










Every Lambda function comes with 512MB of ephemeral storage in the shape of a /tmp directory. This storage space can be reused across multiple invocations for the same instance of a Lambda function. Each instance of a function has its own /tmp directory and data is not shared amongst different instances of a function.
Accessing this /tmp directory is the same as accessing the local hard disk, so it offers fast I/O throughput compared to using network file systems such as EFS (check out our article on the use case and performance of using EFS with Lambda).
The /tmp directory provides a transient cache of data between invocations on the same Lambda worker instance. It’s useful in cases where you need to unzip files or clone a Git repository as part of a Lambda invocation. However, the size of the /tmp directory was fixed at 512MB, which limited its usefulness.
Starting today, you will be able to change the size of the ephemeral storage to up to 10GB and as a launch partner, we’re proud to announce that Lumigo has added support for this new feature. When you navigate to the function details page, you can see the amount of ephemeral storage that has been allocated for the function:
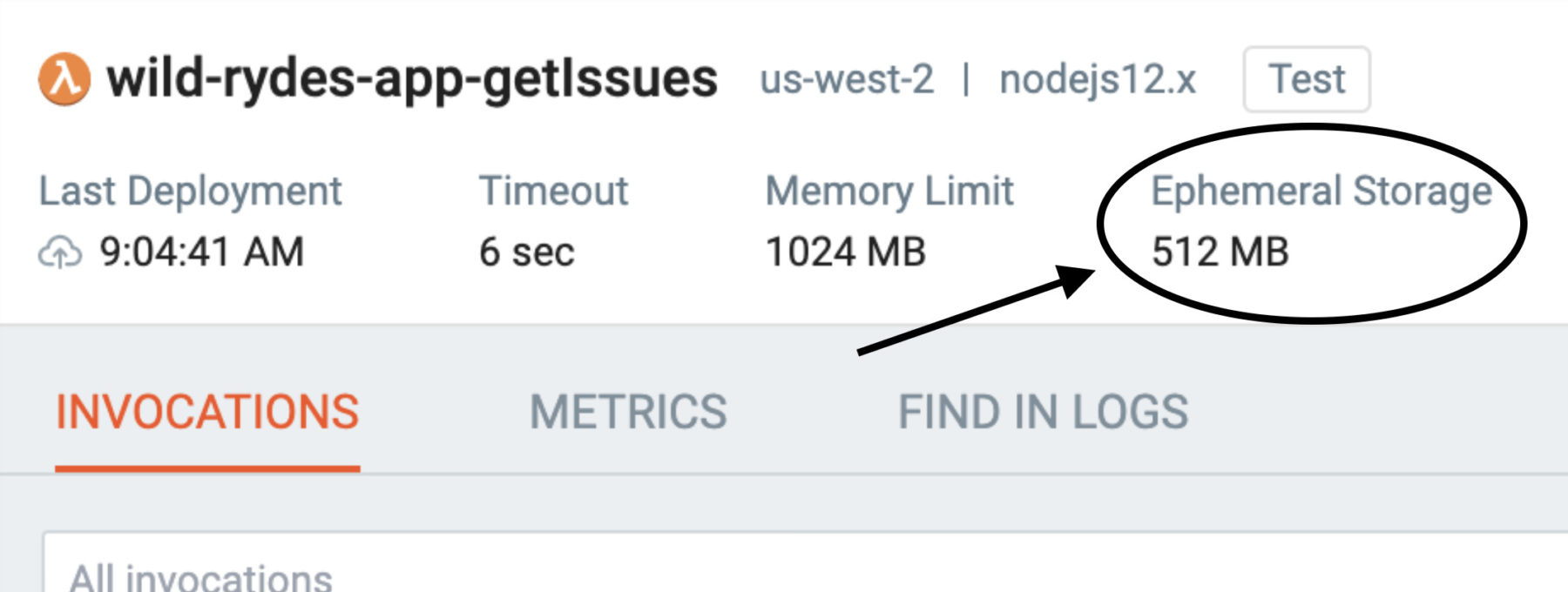
For the rest of this blog post, let me tell you more about this exciting new feature.
How can I change this setting?
You can configure this setting in all the ways you are able to create/update a Lambda function today:
- via CloudFormation or any tools that use CloudFormation under the hood (e.g. Amplify, CDK, Serverless framework and SAM).
- via the AWS CLI.
- via the AWS SDK.
- via the AWS console (see below).
