










Serverless is an incredible paradigm, but performance tuning sometimes feels like a black box. You have no control over the infrastructure, but that doesn’t mean you can’t optimize.
In this post, let’s look at five ways to take serverless performance to the next level.
1. Right-size Lambda functions
With Lambda, you have one lever to control the power and cost of your functions — its memory setting.
Both CPU and network bandwidth are allocated proportionally to a function’s memory allocation. But so does its cost per millisecond of execution time.
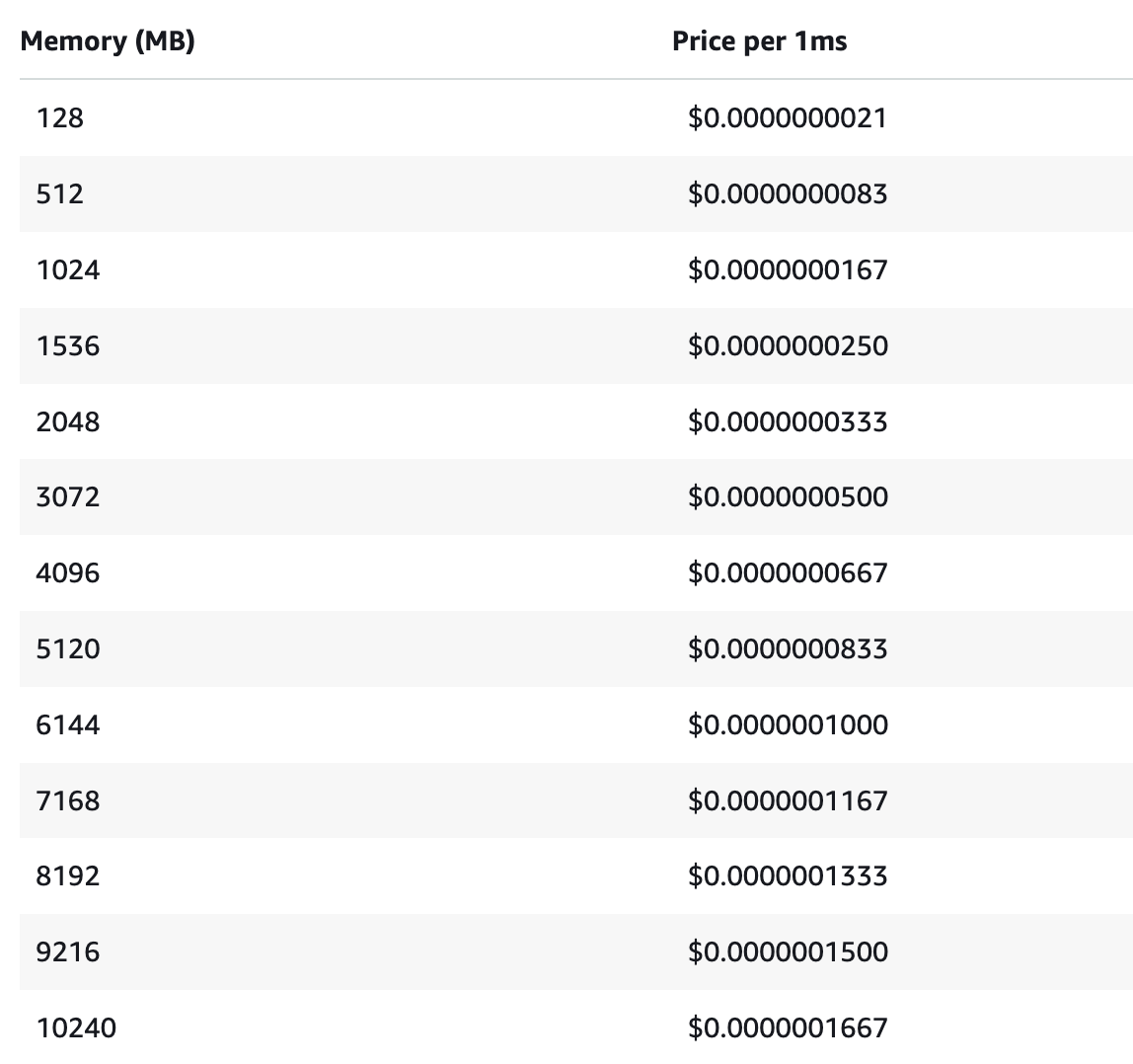
While it’s easy to throw more CPU at a function by giving it more memory, you must find a careful balance between performance and cost.
