










Lumigo VP Product Avishai Shafir rounds up the most interesting talking points from the three-day Serverless Architecture Conference, held in The Hague, Netherlands.
I had the privilege of attending and presenting at the Serverless Architecture Conference in the Netherlands. It’s a three-day event dedicated to serverless technologies with speakers from all over the world.
The second day started with a keynote session led by Sebastian Meyen from Software & Support Media and with a panel of four experts, Google’s Nikhil Barthwal, Niko Köbler of www.n-k.de, Ory Segal, CTO of PureSec, and Christian Weyer of Thinktecture.

After Sebastian had kicked things off with some (always useful) definitions relating to conference topics, the panel launched into a wide-ranging discussion.
Some highlights:
Serverless + DevOPs = ?
Discussions around the relationship between serverless and DevOps always have the potential to get interesting. The general notion here was that DevOps is a transition path as, down the road, infrastructure will be provisioned as code. An organization that begins simply by relabeling their Ops team as DevOps will eventually change their way as serverless introduces them to the real idea behind DevOps – infrastructure as code.
Christian Weyer talked about the concept of simplicity. Serverless is all about simplicity and it’s the natural progress of the DevOps. He added that we will need much more emphasis on monitoring of the new environments as problems will arise and teams will need to be able to quickly understand the root cause of problems.
Containers and Microservices can live apart
The next discussion was around the usage of containers and microservices, as they are often related as coupled technologies. The forum emphasized that there is no dependency between them. Containers are an efficient deployment method, while microservices is a development methodology. You can have either one without the other, as the decision to use is based on the use case.
Vendor Lock-In: Overstated and Worth It
Another ever contentious topic is cloud vendor lock-in. Is serverless accelerating us towards vendor lock-in? The panel said no, your functions can be deployed on any environment, and it is simple to move the functions between environments. On the other hand, when you store data and build a full application utilizing managed services of a specific cloud provider then inertia is likely to set in. However, everyone agreed that it is not a bad thing – in order to move fast there is a “penalty” of some locking, but the benefits are much greater than the disadvantages.
Knative – Essential components for building serverless applications on Kubernetes – Nikhil Barthwal (@nikhilbarthwal), Google
Nikhil shared some of the work Google, Pivotal, SAP, red-hot, IBM and others are doing around Knative.
Knative is a serverless environment built on Kubernetes. It can be deployed in the cloud or on-premise when needed. As Kubernetes is a standard platform supported by all major cloud vendors it reduces the vendor lockdown (though you are locked to Kubernetes). Kubernetes has a huge community today. Developers want to focus on code, have freedom of language and not managing the infra. Operation teams want something to ease orchestration, and management of the infrastructure environment. DevOps concept is here to ease the tension between the two needs. The more you change the code in a highly invoked environment, the more likely it is to break. So Dev wants to change quickly and often, and Ops want to slow things down to have better control. Knative helps to achieve the best from both worlds.
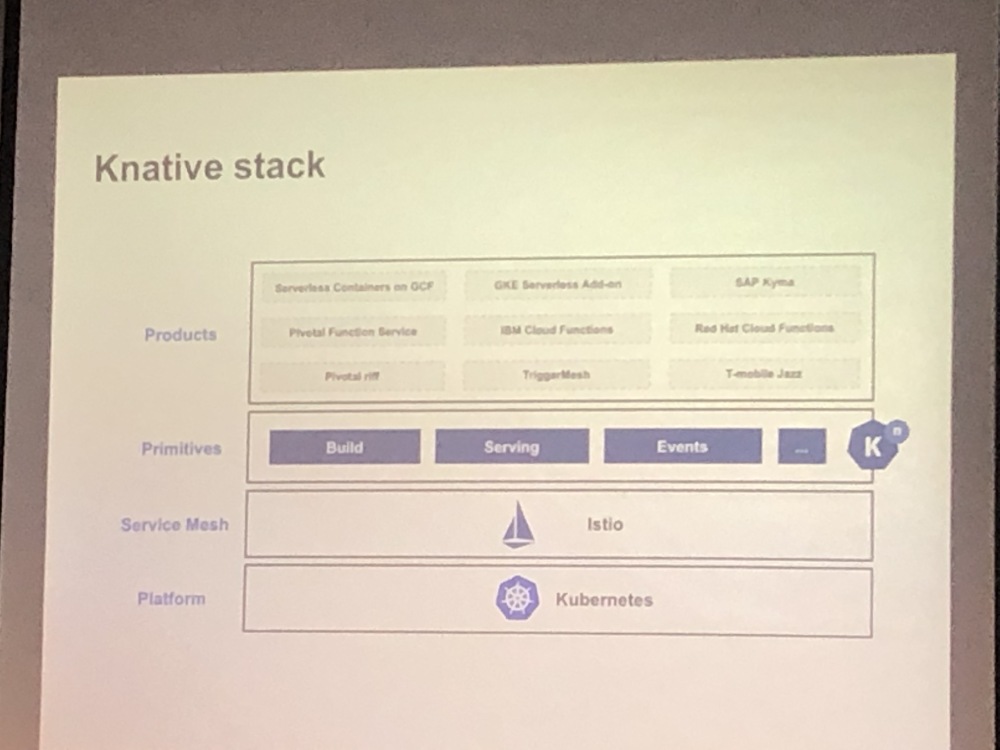
Knative works looks like a very interesting solution if portability or on-prem deployment are important requirements. Although there is a lot of work on this environment, it is still lags behind AWS and Azure environments, but it looks very promising. My take is that this fits more to organizations that are heavily relying on Kubernetes as a transition path to real serverless that offers an improved velocity and focus on business logic (alongside security and cost optimization). There is room for both approaches as different use cases might fit better to one or the other.
Serverless security: your code, your responsibility – Ory Segal (@orysegal), Puresec

