










With AWS Lambda, we can deploy and scale individual functions. However, we engineers still like to think in terms of services and maintain a mapping between business capabilities and service boundaries. The service level abstraction makes it easier for us to reason about large systems. As such, cohesive functions that work together to serve a business feature are grouped together and deployed as a unit (i.e. a service) through CloudFormation.
This makes sense when you consider that engineers are typically organized into teams. Each team would own one or more services. The service boundaries allow the teams to be autonomous and empowers them to choose their own technology stacks. Where AWS Lambda is a good fit, a service would be made up of one or more Lambda functions as well as event sources such as API Gateway. The fact that the functions that make up a service are scaled independently is merely an implementation detail, albeit one that can work very well to our advantage.
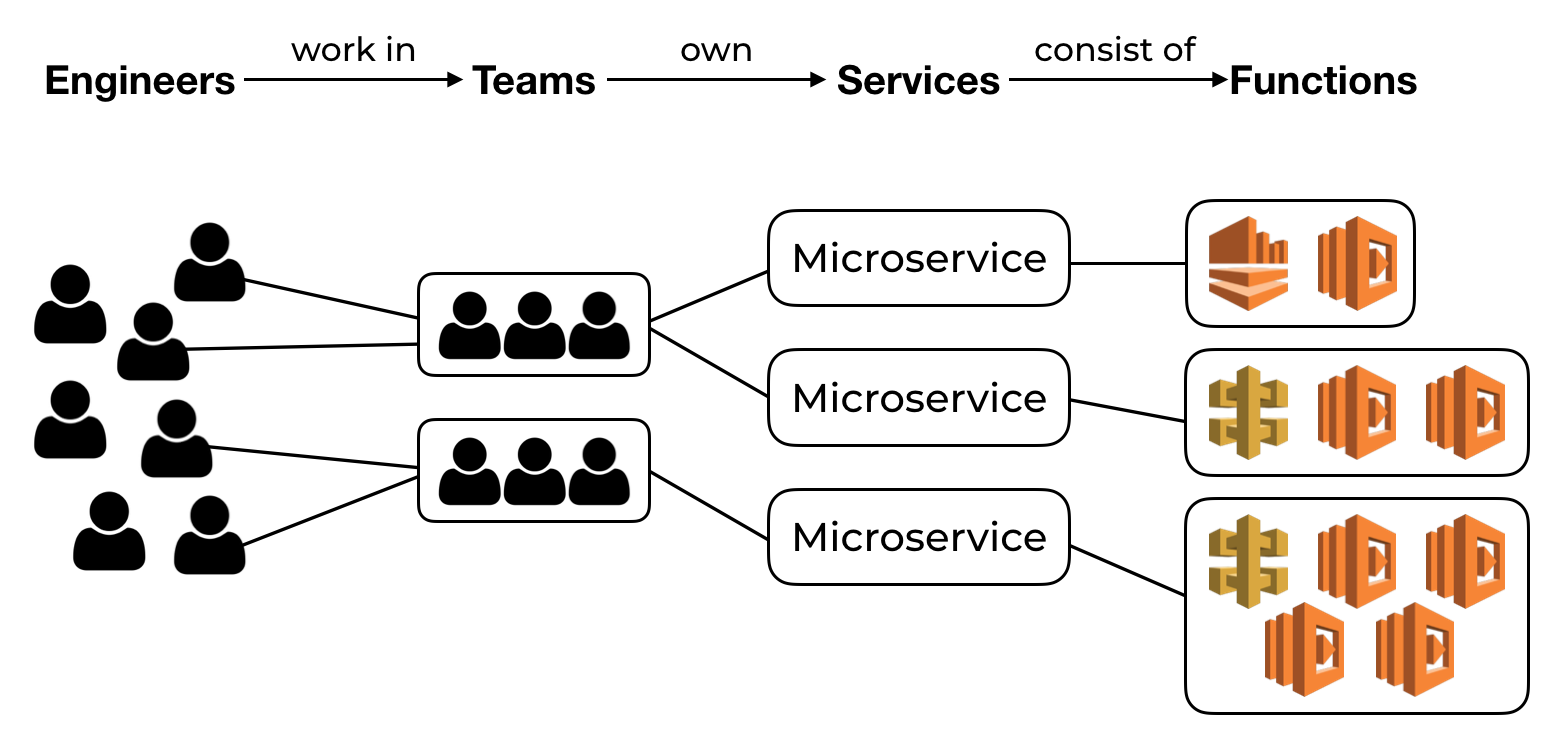
Deployment frameworks such as Serverless or AWS SAM help us configure and deploy our functions in terms of services. In a future post, we will compare the various deployment frameworks on the market today.