I often see teams using 128MB memory because they think, “Hey, it’s just an API call, it doesn’t need more!”. But the reality is, for most use cases, you should start at 512MB or even 1GB of memory.
Even if your application doesn’t use all the available memory, Operation System paging can kick in as you approach 60-70% utilization.
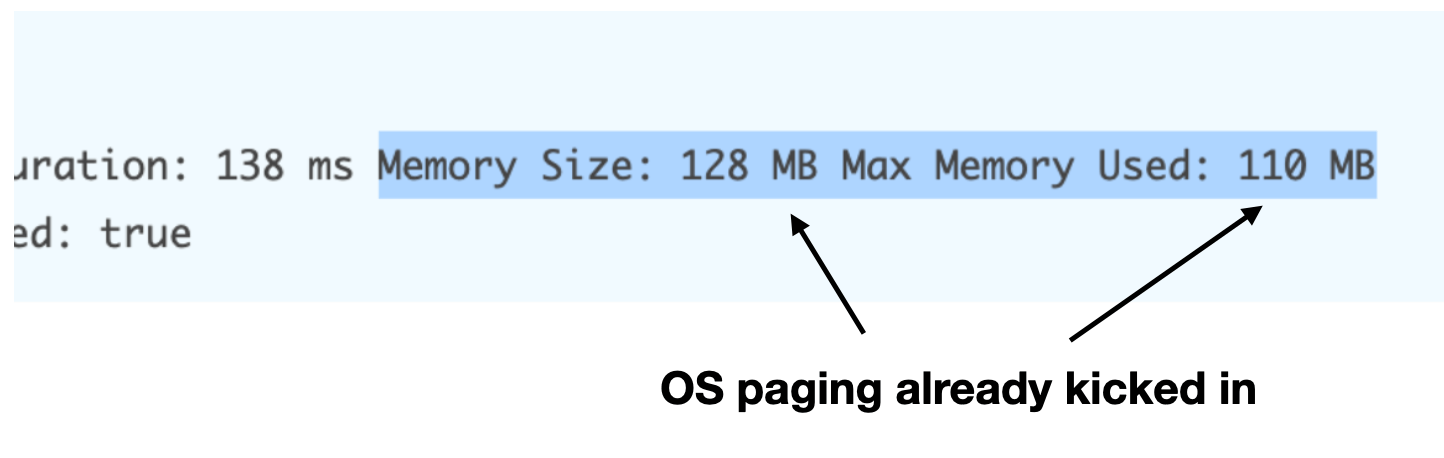
This has a huge performance cost and can be easily avoided!
Unfortunately, both CDK and SAM default to 128MB, and it’s up to you to pick a more sensible default.
Yes, picking a higher memory setting means paying more per ms of execution time. But giving the function more CPU makes it run faster, so you pay for a shorter execution time.
You can use the Lambda Powertuning Tool to help you find the optimal setting that gives you the biggest bang for your buck.