Serverless security is all about application-level security. The cloud provider is responsible for securing the underlying infrastructure but it does not handle application-level security. This is something that is not likely to change. When looking into the different security activities needed for an application we can see that the cloud provider is covering 52% of the responsibilities and the application owner 48%. This is much better than the past when the organization was responsible for 92% of the security compliance topics.
The attack vectors in a serverless environment are mostly around event-data injections, unauthorized deployment, and dependency poisoning.
In traditional applications, the security controls are deployed on networks and servers. Serverless introduces a new challenge and the application owner should apply the needed security controls. Either way, traditional security solutions have become unsuitable for the serverless world.
Serverless! But multi-cloud – Niko Kobler (@dasniko)
In his talk, Niko challenged the perceived need for teams to use multiple cloud vendors at the same time. The main reason organizations are pushing for a multi-cloud environment is to avoid vendor lock-in. Niko argues against the common claims against single vendor and showed that working in a serverless environment – even if it forces a level of vendor lock-in – is much more beneficial to teams than the fear from the challenge. He continued with live code examples of how workloads can relatively easy to be migrated.
Serverless Vs. Organizations – Soenke Ruempler (@s0enke
Serverless is a shift in mindset and teams needs to learn how to work in this new environment and forget old habits that hold back the change. Soenke shared different tactics from the field of knowledge management on how to unlearn old practices and learn new ones.
The second day started as strongly as the first day ended, so let’s dive in.
Scalability Myth Busters – Mikhail Shilkov (@MikhailShilkov)
Mikhail, of Prodrive Technologies, started by declaring that the scalability issue has two main points:
- Throughput
- Latency
And when cloud vendors debate how many resources to allocate for each of the above two they need to decide upon their tradeoffs: customer value vs cloud utilization.
Mikhail shared interesting data points on AWS, Azure, and Google comparing time for cold starts, and the time required to scale up when needed. I’m sure he’ll share his presentation in the coming days and I think everyone should have a look and better understand how serverless applications behave.
He continued with an explanation of how each cloud vendor manages the underlying technology for the infrastructure. Basically, they all use a dedicated VM for each workload. He continued with a brief explanation of how the cost is calculated.
Serverless Microservice Patterns for AWS – Jeremy Daly (@jeremy_daly)
Jeremy is firmly established as one of our community cloud heroes, and his first session was as interesting and educational as you would expect, as he took the audience through common design patterns for serverless microservices.
- The simple Web Service
- The Gatekeeper
- The scalable webhook
- The internal API
- The internal handoff
- The FIFOer
- The Strangler (two versions for that)
- The read heavy reporting engine
- The Fan out/ fan in
- The Eventually Consistent
- The Circuit Breaker
- The Notifier
- The event fork
As you can see, he covered a lot of ground and shared his experience on when best to use each and why. He concluded the talk with his opinion of best practices, which are worth including here in full:
- Services should have their own private data
- Services should be independently deployable
- Utilize eventual consistency
- Use asynchronous processes whenever possible
- Keep services small, but valuable
You can find his slides for the talk here.
Following Jeremy’s talk I had the honor of being part of a panel of presenters as we took questions from the floor.

Is serverless ready for front-end ?
The first question was whether the serverless methodology is good for backend processing only or if it fits front-end as well. The consensus on the panel answer was pretty conclusive. Serverless is an excellent fit for front-end development for most use cases. It’s event-driven, short duration. One needs to make allowances if there are special latency needs for the application and consider whether to keep some functions warm. But the cost of keeping some functions warm is low.
Switching to serverless
The next question was about the best path to move your development team from older methodologies to become an efficient serverless dev team. The suggestion: start small. Create one or two serverless champions and let them start with the research and learning, develop the team practices, how to manage the code, build the CI/CD, define the testing methodology. Once the basics are set, gather the team and share the findings and the chosen methodology and then the team can gradually start moving toward the new practices. There was a consensus among the speakers that there is no real logic to migrating working workload to serverless just for the sake of adopting the methodology. Keep your existing workflow as it is and start developing new functionality with the new methodology, making sure everything plays nicely together.
Building resilient serverless systems with non-serverless components – Jeremy Daly (@jeremy_daly)
The last session of the day was by Jeremy Daly about serverless resilience. As he did in his first presentation, Jeremy shared different use cases and suggested simple tactics to overcome the challenge in order to ensure system resilience and avoid lost updates and messages. When the event recording is published (it’ll probably take a couple of weeks to upload everything), I strongly recommend watching this recording. Extremely valuable.

That was it. Another great conference on serverless came to an end. As always I feel I learned a lot, even during my personal session, as the discussion with other practitioners exposed me to challenges I haven’t yet faced, and we were able to brainstorm together for good solutions based on past experience and new technology. I was invited to present at one of the biggest developers conferences in Romania, so I’m looking forward to continuing the serverless discussion with more developer communities.