To give it a try, you can sign up for free at lumigo.io.

Over the past few years, AWS has made incremental improvements to Lambda’s cold start performance. Nowadays, cold starts are much less an issue for most functions, unless you’re using Java or .Net Core.
Java functions still often see cold starts that last over a few seconds. Which makes them ill-suited for user-facing workloads such as APIs. Provisioned concurrency helps, but it adds cost and complexity as I have previously explained. Provisioned concurrency is best used as a surgical tool on specific functions, not a blunt instrument to be applied across many. In practice, it drives you towards having monolithic functions so you can consolidate and minimize the number of provisioned concurrencies you need to use. This runs counter to Lambda best practices which recommend having small, single-purposed functions.
The newly announced SnapStart feature takes another big leap towards cutting down cold start duration for Java functions. It does so by initializing a new Lambda execution environment and taking a snapshot of its memory and disk state. This is done during deployment, so it’s able to avoid a full initialization of the Lambda execution environment during a cold start.
How it works
Normally, during a cold start, the Lambda service needs to do a number of things to create a new execution environment:
- Download your code.
- Initialize the Java runtime.
- Initialize your application, which includes initializing any external dependencies and executing any initialization logic your application performs. Which might include downloading static assets from S3, or calling 3rd party services.
This process can easily take a few seconds. This is why cold starts are such a big problem for Java functions that are user-facing.
You can enable SnapStart on a function through the AWS console (see below), AWS CLI, AWS SDKs or CloudFormation.
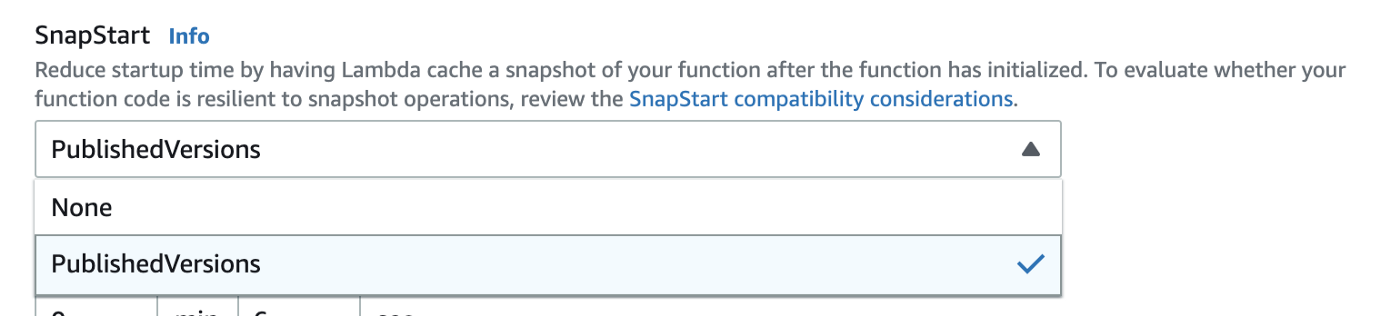
Once enabled, the Lambda service is able to change how it creates the execution environment during a cold start. When you publish a new version, the Lambda service would create a “staging” execution environment and perform the full initialization. After the initialization finishes, the Lambda service would take a snapshot of the memory and disk state. This snapshot is then converted into an encrypted file and stored as chunks so it can be more efficiently cached and resumed later.
These additional steps mean publishing a new version of your function would take significantly longer.
When the function version is later invoked, the Lambda service would download and resume only the chunks that are necessary to run your application. The chunks that have been downloaded are cached to improve read performance.
Caveats
- SnapStart only works with Lambda versions, not the $LATEST alias. So when invoking the function, you need to use the full ARN of the SnapStart-enabled version.
- You can’t enable X-Ray tracing on SnapStart-enabled functions.
- Network connections that you create during the function’s initialization are not guaranteed when the function is resumed from the snapshot.
- Any expirable data (e.g. temporary credentials) that you acquire during the function’s initialization is not guaranteed to be valid when the function is resumed from the snapshot.
- (Randomness) Please refer to the official documentation here to see what you need to do to protect randomness with SnapStart.
- At the time of launch, SnapStart is only supported on the Amazon Corretto Java 11 runtime.
Performance test
Measuring the cold start duration for SnapStart-enabled functions is tricky. The initialization happens during deployment and the initDuration is therefore not included as part of the REPORT line in CloudWatch Logs. Equally, since X-Ray is not supported for SnapStart-enabled functions, one also cannot rely on X-Ray trace to provide an accurate measure of the cold start duration.