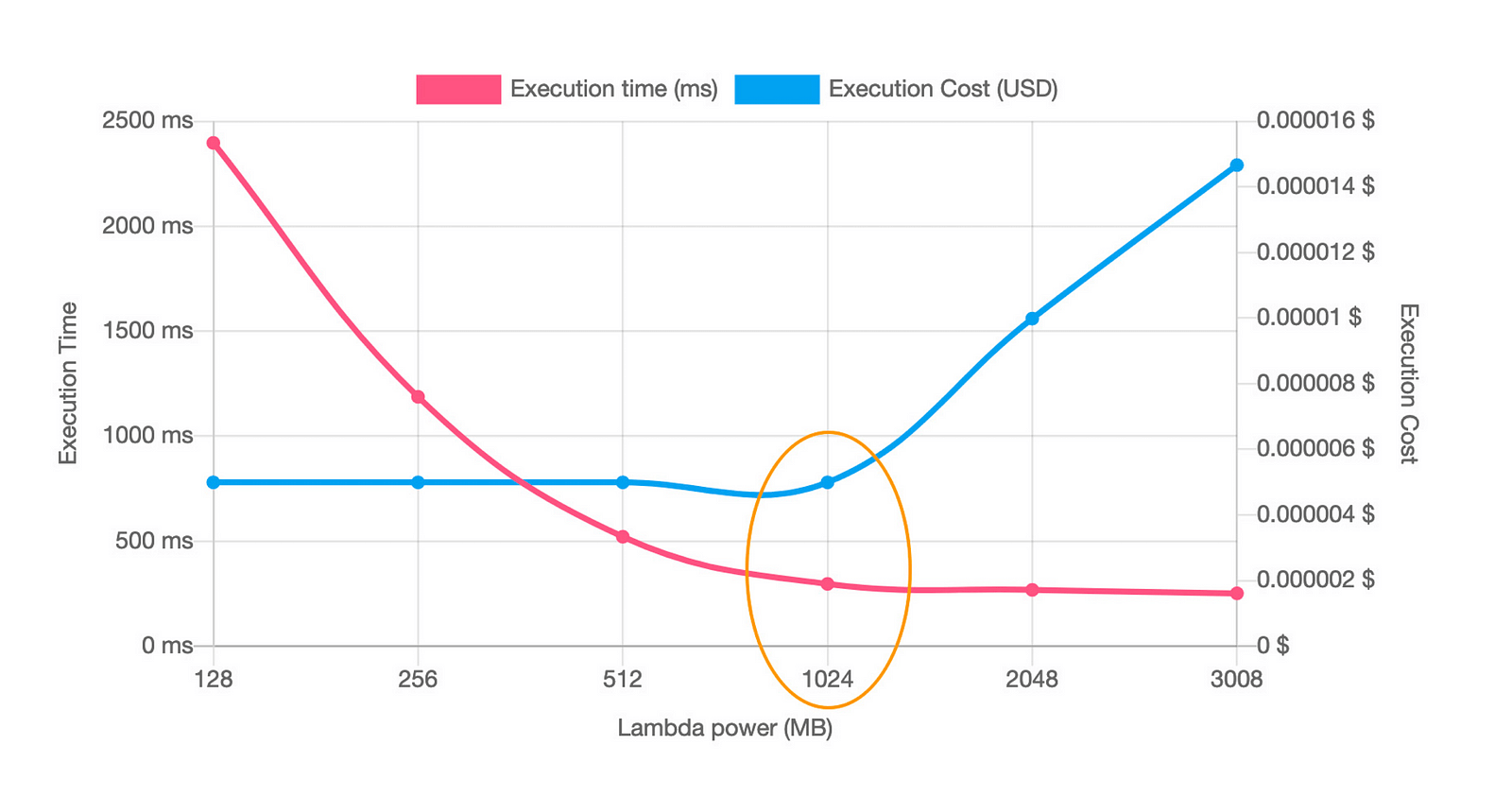
However, this still takes time and effort, and your time is valuable.
For most functions, it’s OK to overprovision a little and forget about it. Unless a function runs millions of times a month, there is likely no return on investment for optimising it.
When I look at my functions in Lumigo, I see that all have negligible costs and are not worth optimizing.
