










With the dawn of microservices and serverless, event-driven architectures have become the way to go when building a new system in the cloud. This approach has allowed for greater scalability, as the system can easily adapt and respond to changes in traffic or demand without having to overhaul the entire architecture.
Additionally the Event-driven approach means your application is mainly concerned with routing event data to the right services. Your user requests a website, which triggers a request event, which the service will either handle directly or send to other services to handle via yet other events.
Modern cloud-based applications have multiple services that work together to solve such tasks. This allows individual services to become highly specialized and optimized for a single problem. It also lets us scale these services independently, giving us more precise methods to achieve performance optimization and cost savings.
But all this new flexibility comes at a price. We can’t simply go on building applications like we used to. An architecture that produces an application running in a VM won’t work in a serverless environment. To take advantage of the full potential of serverless infrastructure, we need to embrace event-driven architecture, which is facilitated by messaging services.
This article will review the main messaging options AWS gives us and explain when each service is a good fit.
Available Messaging Services on AWS
While many services on AWS are either created as messaging services or can be used as such, this article will focus on the four main ones:
- Amazon EventBridge
- Amazon Kinesis
- Amazon SQS
- Amazon SNS
First, let’s review the scalability of each of these services, then look at their costs, and finally, error handling.
Scaling Constraints
All cloud services come with constraints. They might scale well, but they don’t do so indefinitely and have different scaling characteristics. AWS changes its quotas all the time, usually for the better, so before you start using a service, do some online searches, e.g., “EventBridge quotas.” This way, you’ll be up to date.
Also, check out the service quotas for your AWS account. Some might change over the course of your account period, either due to service updates or because your account is older than 12 months.
The quick answer to “What to choose if scaling is important?” is: If you need throughput, consider SNS or EventBridge; if you need concurrency control, you should consider using Kinesis.
Now that that’s out of the way, let’s look at how the four messaging services behave under load.
EventBridge and SNS
These two services execute Lambda functions asynchronously and scale linearly with the events they receive. For every event, they will start a new Lambda invocation.
There is no batching; if a function hasn’t finished executing, the services will start a new one in parallel, only limited by the maximum of parallel executions per account.
Sometimes you just can’t simply go for maximum throughput, so this scaling behavior also has a downside: If you have a downstream service that can’t keep up with that many parallel functions hammering on it, you could get into trouble. If you get a spike in traffic, all these parallel function invocations could overwhelm your service and start failing.
Asynchronous Lambda invocations are automatically retried at least once, so a small spike can be compensated for easily. But if the high load is ongoing for longer, even these retries will fail, and your events will end in a dead letter queue (DLQ). These events aren’t lost, but you have to manually go through them and check if they can be resent or should be ignored.
If you have a small number of Lambda functions that interact with slow upstream services, you can use reserved concurrency to limit their parallelization. But remember that reserved concurrency is removed from the pool of parallel invocations for all your functions in one region. So, having too many functions with this configuration will negatively impact other functions’ throughput.
SQS
SQS isn’t a push service like SNS; another service must actively gather the messages from an SQS queue. Usually, Lambda reacts to an event and doesn’t poll new events from a source. So, to make Lambda work with events coming from SQS, the Lambda service runs polling processes for you that actively check SQS queues for new messages. This is why SQS’ concurrency depends on the number of these polling services. It starts with five and can go up by 60 per minute to 1,000 concurrent polling services.
SQS also lets you batch multiple messages, so one Lambda invocation can process more than one message. This makes it more efficient for small messages that don’t require much work by removing some of the overhead associated with starting and stopping a Lambda invocation.
The growth rate and the batching mean that SQS scales slower than EventBridge and SNS. Less throughput can be good if you want to protect your downstream services from sudden spikes. And after all, since SQS waits for a service to pull the messages from its queues, they aren’t gone when concurrency can’t keep up; they just stay longer in the queue.
Kinesis
Kinesis might be the least serverless service of the bunch. It scales discreetly with shards. If you add a shard, you get more concurrency. The default is one Lambda per shard, but you can configure it to up to 10 concurrent invocations per shard; so, with every added shard, you will scale up by more than just one concurrent invocation. And even with higher concurrency per shard, Kinesis guarantees the records are still processed in order.
This behavior seems rigid, but it makes it easy to keep concurrency at bay when talking to a downstream service. Ensure your shards aren’t allowed too many concurrent Lambda invocations, and you’re good. You can even set this number via an API call on the fly. Also, the messages stay in the stream until they’re processed so that, as with SQS, they don’t get lost.
Costs
The cost of using each of these services is highly dependent on volume. Services that charge by uptime, like Kinesis, are usually better suited for predictable, high-volume workloads. In contrast, pay-as-you-go services, like EventBridge or SNS, are good for low-volume or unpredictable workloads.
