We had the opening keynote by Adam Selipsky. If you missed the live stream, you can watch it on YouTube here.
Unsurprisingly, so much of the keynote was about AI.
Amazon Q
Here’s the official announcement.
Amazon Q was the biggest announcement from the keynote. It’s AWS’s answer to ChatGPT and it comes in the AWS console, AWS documentation pages as well as in your IDE (through the VS Code plugin, AWS Toolkit).
It’s trained on AWS documentation, which ChatGPT is no longer able to crawl thanks to Amazon’s ai.txt. So it should be able to give more up-to-date answers than ChatGPT.
For enterprise users, you can give Q access to your data and create specialised chatbots for your application.
From my limited testing so far, it’s been fairly hit-and-miss. It’s OK at dishing out facts but I wouldn’t trust its advice on best practices just yet.
I think the main differentiator is in data security. You are able to give Q access to data in your AWS environment and have fine-grained control over what it can access.
Besides being a chatbot, you can also use Q for coding.
For Java developers, Q Code Transformation helps you upgrade Java application to the latest runtime.
And Q can implement entire features for you, if you use it with CodeCatalyst.
These all sound pretty exciting.
But based on my experience with ChatGPT, CodeWhisperer, Copilot and my brief exposure to Q so far, I wouldn’t trust for anything important just yet.
Bedrock gets guardrails
Here’s the official announcement and feature page.
This looks very useful. Redact PII data, filter harmful content, and block certain topics (e.g. don’t give medical or financial advice). Applicable across all the foundational models that you want to work with.
Bedrock Knowledge Base is generally available
Here’s the official announcement.
Knowledge base is Bedrock’s version of OpenAI’s GPTs. A managed Retrieval Augmented Generation (RAG) to build customized chatbots.
You just need to point Bedrock to your data in S3 and it takes care of the whole process of ingesting the data into your vector database.
If you don’t have a vector database, Bedrock will create an OpenSearch serverless vector store for you. But wait… doesn’t OpenSearch Serverless charge you a minimum of $700 per month?
Yeah… bring your own vector database 😉
Bedrock Agents is generally available
Here’s the official announcement.
This was announced back in July 2023. It lets you create autonomous agents and make it easier to create AI applications with Bedrock. Agents can take a user request, break it down to smaller tasks and carries them out.
S3 adds Express One Zone storage class
Here’s the official announcement.
This is a new bucket type that stores your data in a single Availability Zone.
It gives you single-digit millisecond latency and has the same 11 nines durability (so long that one availability zone doesn’t experience any catastrophe!).
The data in the bucket is accessible from other AZs in the same region.
In terms of pricing, the cost per million requests is $0.0025 per 1,000 requests. That’s a 50% discount on the $0.005 per 1,000 requests for S3 standard. But, at $0.16 per GB, it’s also much more expensive on the storage cost than the $0.023 per GB for S3 standard.
Perhaps, this is because data is stored on “purpose built hardware” (see launch blog) that co-locates storage with compute. That’s how they are able to achieve the significant performance improvements without sacrificing durability. But these probably aren’t the most cost efficient storage devices for large quantities of data.
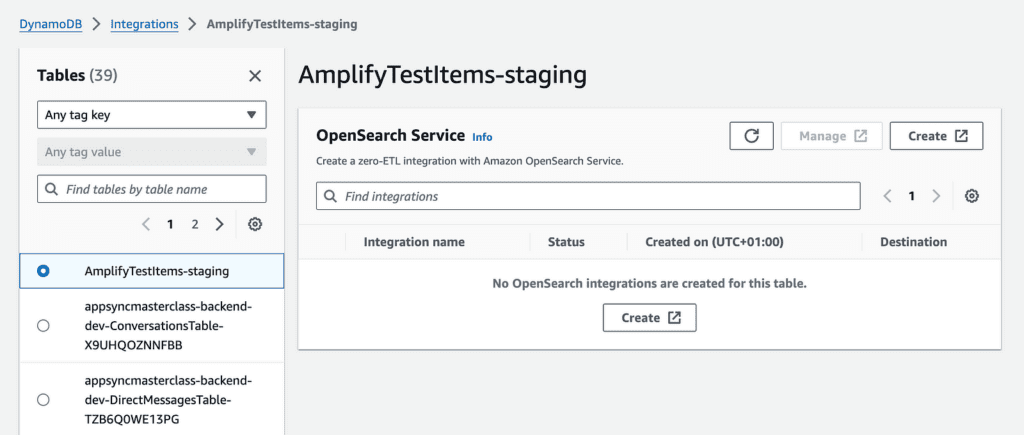
No-code integration for DynamoDB and OpenSearch
Here’s the official announcement.