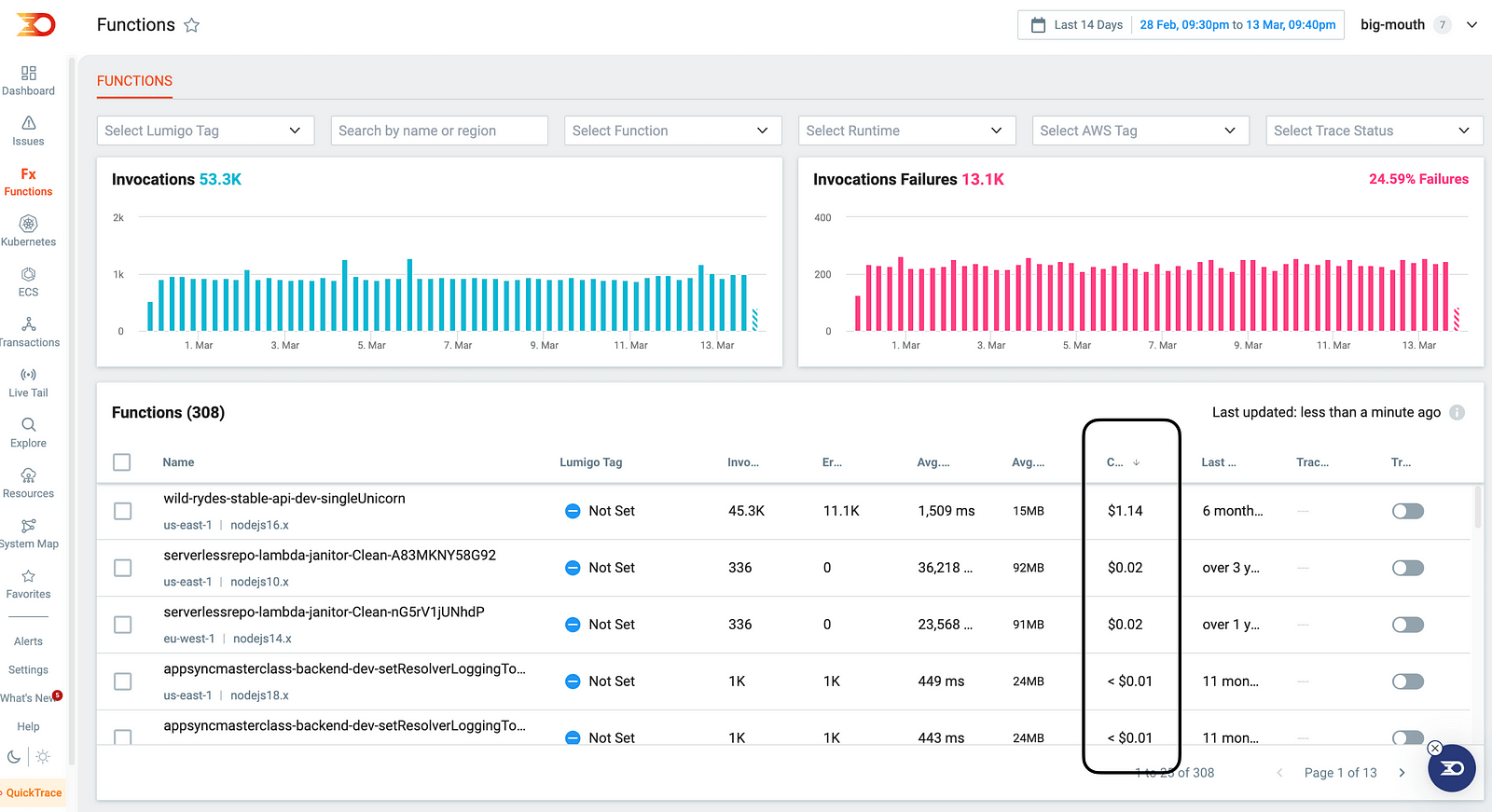
Another thing to remember is that, at 1.8 GB of memory, a Lambda function has an entire vCPU allocated. Above this level, it has access to more than one vCPU core. At 10,240 MB, it has six vCPUs available.
So, to take advantage of these higher memory settings, you must embrace parallelism.
2. Embrace Concurrency & Parallelism in Code
Every programming language has some support for concurrency and/or parallelism. These are related but ultimately distinct concepts.
Concurrency is about managing multiple things at once, but you can only do one of them at a time. Parallelism is actually doing those things simultaneously, all at the same time.
Node.js is still the most popular language on Lambda. The V8 engine runs on a single-threaded event loop, so it doesn’t support parallelism out of the box.
You can use child processes or the new worker threads capability to unlock parallel processing. However, this is only relevant for Lambda functions with more than 1.8GB of memory (and therefore, more than one vCPU).