For example, if you have to process one message per second, the cost for a month is as follows:
| Service | Cost (USD) |
| SNS | $1.296 |
| SQS | $1.037 |
| EventBridge | $2.592 |
| Kinesis | $10.836 |
| Kinesis on-demand | $28.998 |
Here, Kinesis is the most expensive solution because you have to pay the baseline cost of shard hours, whether you use them or they lay idle. Kinesis on-demand is even more expensive because the baseline cost is factored into the cost of each message.
If we’re looking at 1,000 messages per second for one month, the cost distribution looks much different:
| Service | Cost (USD) |
| SNS | $1,296 |
| SQS | $1,036.80 |
| EventBridge | $2,592 |
| Kinesis | $47.088 |
| Kinesis on-demand | $226.55 |
The baseline cost of Kinesis amortized over the huge volume and being less per message versus the other services wins in the end. Even the on-demand setting is still vastly cheaper and can help with unpredictable workloads as long as they are demanding enough.
Error Handling
Another angle to take into account when choosing a messaging service is error handling. If things go wrong and you need to fix them, things can get ugly quickly. You can’t easily reproduce a cloud architecture on your local machine, so you have to make sure to get all the necessary information from the production system.
Lambda Destinations
For EventBridge, SNS, and Kinesis, Lambda Destinations are the go-to solution for getting crucial information about failed events in serverless systems. They support asynchronous and stream-based Lambda invocations as a source and SNS, SQS, and EventBridge as destinations. This means they’re more flexible and enable automated logic on any error.
Lambda Destinations also capture more information than dead letter queues, like event payload, number of invocation attempts, and error and stack traces from the last invocation.
