










Health checks are an important factor when working with containerized applications in the cloud and are the source of truth for many applications in terms of their running status. In the context of AWS Elastic Container Service (ECS), health checks are a periodic probe to assess the functioning of containers.
In this blog, we will explore how Lumigo, a troubleshooting platform built for microservices, can help provide insights into container crashes and failed health checks. With Lumigo, we are able to get deep insights into the behavior and performance of serverless and containerized applications giving more transparency to the end user.
Let’s look at a scenario you may be faced with. We have a Python Flask application that is running in a container but the health check is intermittent. Sometimes it will return HTTP 200 OK and other times it will return HTTP Error.
How can we understand intermittent health checks?
Health checks are designed to periodically assess the availability and responsiveness of a container. This is carried out through an endpoint within the application, which is usually `/health`. The health check endpoint is expected to return HTTP 200 OK if the application is healthy and a HTTP Error if the application is unhealthy. In our case, it is returning both. This can be seen as an intermittent health check.
As a result, let’s assume that when a health check fails our application it will trigger a restart of the container. This is a good thing as it will help to ensure that the application is continuously running. However, if the health check is failing intermittently like it is in our scenario, then this can lead to a lot of container restarts.
The impact caused by bad health checks
Depending on the situation, the impact of bad health checks can be quite significant. Let’s take a look at a few examples:
- Behavior – Intermittent health checks can lead to unpredictable behavior and instability within the application. When health checks are fluctuating, it can be hard to determine the actual status of the container.
- Cost – As AWS ECS uses a payment model where you pay for what you use, then you will only be charged for the time that your container is running. Intermittent health checks can crash/restart containers and as a result, frequent restarts _can_ lead to a higher cost. Not only in a monetary sense but also in terms of the time spent debugging the issue.
- Performance – End users may experience higher latency from their application requests. Failed health checks can lead to slower response times and can also impact the utilization of resources. For example, an unhealthy container may consume resources without effectively serving the requests it is receiving and this then has a knock-on effect on the performance of the application.
- Availability – If the application is serving bad health checks then ECS may terminate or restart the container. This will lead to brief periods of downtime for your end users and can impact the continuity of the application.
- Scalability – Intermittent health checks can hinder the scalability of an application. If the health of the container is not accurately represented then this could cause under provisioning during peak load times or over provisioning during low load times. This can then relate back to the cost implications of having intermittent health checks.
Lumigo crash detection
This is where Lumigo comes into play. Lumigo is a really powerful tool and somewhat of a cheat code that has a number of features to help you identify and resolve issues with intermittent health checks.
Let’s start with the Lumigo dashboard that provides a comprehensive overview and visibility of running applications. In the dashboard, we can see a list of all the applications that are running and their health status. Having a centralized dashboard like this is really useful as it allows you to quickly identify any issues with your applications.
Next up, we have the Lumigo tracer. The tracer is a really powerful tool that allows you to trace the execution of your application. It provides a visual representation of the application flow and allows you to see the behavior of your application. This is really useful as it allows you to identify any patterns or trends that may be causing the intermittent health checks.
To insert the tracer into your application, you can use the Lumigo Python SDK. The SDK is really easy to use and can be installed using pip:
pip install lumigo_tracer
Alternatively, you can see the full documentation: https://pypi.org/project/lumigo-tracer/#description
Finally, we have the logs. The logs provide a detailed view of the application logs and allow you to see the logs in real-time. This is really useful as it allows you to see the logs as they are being generated and can help you to identify any issues with the application without any delay.
How to analyze the crashes
Once you have the Lumigo tracer installed in your application, you can start to analyse the behavior of the application. In our case, we can see that the health check is returning both HTTP 200 OK and an Error. This is causing the container to crash and restart. Let’s take a look at an example of a failed request in Lumigo Explore.
In the example below, we can see that there are a number of health check errors on our application resulting in 404 Errors.