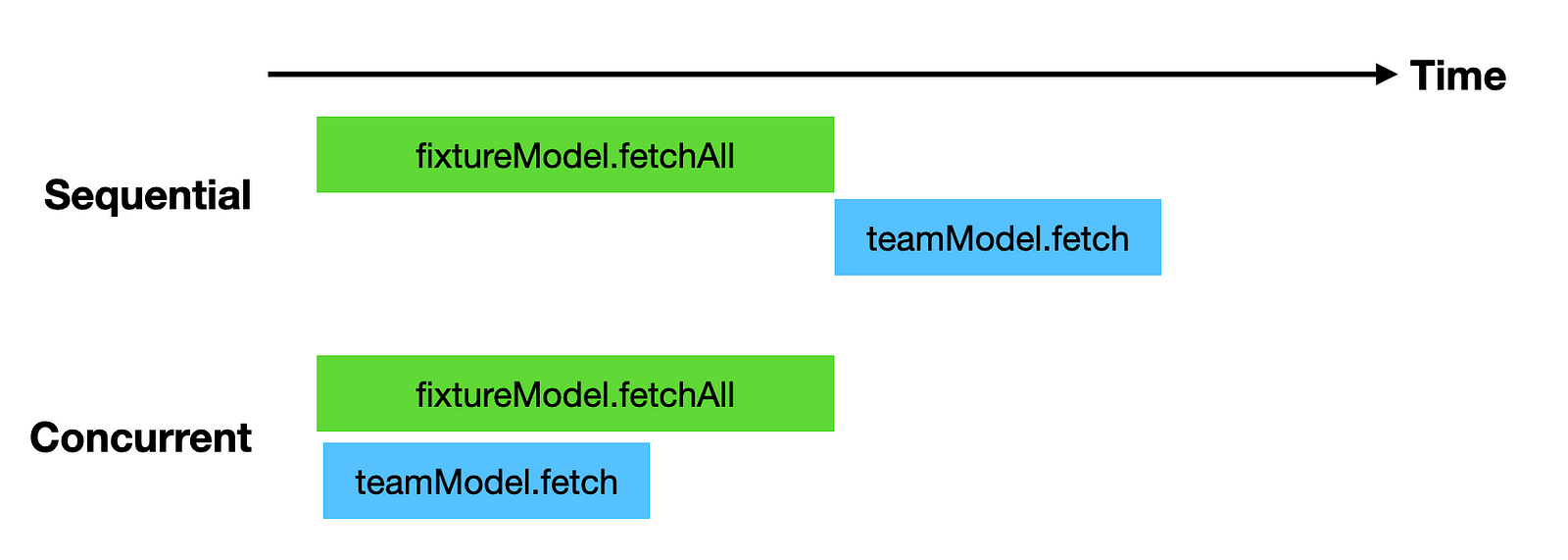
More often than not, it’s the little things that will give us the biggest gains. Take the following function as an example.
async function getFixturesAndTeam(teamId) {
const fixtures = await fixtureModel.fetchAll()
const team = await teamModel.fetch(teamId)
return {
team,
fixtures: fixtures.filter(x => x.teamId === teamId)
}
}
Instead of fetching the fixtures and the team sequentially, we can improve performance by doing them concurrently.
async function getFixturesAndTeam(teamId) {
const fixturesPromise = fixtureModel.fetchAll()
const teamPromise = teamModel.fetch(teamId)
const fixtures = await fixturesPromise
const team = await teamPromise
return {
team,
fixtures: fixtures.filter(x => x.teamId === teamId)
}
}
It’s a small change, but it can yield big performance improvements.
3. Caching is Your Best Friend
Caching is one of those things that’s so obvious but so often overlooked. Let me put it this way: caching is a cheat code for building performant and scalable applications.
Behind every large-scale system is a sensible caching strategy.
For a typical serverless API, you can implement caching at every layer of the stack.