But it’s not all roses with Lambda Destinations: You don’t get the payload directly for stream-based functions. You have to use the shard ID and sequence number to fetch the payload from the stream before the data is expired. This can be a problem if you see a bunch of failed events from Saturday when you check it out on Monday.
Dead Letter Queues
Dead letter queues (DLQs) are the only solution for SQS errors. You can also use them on the other messaging services, but Lambda Destinations are better in most cases.
They keep your messages, so they aren’t lost in case of errors, but they require manual intervention. So, someone has to browse them and check if they can be deleted or have to be reprocessed after a bug is fixed. Quite cumbersome, but the only solution for SQS.
Summary
This was a quick overview of the four main messaging services on AWS.
If throughput is your main concern, EventBridge and SNS are what you’re looking for. They will spawn as many Lambda invocations as possible, getting the work done in no time.
If you’re concerned that your downstream services can’t handle the sheer power of a serverless system, you might want to opt for Kinesis since it gives you precise control over concurrent Lambda invocations.
If potential costs are a concern, calculate your use for a month, and if it’s high enough, go for Kinesis; for small volumes, the other services might be cheaper in the long run.
Error handling is easiest with EventBridge, SNS, and Kinesis because they support Lambda Destinations, which gives more info about an event than DLQs. But if you have to use SQS, then DLQs are all you got.
Bonus: Two Cheat Sheets to Help You Choose a Messaging Service
Figure 1 shows a handy decision tree created by Maciej Radzikowski:
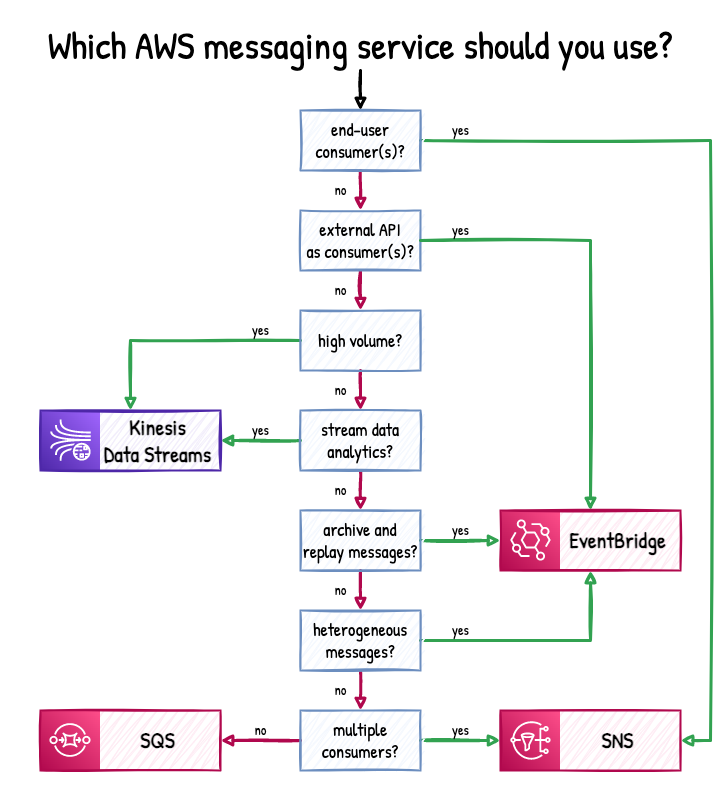
Figure 1: AWS messaging service cheat sheet. (Source: Better Dev)
Figure 2 shows a comparison table created by Yan Cui that will help you overcome those last hurdles when choosing the right service:
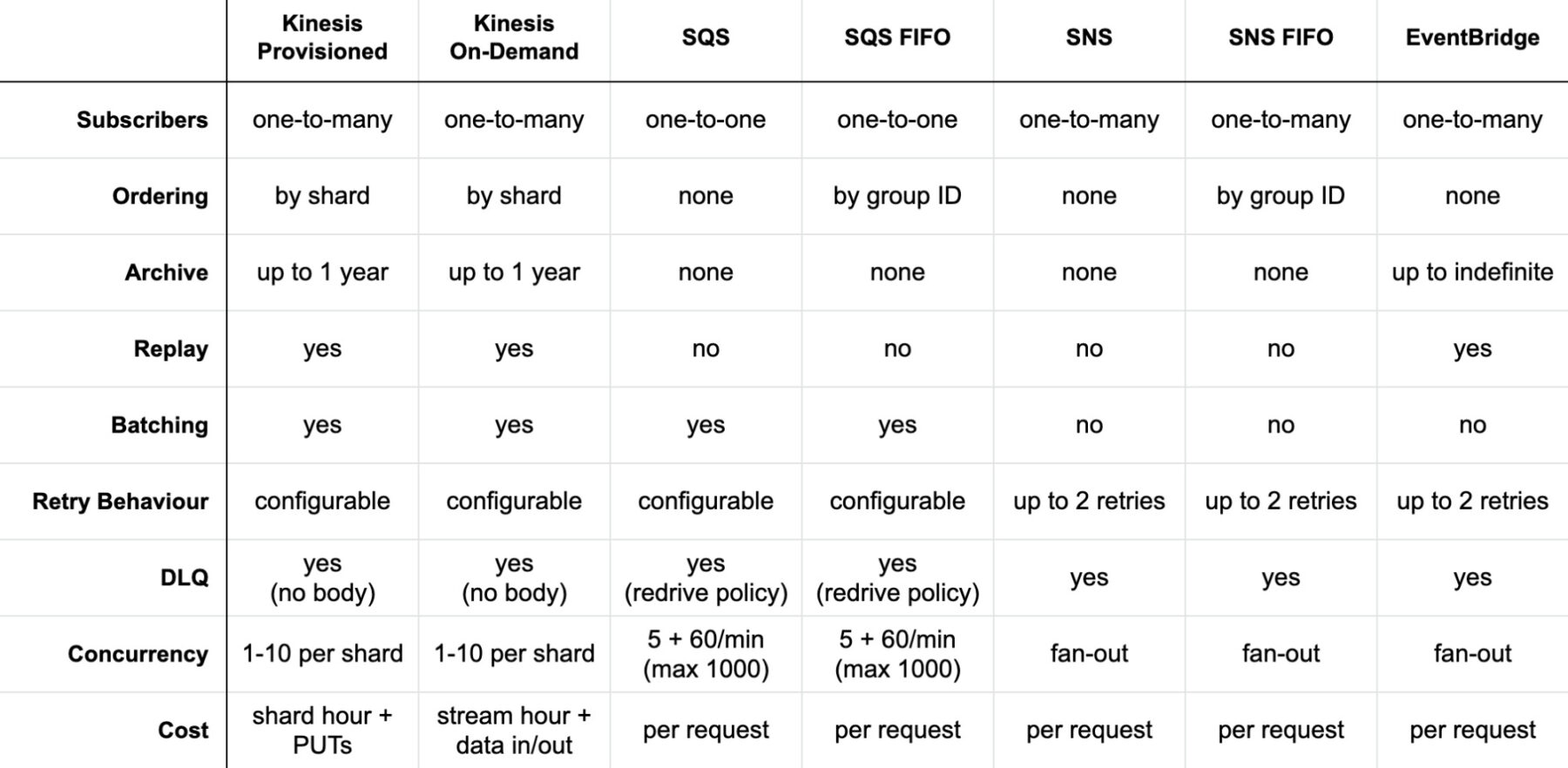
Figure 2: AWS messaging service comparison. (Source: TheBurningMonk)