its difficulties, however, which may be addressed by using CloudWatch or other third-party log management tools to measure various metrics such as Performance, Invocation, and Concurrency.
Reduce the Number of Packages
The largest effect of AWS Lambda cold start times is the initialization times whereby the package is initially loaded, but not the package’s size.
The more packages you use, the more time it takes the container to load them. Tools such as Serverless Plugin Optimize and Browserify might help decrease the number of packages.
Learn more in our detailed guide to Lambda cold start performance
AWS Lambda Observability, Debugging, and Performance Made Easy with Lumigo
Lumigo is a serverless monitoring platform that lets developers effortlessly find Lambda cold starts, understand their impact, and fix them.
Lumigo can help you:
- Solve cold starts – easily obtain cold start-related metrics for your Lambda functions, including cold start %, average cold duration, and enabled provisioned concurrency. Generate real-time alerts on cold starts, so you’ll know instantly when a function is under-provisioned and can adjust provisioned concurrency.
- Find and fix issues in seconds with visual debugging – Lumigo builds a virtual stack trace of all services participating in the transaction. Everything is displayed in a visual map that can be searched and filtered.
- Automatic distributed tracing – with one click and no manual code changes, Lumigo visualizes your entire environment, including your Lambdas, other AWS services, and every API call and external SaaS service.
- Identify and remove performance bottlenecks – see the end-to-end execution duration of each service, and which services run sequentially and in parallel. Lumigo automatically identifies your worst latency offenders, including AWS Lambda cold starts.
- Serverless-specific smart alerts – using machine learning, Lumigo’s predictive analytics identifies and alerts on issues before they impact application performance or costs, including alerts about AWS Lambda cold starts.
Get a free account with Lumigo resolve Lambda issues in seconds
See Additional Guides on Key Microservices Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of microservices.
Application Mapping
Authored by CodeSee
- Bring visibility to your codebase
- What Is Software Mapping, 4 Types of Dependencies and How to Manage Them
- Why Code Dependencies Matter—and How to Identify and Resolve Them
Aws Lambda Deployment
Authored by Lumigo
Microservices Monitoring
Authored by Lumigo