










Artificial intelligence is reshaping industries at an unprecedented pace. AI has found its way into almost every vertical, from writing code to diagnosing illnesses, promising efficiency and innovation. The idea of an AI Copilot—a tool that acts as your assistant to tackle complex tasks—is particularly exciting.
In our space, observability, the possibilities seemed endless. We asked ourselves how AI could simplify troubleshooting in microservices. Imagine if developers could instantly pinpoint the root cause of an error and further speed up troubleshooting. We envisioned a Copilot that acted as a senior developer, helping to democratize troubleshooting across large teams of developers of all skill sets.
With these aspirations, we embarked on our journey to build Lumigo’s AI Copilot. Along the way, we learned a lot and have distilled some of the highlights into a guide for any developer trying to build an AI Copilot that can provide real value to users.
Embrace naïvety
Our initial approach, which we call the “naïve approach,” was a critical learning phase. At this stage, we simply fed the model data and asked it to solve a problem—for example, diagnosing the root cause of an error using payload data. Unsurprisingly, the results were inconsistent and often unsatisfactory. Occasionally, the model would guess correctly, but the accuracy was low.
This exploration was a necessary first step. It helped identify gaps in the model’s understanding of our product and provided a baseline for improvement. The naïve approach is your starting point, not your destination.
Build your playbook
Before we started improving our Copilot’s quality, we knew we needed a playbook to help us guide decision-making. Our team knows the ins and outs of observability, so we were well-positioned to teach our model. The first step was documenting that playbook. To do so, we considered the kinds of problems we solve for our users every day without AI. This served as a blueprint for helping us guide the LLM to more accurate results throughout the process.
Improve quality through prompt engineering.
Once the gaps in the naïve approach became clear and we’d created our playbook, our next step was to refine the model’s performance through prompt engineering. Prompt engineering allows you to guide the model’s behavior and improve its responses without altering the underlying model. Key components of prompt engineering include:
- Guidance: Crafting specific instructions and prompts to direct the model’s output.
- Context: Trimming unnecessary data and providing clear, concise input to the model.
At Lumigo, we experimented with several prompt-engineering techniques. We’ll go over each and share some examples.
Few-Shot Prompting
Few-shot prompting involves showing the model a few examples of a task. For instance, in a translation task, you might provide the model with two examples of English sentences translated into French, allowing the model to infer the task and correctly translate new English sentences into French.
Chain-of-Thought (CoT) Prompting
Chain-of-thought prompting encourages step-by-step reasoning. For example, for a math problem, you could prompt, “Let’s think through this step-by-step: If Jane has three apples and buys five more, how many apples does she have now?” prompting the model to reason its way to the answer.
Tree-of-Thought (ToT) Prompting
Tree-of-thought prompting explores multiple solutions simultaneously, like dividing a problem among team members and consolidating their findings. While theoretically appealing, this method proved expensive and less impactful for our use case, offering no significant improvement over CoT prompting.
Here’s an example. For a logic puzzle, you might prompt the model with “Consider possible answers and evaluate each: If X could be true, what would that imply? Now consider if Y were true…” This approach helps the model examine various scenarios before arriving at a conclusion.
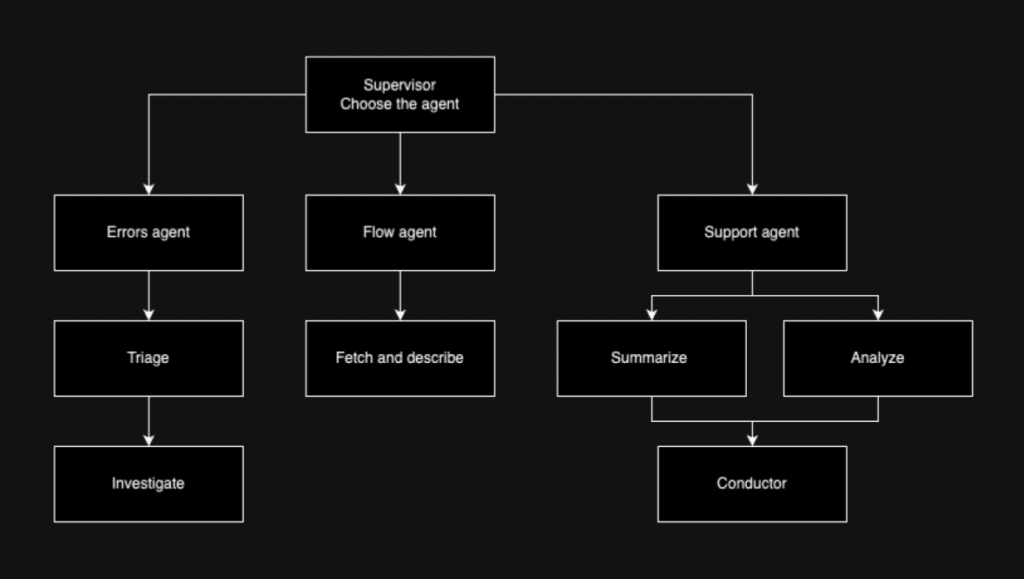
The Agent-Based Approach: Experts in Action
Our most effective strategy was what we call the “expert-based” or agent-based approach. This method involves dividing significant problems into smaller tasks and assigning specialized “expert” agents to handle each task. For instance, using Lumigo’s Copilot as an example, one agent might focus on database-related issues while another addresses networking errors.
By tying chain-of-thought prompts together and assigning them to agents, we optimized both context and running times. This approach improved accuracy by over 70% and offered maximum scalability. As new use cases emerged, we simply added more agents to the system, allowing for significant scale.
Continuous Improvement: Evaluation and Feedback
Building a Copilot is an ongoing effort. Continuous improvement requires robust evaluation and feedback mechanisms. Evaluation pipelines help track your model’s performance over time. At Lumigo, we’ve used tools like DeepEval and LangSmith to measure:
- Relevance: How well the response aligns with the query.
- Accuracy: Whether the response is more or less accurate.
- Custom Metrics: Metrics tailored to specific use cases.
These tools allow us to compare different model versions and identify areas for improvement.
The Key to Evaluation and Understanding is Building a Dataset
Start with a small dataset and expand it over time. The more extensive and more diverse your dataset, the better your model will perform. Regularly updating the dataset with user feedback ensures the Copilot evolves alongside your customers’ needs.
Feedback Loops
It is critical to incorporate user feedback. During our beta phase, we encouraged users to share their experiences directly through Copilot’s chat interface. Responses were tagged and analyzed, providing invaluable data to refine the model. We also worked closely with our customer beta to gather quantitative and qualitative feedback throughout the process.
Start building your Copilot.
Building an AI Copilot is a journey that starts with naïvety and evolves into a sophisticated system powered by domain expertise, prompt engineering, iterative improvement, and evaluation. At Lumigo, our Copilot’s beta version has already achieved 80% accuracy. To get started:
- Start simple and learn from your naïve approach.
- Use prompt engineering to refine model responses.
- Embrace agent-based systems for scalability and accuracy.
- Continuously evaluate and improve using feedback and metrics.
The road to an effective AI Copilot is challenging but easy to navigate with the right team and tools. With persistence and the right strategies, you can build a tool that truly empowers your users.
Watch the webinar
Experience Lumigo Copilot Beta
Lumigo Copilot builds on our proven expertise in blazing-fast root cause analysis, introducing a transformative experience that takes developers from alert to root cause to auto-remediation in minutes. At the core of this innovation lies Lumigo’s unique capability to correlate request and response payloads with traces, logs, and metrics—delivering unmatched speed and precision in identifying and resolving issues.