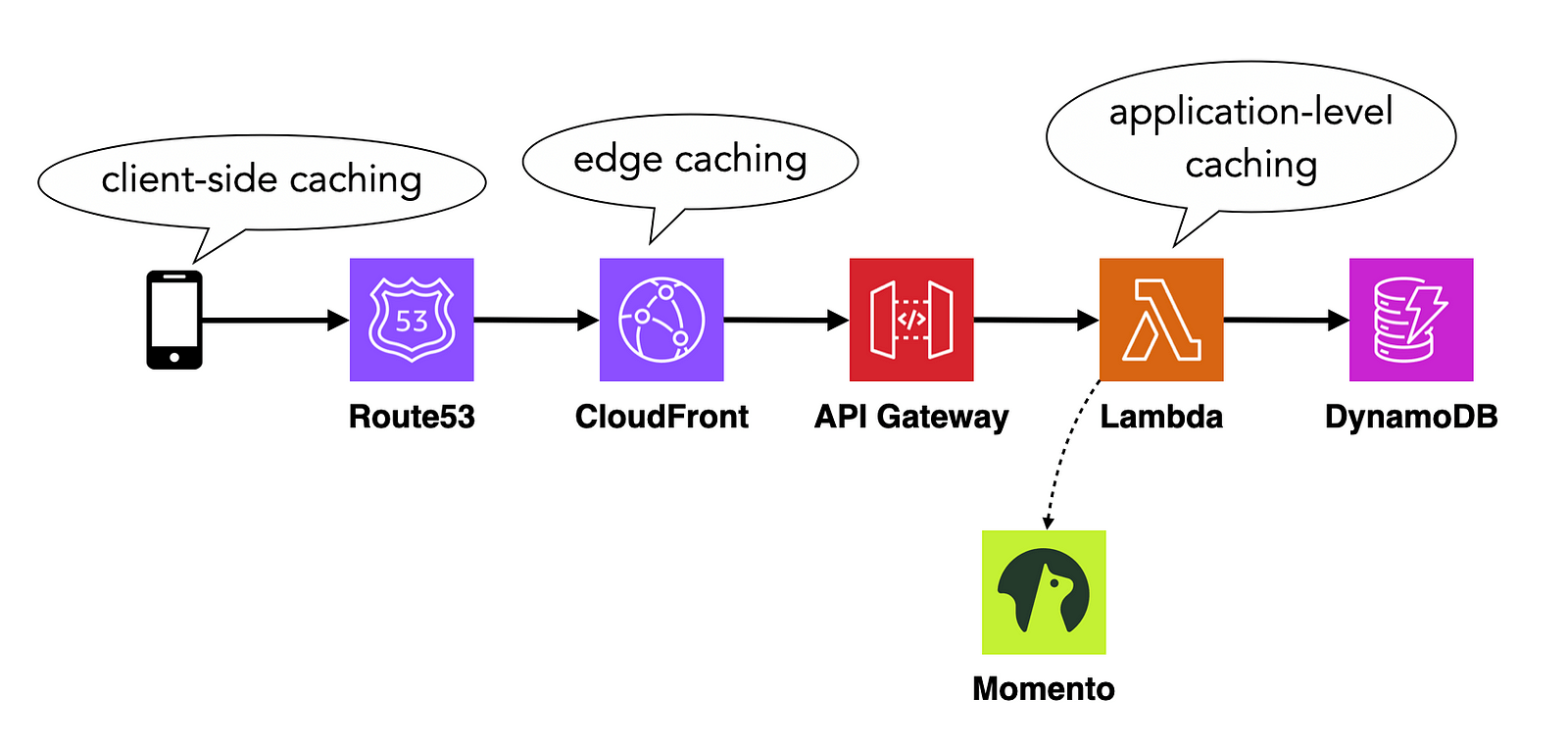
The most effective places to apply caching are on the client side (e.g. static content), at the edge (for API responses) and in the application code.
Make sure you cache anything expensive to compute or retrieve. The less work your system needs to do, the faster and cheaper it is to run.
If you want to learn more about how to apply caching at each of these layers, then check out this more in-depth article.
4. Choose the Right Tool for the Job
AWS offers a huge array of services, many of which have feature overlaps.
For example, if you need a messaging service, you can choose from SNS, SQS, EventBridge and Kinesis to name a few. They work differently and are optimized for different workloads, but for many simple use cases, they can be used interchangeably.