AWS announced a number of new no-code integrations. The the DynamoDB to OpenSearch integration was the most exciting to me.
I’m somewhat disappointed that they didn’t add OpenSearch as an EventBridge Pipes target.
They also copped out slightly on the CloudFormation support for this…
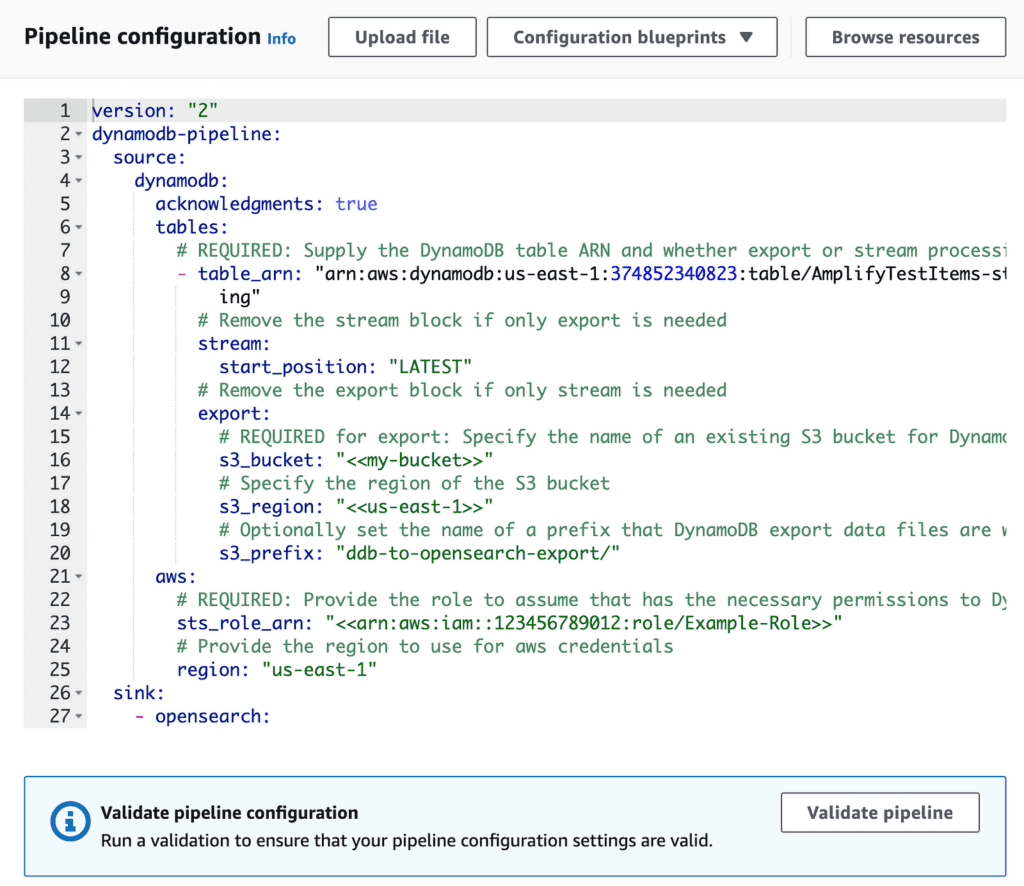
There’s a new AWS::OSIS::Pipeline resource type, which accepts a YAML configuration body. But the YAML format doesn’t seem to be referenced or documented anywhere. Not even Amazon Q knew how to configure this.

If, like me, you want to use IaC for everything, then your best bet is to use the DynamoDB console and create a new OpenSearch ingestion.
As you go through the wizard, you will find the YAML format you need.