So in order to gauge the cold start improvements of a SnapStart-enabled function, I used another Lambda function to call the function under test every 30 mins. This ensures that sufficient time has passed before each invocation so we already get a fresh Lambda execution environment each time. The cold start duration is measured as the time it takes the invocation to finish from the perspective of the calling function.
This method includes the network latency between the two functions, but given that they are both in the same region it should be negligible.
After 50 cold starts, these are the average cold start duration captured:
Without SnapStart: 2784.619ms
With SnapStart: 1330.571ms
The result is based on a hello-world function and the difference is already very significant. I suspect Java functions in a more realistic real-world setting would see an even bigger performance improvement.
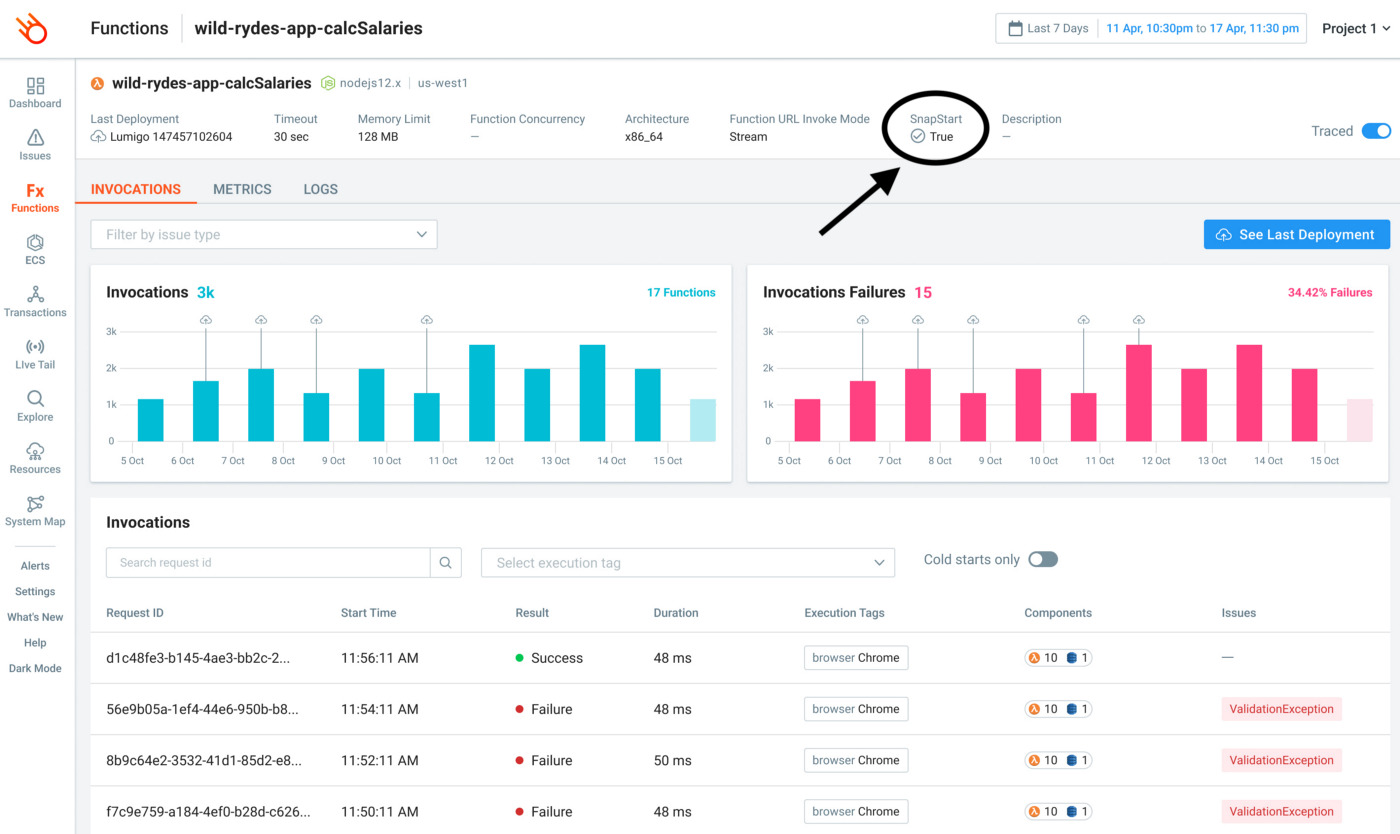
Lumigo supports SnapStart
As a proud launch partner for this new feature, we have added support for SnapStart in the Lumigo platform.
Effective immediately, you will be able to see the SnapStart status for a function inside Lumigo.