










Customers expect that online services are available all the time. The truth is that outages happen to almost everyone because providing 100% service availability is challenging and costly. Creating reliable and profitable service is, amongst other things, finding the balance between application availability, costs and time to market. Faster feature delivery means less availability as constant changes to production may cause issues and introduce bugs. On the other hand, a slow and highly controlled release process leads to stale services and loss of the competitive edge.
You may use your intuition to define when service is reliable and satisfies customer needs, however, there are good practices that can help you take a more structured and measurable approach. Using techniques described below allows you to take informed decisions about balancing reliability work against engineering velocity.
Measuring what matters – Service Level Indicators (SLIs)
SLI is a metric of some aspect of the level of service. What it is exactly depends on the functions that it provides. For most web-based services there are a few key SLIs that may be considered:
- Availability – period of the time that a service can be used by customers,
- Latency — how long it takes to return a response to a request,
- Error rate – what fraction of service responses were unsuccessful,
- Throughput – typically measured in requests per second.
Defining a limit – Service Level Objectives (SLOs)
SLO is a target value for a specified SLI. It is defined by the service owners and should be driven by customer expectations. Chosen SLO value has implications during service design, further development and operation, we will take a look how to select it in the chapter below. An example of SLO could be availability of 99,9% time over a year or average latency lower than 200ms for all placed orders.
Obey SLOs or else… – Service Level Agreements (SLAs)
SLAs are contracts with customers or service users, usually as formal, legal agreement. It may include consequences when missing the SLOs, for example, a rebate or a penalty that the business must pay to the customer. As it is mostly a legal document, details are out of the scope of this blog post. However, you can also consider it from a different angle as an internal agreement with the development team. For example, if you have defined your SLO as 99.9% availability, breaching it may require stopping further feature development and having full team focus on improving reliability and fixing outstanding live issues or technical debt.
Steps to define SLI and SLO
Now you should have a high level of understanding what SLIs, SLOs and SLAs are. Let’s have a look at how you could define the above in a more systematic way.
Identify systems and stakeholders
In modern microservices architecture services usually are composed of many moving parts. First of all, you must find the most important components from a business perspective. With which function does the user interact the most? What applications support core business functions? By identifying crucial elements you will make sure that you start measuring essential pieces of your service. To be able to answer those questions you will need to identify the main stakeholders. Business product owners should be able to answer what is important for the customer, and by extension, for the business. Technical experts, who understand the internals of the components, will identify where business capabilities lie within the system.
Define what is important for the customer
In the previous step you defined critical systems, now write down in plain language what non-functional system capabilities are important to users. You will need help from previously identified business stakeholders. For example, if the chosen application is a payment system serving customers around the globe, you may consider availability and error rate as critical indicators.
Gather data
Having in mind what you already defined in the previous step, it is time to engage with technical experts and understand what is already gathered using existing tools. Is it even technically possible to measure indicators that the business wants? If the current monitoring platform doesn’t provide needed data, consider extending it using other tools or adjust proposed indicators with product owners.
In our payment system example you need to measure at least the error rate sent to the end user and availability of all components, like backend and databases. You can send data such as error rate to an observability platform like Lumigo, as shown in the example below, and get the metrics that answer business questions. 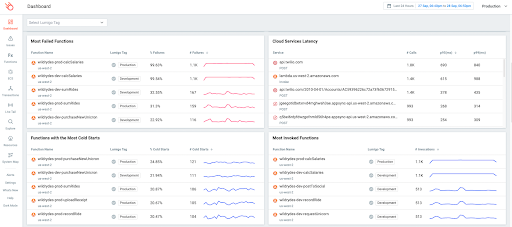
Standardize SLIs
You are ready to formalize your indicators. You have what the product owner wants and what technical experts say is possible – document it.
Define SLOs
Agreement between technical experts and product owners must be made also over SLOs, considering best user experience, costs and any architectural changes to be made to support it. How much will it cost to achieve 99.99% availability? How will it be measured – per month/per year? If you set it to 99.99% yearly it means that system can be down up to 52m 35s per year.
Alerting and dashboards
Build dashboards with current SLI and your target SLO accessible to all stakeholders. Create alerts and notify stakeholders when reaching out your limits, like 80% SLO. This will help to make more informed decisions about what next engineering tasks must be picked up by the teams.
Best practices
- Start from components supporting business critical and customer-facing capabilities.
- Measure SLIs for each needed part of a system, for example database or message queue supporting selected system.
- When defining SLOs focus on whole systems, rather than particular microservices. Combine SLIs for given components into a single SLO.
- Document and share SLIs/SLOs.
- Monitor and alert when breaching SLOs.
- Iterate and adjust SLIs/SLOs over time.
Start Monitoring your Modern Cloud Applications
Applications grow substantially over time and it’s important to make sure that you have the right SLOs, SLIs and monitoring solutions in place right from the very start of any project.
Sign up for Lumigo today to monitor and observe your serverless and containerized applications.