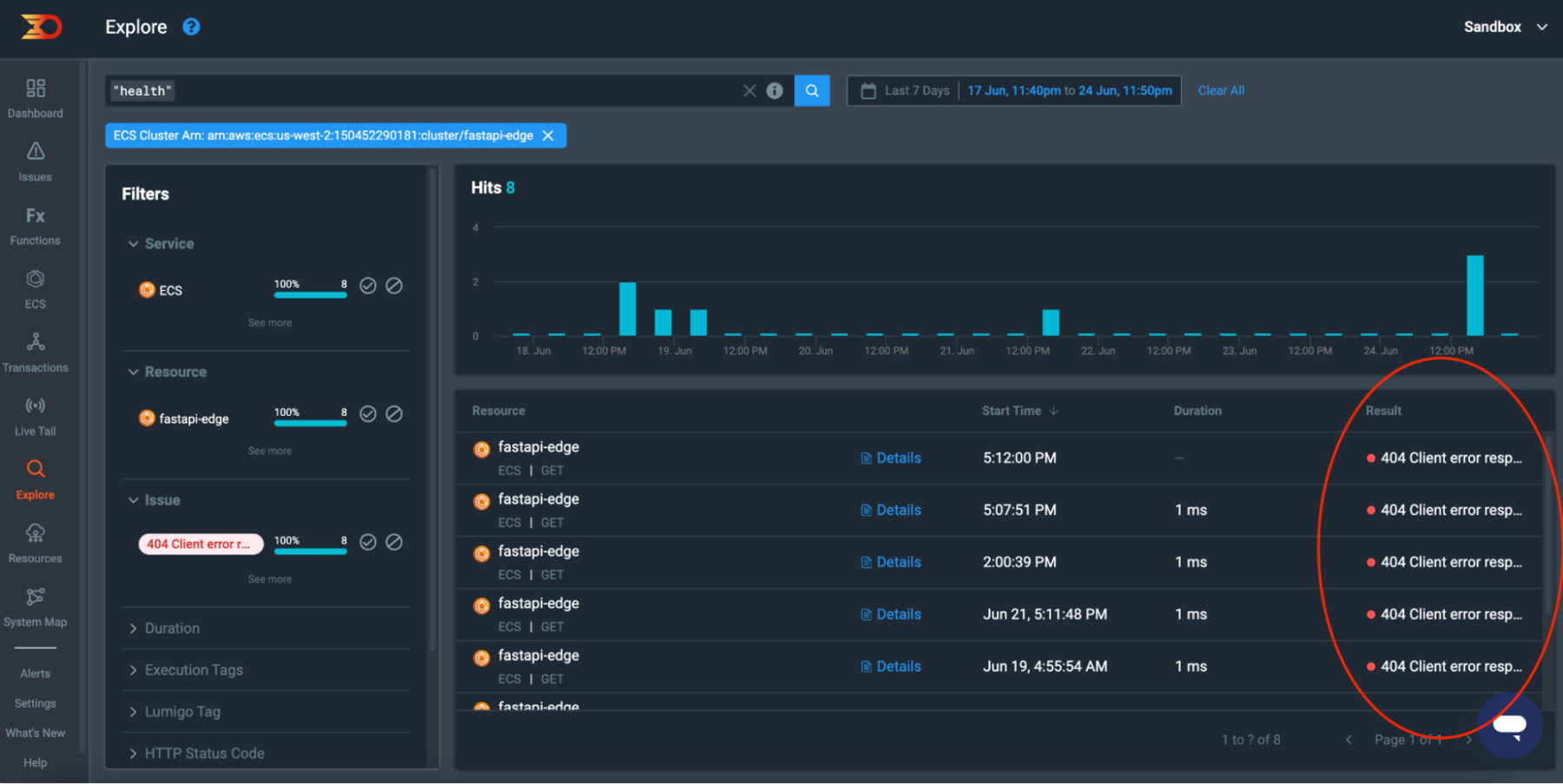
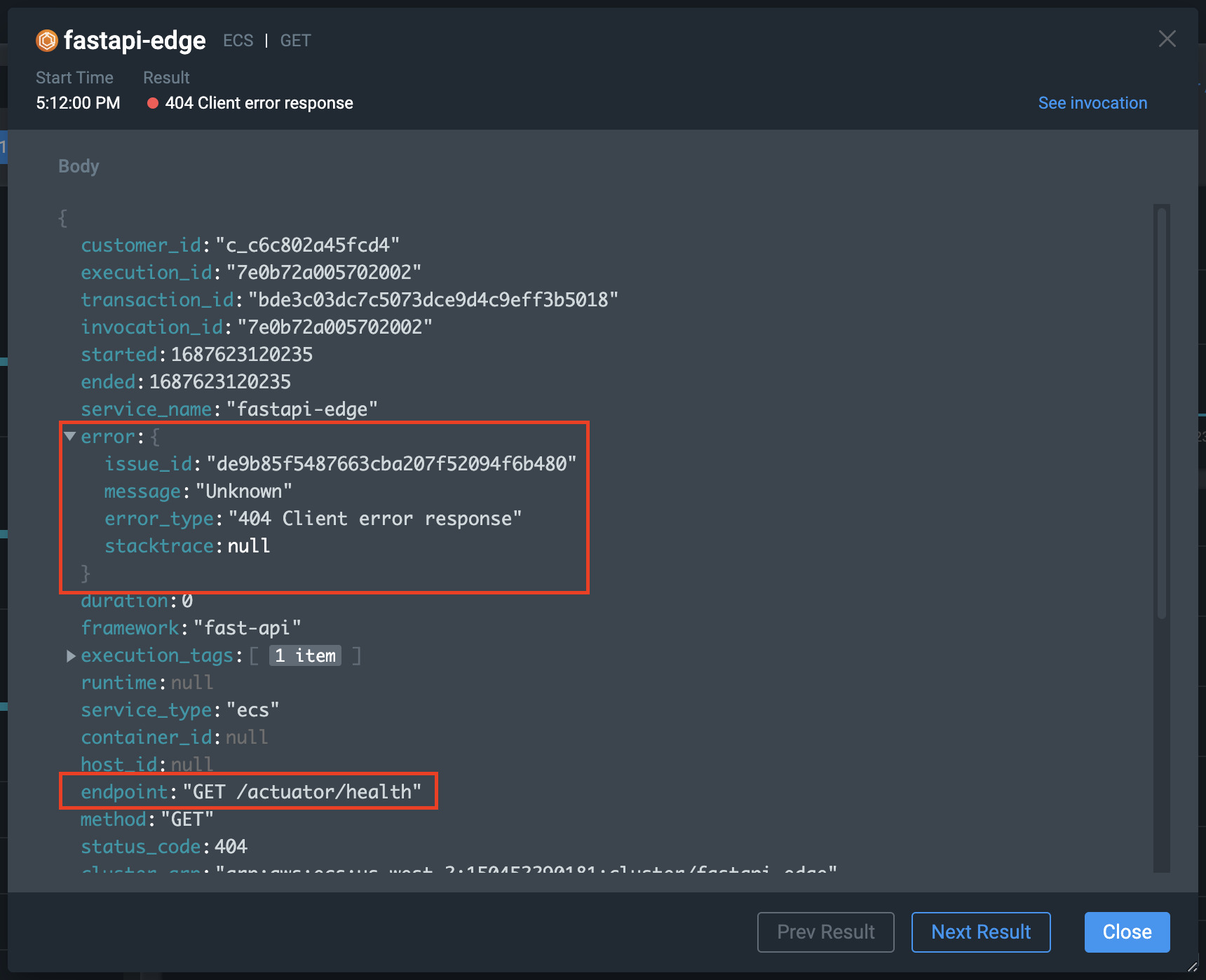
This could be for a number of reasons, including a health check request whilst the container is in an unhealthy state. We can open up the request to find out more information by clicking on the “Details” link. This will show a dialog box with the request payload.
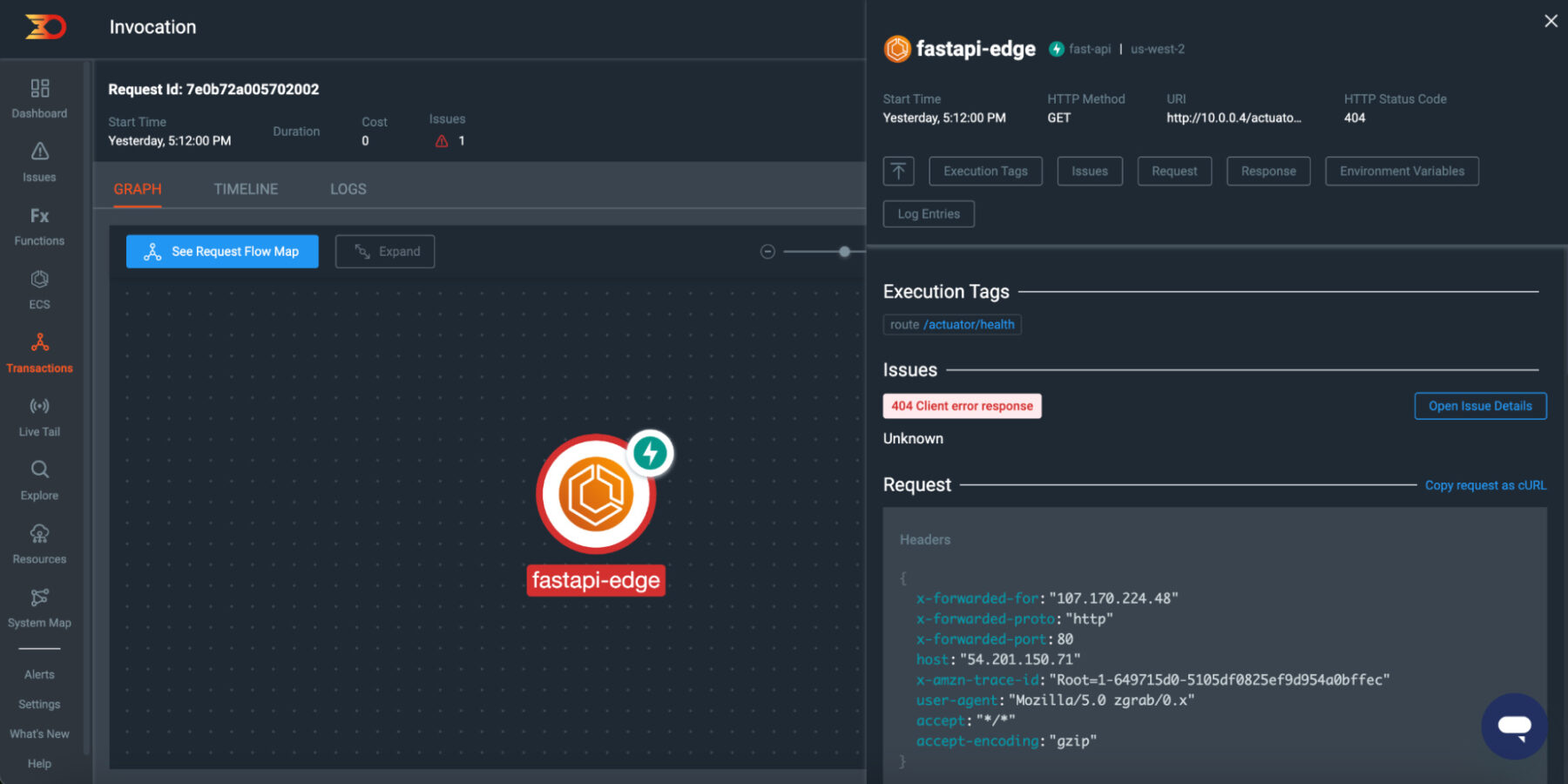
If we click the “See Invocation” link in the top right, we can then see the full view of the request including any Logs entries, request output and even a request flow map that will show you exactly where the error lies.
Strategies on improving health check reliabilities
Now that we can see how easy it is to identify errors and break them down using Lumigo, there are also some ways to improve this reporting pipeline for reliability and notifications.
- Retry the health check request. This can help improve the reliability of the health check as it is not always guaranteed to be an error. Network requests can fail for a myriad of reasons and it is not always an issue with your application.This can be done by adding a retry mechanism to the health check request within your code, retrying the request after a set period of time.
