










In 2016 I was the tech lead for a greenfield project completely devoid of legacy–I held the engineer’s promised land in front of me! I bit off as much new stuff as I could – serverless, event sourcing, functional programming, the whole gambit of cool. This is normally a very bad idea, but I had a team of strong engineers who had prior experience in this stuff, and we were ready to be technology pilots for the broader organization. On our technical expedition, we encountered a new kind of beast that we hadn’t seen before–the monster of glue code.
Given the technical risk of using all these new tools, we were paired with a particularly anal product manager who insisted on tracking every task the engineers did. Not my style, but I appreciated the opportunity to do some measurements on these new techniques. After we shipped V2 I felt like we spent more time gluing things together than actually writing new software, so to measure this I grouped all the work we had done into two buckets: “value”, and “glue”.
The results of my grouping were frightening: the 12-month project was about 50-50 glue-to-value.
This wasn’t profound–many software engineers today feel that their job is more about cobbling things together than actually writing algorithms and business logic. But for something that takes up 50% of a software engineer’s time, there’s remarkably little discourse and study about “glue”. When people talk about their jobs they like to talk about what languages they use, whether functional or OOP is better, or serverless vs containers, but they never talk about how they glue stuff together. When people make technology decisions, and when the thinkers of our industry recommend patterns like microservices, they never talk about how these decisions will impact glue and configuration.
“Smaller components require (much) more glue”
I have a dire prediction–the proportion of “glue” to value is rising rapidly, and the next decade of software will be defined by how we reckon with this. This increase is spurred by the trend to create smaller and more specialized components. Each of the hyped technologies we used preaches “smaller is better”, but the hidden tradeoff is “smaller requires (much) more glue”.
Part of the problem with glue is we don’t have a good name for it–”glue code”, configuration, setup, boilerplate, and integration are all names people throw around. I’ve come up with the term “surface area” because these tasks always involve the boundary between a piece of software and the outside world. Wrapping Java business logic in an API marshaling layer, configuring a CI/CD pipeline to use a piece of infrastructure, and setting up a service authentication framework’s secrets are all examples of surface area. Rich Hickey recently gave a good keynote presentation about “situated programs”, which are programs that are high in surface area[1].
All software is comprised of core business logic and at least some surface area that exposes that business logic to the outside world and makes the outside world available to the core logic. There are many different kinds of surface area; a piece of software can have surface area with:
- the infrastructure it runs on
- services it depends on
- libraries it uses
- networks
- operating systems
- time (through versioning and deployment)
- customers (through UX)
Your New Title: Sr. Surface Area Engineer
Long is the list of reasons to build and use small components: reusability, speed to market, separation of concerns, system resilience, organizational alignment, etc. These benefits are so great that businesses will always desire to write smaller components, and these desires are pushed by the architects and thinkers of our time. Monoliths aren’t cool anymore; we are supposed to be building microservices, and if you’re really cool, serverless functions. Re-inventing the wheel isn’t cool either–we’re encouraged to leverage cloud and third party services to do things for us when we can, and the companies building those services are pressured to have a narrow, lean focus by their investors. The past 10 years of web software have been about splitting software up into little pieces.
It’s obvious that if we create systems out of many small components there will be more connections between them and thus more surface area, but what many may not realize is the relationship is exponential. Surface area is linearly proportional to the size of components, but area, or how much the component can do, is related to the square of the size of components. In a system with components similarly sized to each other, the total surface area (S) is related to the inverse of the average component size (r):
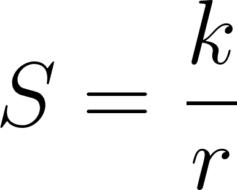
This means that given a constant set of requirements for a system, reducing the size of components within that system will result in an exponential increase in the total surface area of that system. Here’s this relationship graphed with a few architectural patterns plotted:
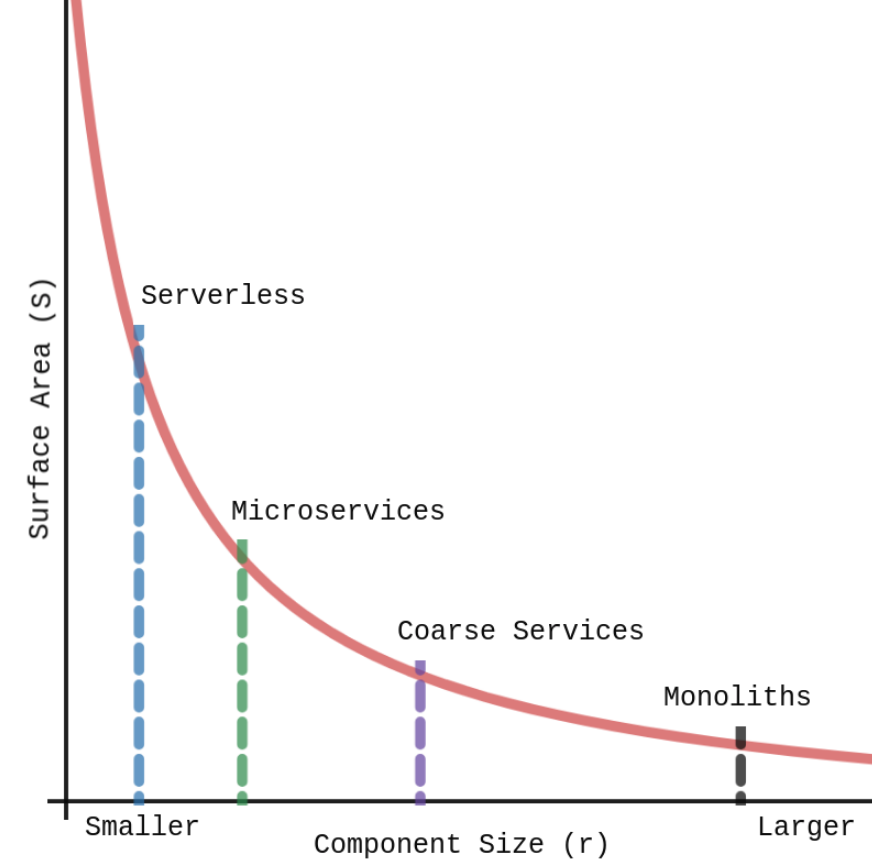
There will be a point in our quest to make smaller and more specialized components where the cost of increased surface area will outweigh the gains made in other dimensions.
We may already be past this point.
The Future of Software
This may sound like a serverless hit-piece. It’s not. Serverless is a total game-changer, it’s just how the new game is played that needs a little refinement.
There are two paths forward: settle for making software out of big components or reduce the cost of surface area. Settling for big components has gained traction recently[2], but the movement to decrease component size has too much momentum to be stopped. The second path is more attractive.
In part 2 I will go into more depth on surface area and why it’s hard to work with and reduce.
In part 3 I will present current best-in-class practices to deal with different facets of surface area.
Have you had your own struggles with “glue” code? Continue the conversation on Twitter.
Charlie is a programming Sith Lord whose power comes from intense hatred for existing development tools. A previous manager described Charlie as “a real software for software’s sake kind of guy”. Charlie is building the Strat Coordination Language, a tool to save us from the impending surface area apocalypse.