It’s important to understand their trade-offs and pick the right tool for the job. In fact, that’s the most important skill for an AWS solution architect! Because, in the cloud, every architectural decision is a buying decision.
Services that charge by uptime, such as Kinesis or ALB, can be relatively expensive when the throughput is low. If you have an average through of 1 message per second, then Kinesis’s uptime cost makes it relatively more expensive than services that only charge by requests.
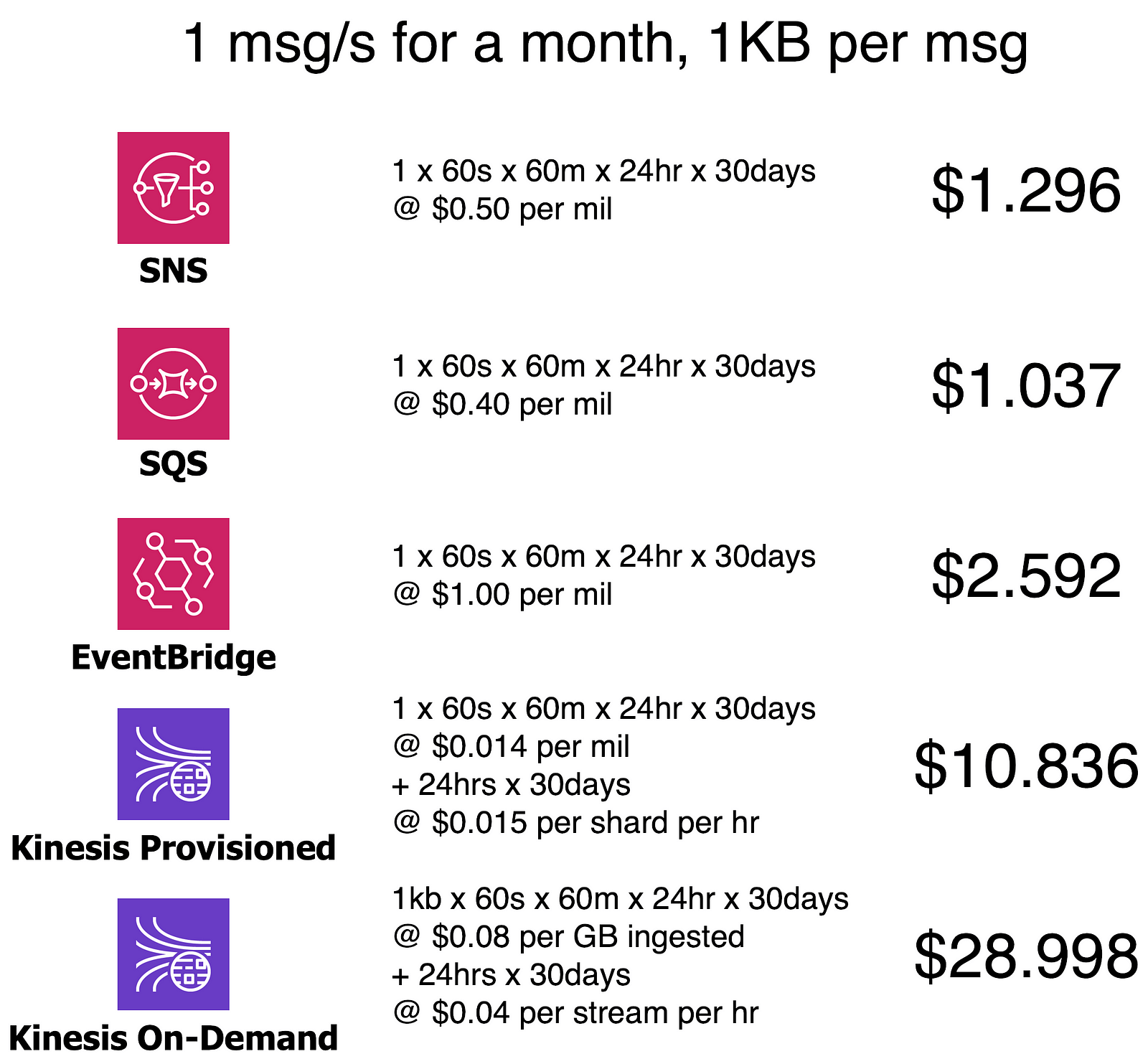
However, these services are typically much more cost-efficient at scale, often by order(s) of magnitude!