- Setting a timeout on the health check request can also help to improve the reliability of the health check. When making a request, it will wait for a response but if one is not received within a certain period of time, this can take up resources unnecessarily and delay the reporting of an error. This is a simple method to include and can be done by setting a timeout on the health check request within your application code.
- Pay attention to error handling within the application. Ensuring you have good error messages and error recovery mechanisms will pay dividends should an error arise. With this in place, you will be able to see the messages in the log entries along with the timeline of requests and this will help you build a clear picture of what has happened. Tie this in with Lumigo real-time Alerts and you will be notified the moment something goes wrong.
Don’t bad health checks affect your ECS apps
Experiencing intermittent errors can be incredibly frustrating for developers, particularly when these errors result in container crashes. The health check endpoint serves as the ultimate authority for the application’s status, making its failure ripple throughout the system. When the health check fails, the consequences can be far-reaching and impactful, affecting the overall stability and performance of the application.
In this blog, we have explored the concept of intermittent health checks, delving into the challenges they pose and the potential implications that arise from them. We have discussed the importance of gaining a comprehensive understanding of running applications, as well as the significance of identifying any issues through detailed logs and visual representations of the request flow. Additionally, we have shared valuable tips aimed at enhancing the reliability of applications, ensuring smoother operations and improved performance.
If you are seeking a powerful solution to gain deep visibility into your microservices and containerized applications, sign up for Lumigo today. With Lumigo, you can unlock a comprehensive troubleshooting platform that helps you to resolve issues related to container crashes and failed health checks, ensuring transparency and improved performance for your applications.