
- Guide Content
AWS Serverless Timeouts: What are they and how to fix and prevent them
Serverless architecture is one of the most common patterns for cloud applications. AWS’s flagship serverless service is the Lambda function-as-a-service. While configuring and debugging serverless Lambda functions, one of the most important properties is timeout, as it is directly related to the user experience with the function. It can be affected by many features such as memory utilization, event sources, downstream services, API Gateway, and more.
In this article, we are going to take a look at several AWS hard limits, Lambda timeout errors, how to monitor them, and best practices to mitigate these errors.
In this article
AWS Lambda Limits
AWS has put certain hard and soft Lambda-related limits on various services to minimize the damage that might be caused by misconfiguration and misuse, as well as actual malicious attacks by hackers.
The Lambda Function
Lambda functions have a default timeout of 3 seconds. When the Lambda service first launched, it allowed a maximum of only 300 seconds. But based on customer feedback, AWS increased it to 900 seconds (15 minutes).

This is a hard limit by AWS that cannot be extended. This limit is very high for HTTP APIs as most APIs are supposed to get a response within 3-6 seconds.
If they run longer, they become costly and might negatively affect the user experience. AWS increased the initial max limit to cater to the requirements of asynchronous, which typically run for longer periods.
Any Lambda invocation request that runs longer than the limit will time out and throw an error to the client.

Concurrent Execution
Concurrent execution parallelizes Lambda functions with additional instances, as a way to scale them.

The default maximum limit for Lambda instances is 1000. However, it is a soft limit that can be extended by a request to AWS support. If a Lambda function’s concurrent requests cross the limit, it will start throwing throttling errors. This is an account-level limit and applies to all functions in the account.
Memory
With serverless, memory equals CPU equals running time. Lambda functions can have memory allocated per instance from 128 MB to 3 GB max.

In Lambda, control of the performance management of a function is done with memory. The more memory you allocate, the more CPU power is added. Note, though, that up to 1.8 GB in memory, only a single core of CPU is allocated. Beyond that, it will add an additional core. So, adding more memory may not increase performance if the code is not changed to make use of a multi-core CPU. This directly relates timeouts if memory and execution times are not balanced efficiently.
There is also a cost implication for Lambdas. AWS charges based on memory and execution time. And, for execution time, it considers 100ms as a unit. So, if execution time is 110ms, it charges for 200ms.
VPC
If a Lambda function needs to connect to VPC resources, it would need to go from the Lambda function’s VPC to your own VPC. That happens through the Elastic Network Interface (ENI). The default limit for ENIs per VPC is 250.

So what happens if a function needs to scale and run concurrent execution that requires ENIs higher than this limit? It may cause timeout errors.
API Gateway
AWS API Gateway is used to trigger synchronous REST or HTTP calls to a Lambda function. It has a max timeout for any downstream service, including Lambda, of 29 seconds.

