










AWS Lambda execution lifecycle has 3 main phases: initialization, invocation, and shutdown.
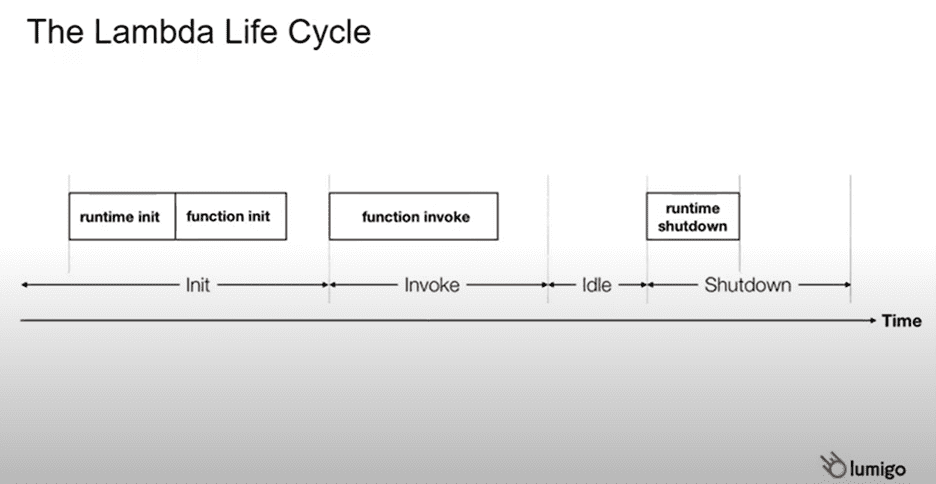
In the initialization phase, a Lambda creates the runtime environment, downloads the code, imports everything needed, and runs the functions initialization code.
In the invocation phase, the Lambda will get an input, process it, and produce an output. After the invocation phase, Lambda will go to an ideal state and wait for the next input. Finally, the Lambda will move to the shutdown phase once idle time exceeds a threshold time.
In the shutdown phase, all the connections to the Lambda will be closed, allowing the runtime shutdown.
However, we can add more capabilities to the above phases by using Lambda extensions. There are 2 types of Lambda extensions available: external extensions and internal extensions. Here, we will only cover the use of external extensions.
Before that, consider a simple use case that requires Lambda extensions.
Use Case: Log Shipper
Let’s assume that we need to ship all of our Lambda logs. Usually, all of the logs of Lambda executions go to AWS CloudWatch. Now, we want to move all those logs somewhere else, maybe a third-party tool. Also, we can’t limit this log shipper to a single runtime since sending logs can happen anywhere. So, it is important to build a cross-runtime log-shipper without touching the Lambda function itself.
Here is what we are going to build:
First, we need to listen to all the logs during the invocation phase. Then we need to execute an aggregation logic since writing a single record each time is not efficient. Finally, we can send the aggregated records to an S3 bucket. Note that there are different types of aggregations that we might want to do: by invocation, by time, or by size. We should allow them all by configuration.
Goals:
Listen > Aggregate > Export
Cross runtimes
No latency impact
Bulletproof
We can achieve all of these goals using Lambda extensions. We will only have to write the extension once to run in multiple runtimes. There will be no latency impact, and it will take the same duration to execute the Lambda—even with an extension. Also, the Lambda function will work as expected, even if the extension crashes due to an error.
So, let’s see how Lambda extensions work.
Lambda External Extensions
An external extension is another process in the same Lambda container that allows you to add new code in every single life cycle phase.

As discussed earlier, Lambda initializes everything required for the execution in the initialization phase. So, it will initialize the extension during the initialization phase as well. As an example, if we want to initialize some kind of connection to a third-party tool, Lambda will wait until the extension says that the third-party initialization is complete. This behavior ensures a good sync between all the phases between the Lambda itself and the extension.
In the invocation phase, AWS will send an event to the extension to notify that the invocation phase was started. Then, the extension will start its process. In this case, it is aggregating the logs. In addition to that, there is a special period within the invocation phase called post-execution time. Lambda will finish its processing before the post-execution period starts, and it gives the extension the necessary time to complete any additional processes without affecting the Lambda execution duration. So, in our case, all the aggregations and uploading to the S3 bucket will happen within the post-execution time.
Finally, in the shutdown phase, Lambda will give you enough time to close everything you need, including sending the last logs or closing any third-party connections.
Building Your First External Extension
An external extension is an executable that sits somewhere in the correct hierarchy inside the Lambda container. Lambda service knows to execute this executable as long as you put the executable file in an /opt/extensions directory.
When AWS executes the Lambda code, the extension needs to do two things. First, it needs to register by saying that it is an extension and expects to get this and these events. The second thing is to tell the AWS service that we’re finishing our process of this specific phase. So, for example, if we are in the initialization phase, we want to tell that we are finished in the initialization phase, and we can go to the invocation phase.
In this example, I will show how to build a Lambda extension using Node.js following the above 2 steps.
Note: Executables can be any type of executable including Python scripts, bach scripts, etc.
Register:
The first thing that we need to do when registering an extension is to send an HTTP request to AWS and tell them that this is an extension and it needs to be registered.
Then we need to tell AWS the specific events that need to be registered for the extension. For example, you can register for the SHUTDOWN event to get notified when the container shutdowns.
Similarly, you can register to INVOKE event to get notified whenever there is a new invocation.
After that, we need to inform the extension name to AWS. Here, you need to ensure that your extension name and the executable file name are identical. If not, the runtime will not identify it as an external extension.
The below code shows how we can set up the above steps using Node.js:
const red = await fetch(‘http://${process.env.AWS_LAMBDA_RUNTIME_API}/2020-01-01/extension/register’, {
method: “post”,
body: JSON.stringify({events:[“INVOKE”, “SHUTDOWN”]}), // Register to events
headers: {“Lambda-Extension-Name”:”file-name”}
});
return res.headers.get(“lambda-extention-identifier”);
Ready:
In this ready step, we need to store the response from AWS, which contains your unique identifier. With this unique identifier, we can send another HTTP request to /eventnext endpoint to tell the Lambda service that the current phase is finished and the extension is ready for the next phase.
const red = await fetch(‘http://${process.env.AWS_LAMBDA_RUNTIME_API}/2020-01-01/extension/event/next’, {
method: “get”,
headers: {“Lambda-Extension-Identifier”:extentionId}
});
This request is a blocking request, so we will not get any CPU until this request gets a response and this is where we will wait for the next phase.
Note: the above discusses an extension that is not subscribed to logs but different types of events. The API for logs-extension is a bit different, an example is available here: https://github.com/lumigo-io/lambda-log-shipper/blob/main/src/lambda_log_shipper/logs_subscriber.py
Be Lazy
You do not need to implement everything by yourself. Some great solutions are already available, and you can easily get started with them.
lambda-log-shipper – Ship logs anywhere. The no-code style.
https://github.com/lumigo-io/lambda-log-shipper
Here, you only have to add an environment variable. Then, all your logs will be shipped to an S3 bucket like magic. This is an implementation of the use case that we described above.
Lumigo’s Auto instrument
https://github.com/lumigo-io/lumigo-node
This extension extracts different events from Lambda itself, including whom it communicated, inputs, outputs, and exceptions. Then it sends these records to Lumigo to process them later.
AWS official examples
https://github.com/aws-samples/aws-lambda-extensions
You can also try the official AWS examples that allow you to see different things that you can do with extensions.
Click here to read more on this topic.