










Lumigo senior engineer Uri Parush shares how the Lumigo R&D team balances functionality and cost considerations when making serverless architecture decisions.
Serverless development opens lots of new opportunities, and if you’re invested in serverless (or you’ve been following the hype) you’ll know that cost efficiency is principal among those benefits.
Simply put, we can save money by choosing the right tool for the right task. Since a distributed microservices architecture is made up of many managed services it’s a simple task to change out the building blocks of a particular application flow. It’s rare that there isn’t more than one option to fulfill a particular task.
In this article we’re going to look at serverless cost optimization, using the example of a real data processing flow from the Lumigo backend, where we had to choose between Kinesis Streams and Firehose. We’ll explain the thought processes involved in our original architecture decision, then we’ll explore the reasons why we decided to reexamine our original decision, and how our subsequent decision to ‘change out our building blocks’ resulted in cost savings of around 50 percent.
Why did we choose Streams in the first place?
Let’s start by looking at the flow in question. As you can see, this log processing pipeline involves a combination of Kinesis Streams and Lambdas. It’s a fairly typical piece of serverless architecture.
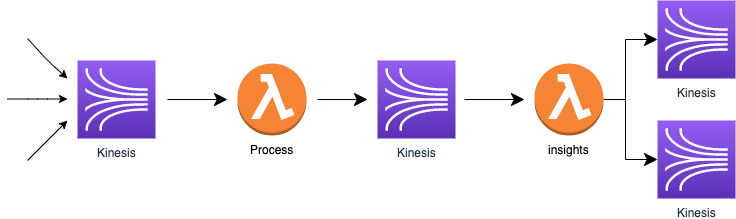
The interesting question here is, why did we choose Kinesis Streams over the other obvious candidate, Kinesis Firehose?
Streams vs Firehose: the face-off
| Kinesis Streams | Kinesis Firehose | |
| Scale |
|
|
| Cost |
|
|
| Provision |
|
|
| Data storage |
|
|
| Processing |
|
|
While the decision isn’t necessarily especially clear cut, there are a number of reasons we could feel comfortable going with Streams:
- You get near real-time processing
- It’s easy to implement in a processing pipeline
- You can control scale by adding more shards
We went with Streams, and we were happy with our decision, and functionality was achieved.
So, what went wrong?

Counting the cost of Kinesis Streams
At Lumigo, cost is always monitored, at some point we discovered that the cost of Kinesis Streams had become too high compared to the total cost of our infrastructure, which includes production, development, staging and integration environments.
The good news was that the main reason behind this issue was simply that the company was growing, with more customers, and therefore more data to process.
As we scaled, system behavior was also changing. Suddenly, system data processing throughput was less predictable and we had more and more spikes which we needed to handle.
When you’re faced with handling an unpredictable throughput of data you have two good options:
- Autoscale
- Overprovision
The log processing flow uses two AWS services, Lambda and Kinesis. But while Lambda autoscales by design, Kinesis Streams is a bit more complicated.
Kinesis Streams – auto-scaling vs overprovisioning
Auto-scaling Kinesis is possible but it brings new challenges. It can’t scale instantly, and you won’t get data from new shards till you finish handling data from old shards.
Kinesis overprovisioning is a much more straightforward task. You simply create enough shards, so you have full control over it. The downside, though, is that you pay for all of those shards whether you use them or not.
Despite that, overprovisioning was our eventual choice to tackle our scaling challenges, so the stream was set with 128 shards.
The outcome: real-time but real expensive
As part of the cost analysis we found out that our Kinesis Streams usage had a lower bound of 4 shards and upper bound of 90 shards, meaning that in the worst case we were paying for 124 shards without real demand.
Evidently, overprovisioning was not cheap. The next step was to go back to the drawing board and contemplate our alternatives.
One of the key features of Kinesis Streams is having your traffic processed in real-time.
When designing the system a very common requirement is latency. As a developer it makes sense to optimize your system, and having a fast system is usually better than a slower one.
On the other hand, real-time is usually more expensive!

Weighing up the options: Kinesis Firehose
We’d originally chosen Streams over Firehose for good reason, it offered real-time processing and was simple to scale. But now it was time to revisit our evaluation, because unless you’re working on a passion project in your spare time, cost trumps everything else!
Kinesis Firehose advantages
- You pay only for what you use.
- It has higher limits by default than Streams:
- 5,000 records/second
- 2,000 transactions/second
- 5 MiB/second
- Overprovisioning is free of charge – you can ask AWS support to increase your limits without paying in advance.
- It is fully manage service
Kinesis Firehose challenges
- No more real-time processing. In the worst case, it can take up to 60 seconds to process your data.
- You can’t directly control Firehose processing scaling yourself. The only way is to submit a support ticket to AWS, and your request can even get rejected.
- There’s no visibility into your Kinesis Firehose configuration, as AWS API doesn’t support it. (AWS Firehose team is working on this functionality for the next quarter).
The main concern for lumigo product was real-time processing but we figured that the business goal could be achieved regardless, so we decided to move to Kinesis Firehose.
You saved how much with Firehose?
After a short period we saw the following outcomes from our decision to switch:
- Firehose cost was dramatically cheaper than Streams constant shards cost, representing a 60%+ saving
- It became much easier to handle traffic spikes by overprovision
- Our batch processing work is done using lambdas, firehose optimizes the lambda work by creating a bigger bulk of data to process, in our case our the overall processing duration time of the lambdas was down by 30%.

Two is better than one: Streams and Firehose together
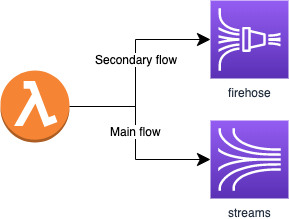
One of the byproducts of the research and testing that we did to achieve those results is that we began to utilize a design pattern with Firehose as a secondary flow to Streams (see below).
In this case, Kinesis Streams is used as the main flow, providing a solid workflow 90% of the time, and Kinesis Firehose can be used for that 10% of the time when Streams is throttled as a result of traffic spikes.
By using Kinesis Firehose as a backup pipeline we gain overprovisioning of our system free of cost. It does mean that we might have some traffic delays compared to the main flow when traffic spikes, but in our case the resilience of the system was the most important consideration for our business.
Summary
Serverless is so much about the managed services – the real building blocks of a serverless system. As developers we are focused on the code that we write, so it can require a shift in mindset to focus on services that are largely outside of our control.
Whether our goal is scalability, cost efficiency, real-time processing or something else, there are always choices to be made, not only between services but also in how we utilize and configure those services.
In this case of serverless cost optimization, we weighed up the various priorities of the data processing flow – latency, scalability and cost – and made an architectural decision to switch to Firehose instead of Streams. If the balance of our priorities had been different we might have settled on Streams. Both are great services, each offering its own advantages, whether you choose one over the other or utilize them in unison.