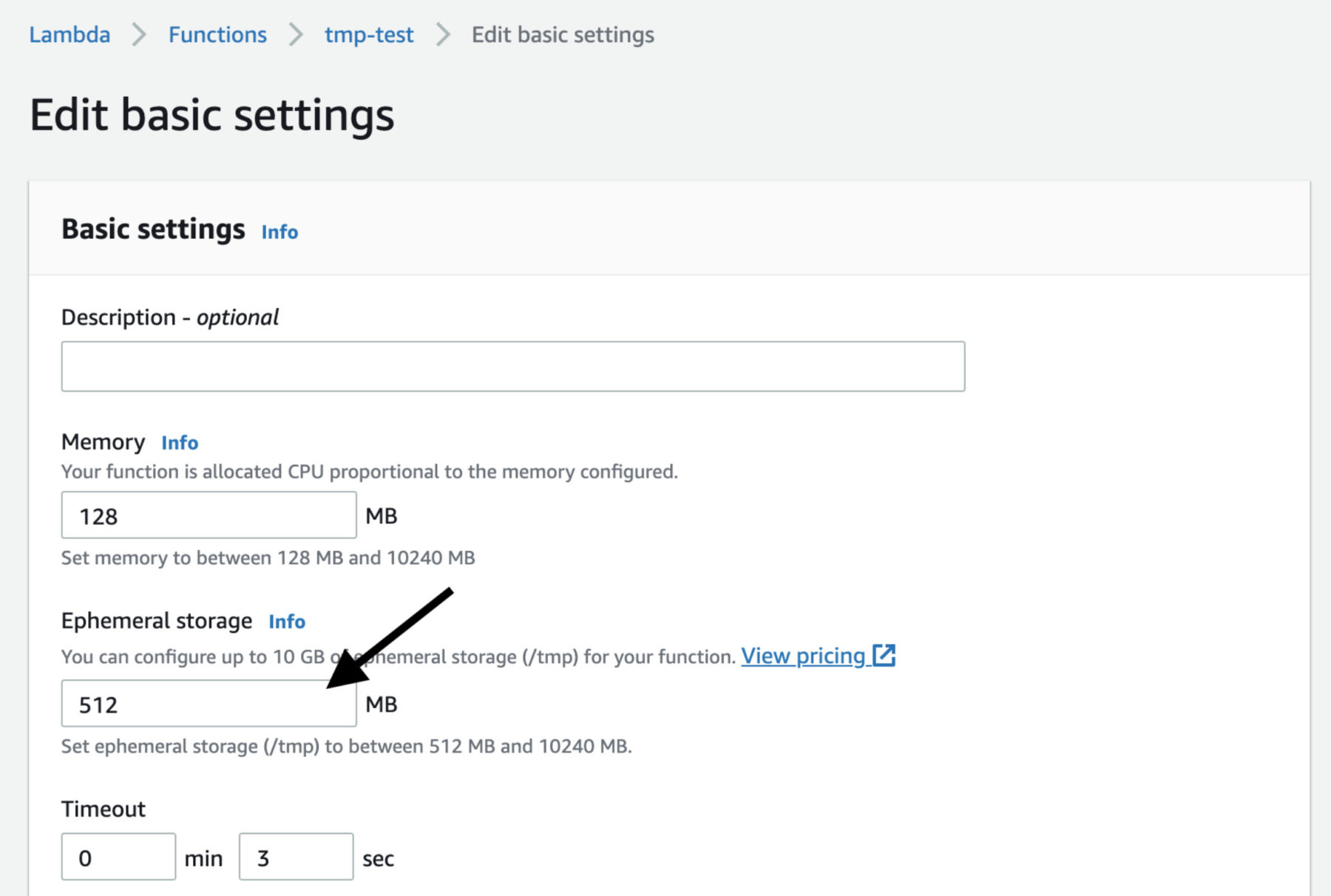
Do I have to pay for the extra storage space?
Yes, you do. At the time of writing, the pricing information is not yet available, but you can find out on the official Lambda pricing page here.
Is there any performance overhead?
No, it doesn’t add any overhead to your Lambda invocations. We compared two Lambda functions in our tests, one with the default 512MB of ephemeral storage and another with 10GB of ephemeral storage. Over 1000 cold starts, there is no statistically significant difference in the initDuration and Duration metrics of these two functions. So there doesn’t appear to be any performance overhead for using larger ephemeral storage.
Does it allow me to upload bigger deployment packages?
For machine learning (ML) workloads, you often have to work with large models that don’t fit into Lambda’s 250MB deployment package size limit. Unfortunately, this change does not change the deployment package limit. It only changes how much data you are allowed to write into the /tmp directory at runtime.
If you need to include large files in your deployment artefacts then you can package your function as a container image, see our blog post here. Alternatively, you can download the large files (such as the ML models) during initialization and save them into the /tmp directory. For Node.js functions, Lambda now supports top-level await. So it’s possible to download these large files during the module initialization phase of a cold start. If you’re worried about the additional latency this adds to your cold starts then you can also use Provisioned Concurrency so they’re performed ahead of time (see our blog post on Provisioned Concurrency here).
How is this different from using Lambda with EFS?
Using the ephemeral storage (i.e. the /tmp directory) differs from EFS in two major ways.
- Performance: EFS is a network file system and its read and write latency is therefore much higher (~5-10x) than the ephemeral storage.
- Data sharing: each Lambda function worker has its own instance of
/tmpdirectory and they don’t share any data. Whereas with EFS, data is shared between all the components (Lambda functions, EC2 instances or containers) that are connected to the same EFS file system.
How do I choose between the different storage options for Lambda?
Lambda offers a number of storage options:
- Lambda Layers
- Ephemeral storage (
/tmpdirectory) - EFS
- Container images
They cater for different use cases and have different characteristics and limitations. James Beswick has an excellent article on how to choose between these options here.