At a consistent 1,000 messages per second throughput, Kinesis is significantly more cost-efficient than the likes of SNS, SQS and EventBridge.

Another dimension that can affect both the cost and performance of your application is batching.
At scale, it’s much more efficient to process data in batches. It would take fewer Lambda invocations to process the same amount of data. This translated to better performance and lower processing costs.
Thanks to its support for batching and the ability to ingest large volumes of data cost-efficiently, Kinesis is often preferred for big data applications.
5. Observability: The Performance Long Game
Optimizing application performance is a long game. You can’t just do it once and forget about it. You need to be constantly monitoring, observing, and adjusting. That’s where observability comes in.
I’m a huge fan of the OODA loop — Observe, Orient, Decide, and Act.
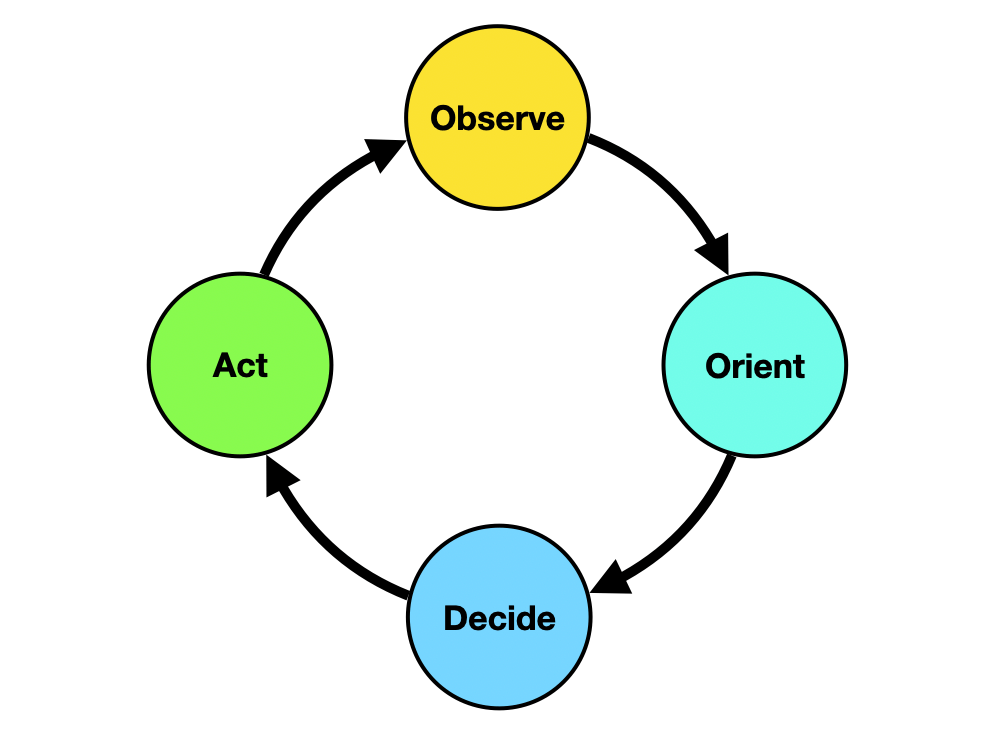
When you have a distributed system, having visibility into what’s happening in real time is critical.
Observability platforms like Lumigo give you the insight you need to identify bottlenecks and track performance metrics across the board.
Measure, identify problems, improve, repeat.
Wrap up
Optimizing serverless performance is about more than just reducing cold starts or picking the right runtime.
It’s a holistic process, from optimizing Lambda memory to caching, choosing the right services, and investing in observability.
Implement these five strategies, and make performance and cost efficiency a core part of your competence. Do these, and you’ll see significant gains in both performance and cost efficiency.