That’s a very high limit for most REST or HTTP APIs. So, if you don’t configure the timeout limit at the method level, it will cause the API to keep waiting for a response for a long time (29 seconds) before it times out. That could eventually clog resources and cause throttling errors.
Downstream Services
When considering timeout issues, you also need to consider the limits of downstream systems and services. Higher limits in downstream services might cause ripple effects on the Lambda and event source clients.
For example, DynamoDB has 40,000 read units (one strongly consistent read per second, or two eventually consistent reads per second, for items up to 4 KB in size) and write units (one write per second, for items up to 1 KB in size) capacity.
Monitoring Timeout Issues
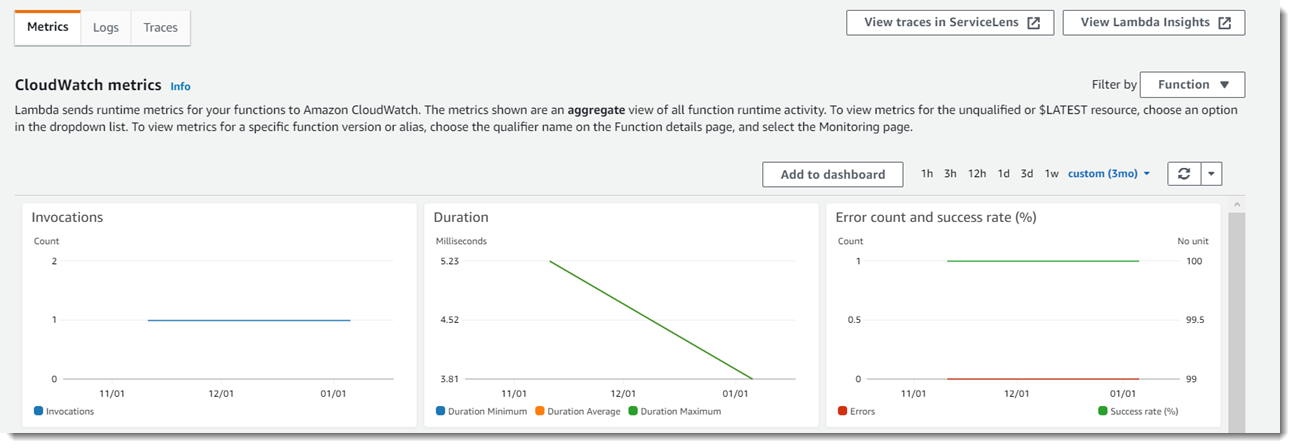
There are two AWS native tools for monitoring logs – CloudWatch Logs and X-Ray.

{kind=link}
CloudWatch Logs is the default log monitoring service for Lambda. Based on the events, it will also create an automatic dashboard with several metrics such as duration, throttle, averages, dead letter errors, error count, and success rate. These metrics help understand how a function is performing.
X-Ray goes one level further down and helps us monitor how a request is performing end-to-end at each server level in a whole serverless workflow. For example, if a Lambda function is calling S3 to upload a file and a DynamoDB table to update a record, X-Ray maps and traces report how these services are performing for the API calls performed by the function.
Third-Party Monitoring Tools: Lumigo
Many 3rd-party tools can detect Lambda timeouts in realtime. Lumigo, for instance, would highlight them on the Issues page.

From here, you can drill into the function’s details and see its recent invocations, check its metrics, and search its logs.

Of course, you can also drill into individual invocations to see what happened.

From the log messages on the right, we can see the dreaded Task timed out after 3.00 seconds error message.
The last log message we saw before that was loading restaurants from https://…. That’s a useful signpost that tells us what the function was doing while it timed out.
Best Practices for Handling Lambda Timeout Issues
● Fail fast – You should configure timeouts as low as possible. It ensures you are not wasting the bandwidth when the downstream system is struggling to respond on time.
● For REST APIs, make sure the timeout is configured to 3-6 seconds. A longer latency will cause a bad user experience. For asynchronous calls, monitor the metrics for the average time taken and set the timeout based on each batch size and avoid timeouts at the function level.
● For asynchronous flows, configure the retry feature of Lambda, which can address network glitches better than other solutions.
● Use the getRemainingTimeInMillis API method to retrieve the remaining time for the function to timeout and use it to set timeouts. This will give the request a higher chance to complete.
● Apply a circuit breaker pattern to avoid a cascade failure of function invocations. It ensures resources are not clogged and as a fallback method, implement the caching or default response strategy.
● If a Lambda function has logic that is CPU-intensive/high-memory, try to allocate more memory to reduce the execution time. Keep in mind that if memory is more than 1.8 GB, a single-threaded application won’t give better performance. You need to design the logic with a multi-threaded approach.
● If it takes 110 ms or more to execute a function, try to increase memory to reduce the execution time so that it is less than 100 ms and doesn’t charge you for 200 ms. You need to maintain a balance.
● Lambda is not the solution to every problem. If you need to run tasks that take longer, consider other solutions such as ECS or EKS.
● You can use Step Functions to break Lambda functions into multiple steps if it makes sense.
Conclusion
A serverless architecture and specifically AWS Lambda can be a powerful approach to many requirements. One of the issues it creates, however, is timeouts. In this article, we discussed best practices for designing Lambda functions, which can minimize timeouts and make sure that execution failures due to timeouts are handled efficiently and gracefully.