In this post, we will address the question of how you organize your functions into repos. We will compare two common approaches:
- Monorepo: everything is put into the same repo
- One per service: each service gets its own repo
We will then offer some advice on choosing which approach you should consider for your organization. This topic is not specific to serverless, or any technology for that matter. On both side of the fence you will find organizations using the same stack – JVM, .Net, containers, AWS Lambda, on-premise, and so on.

Monorepo
Before we delve into it, I should clarify that within a monorepo you can still deploy services independently. You simply cannot fit every project into a single CloudFormation template given the 200 resources limit. Instead, functions are still organized into services, and each service would reside within a subfolder in the repo.
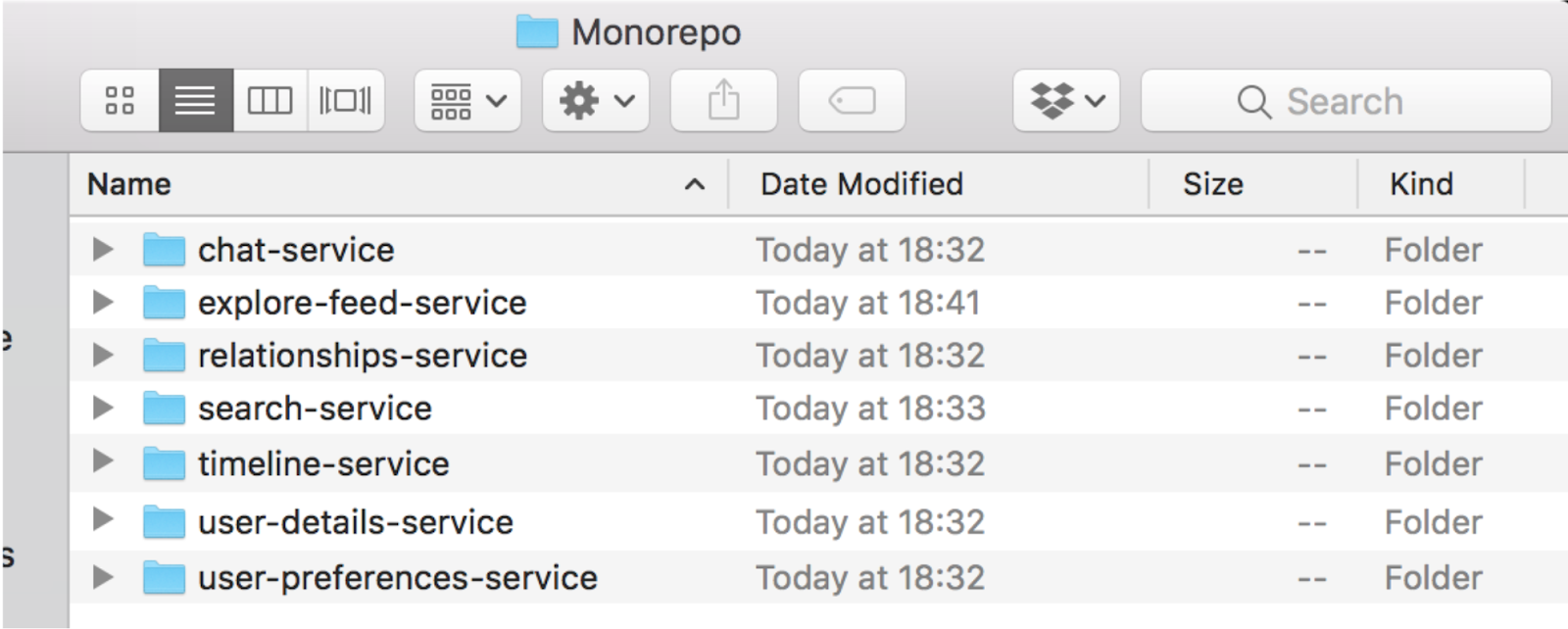
This is the approach employed by many of the big tech companies – Google, Facebook and Twitter to name a few. Outside that rarefied circle, this approach is often frowned upon or even ridiculed. However, it does have many proponents, including Dan Luu, who wrote up a comprehensive list of advantages of monorepos.
As an approach, I think it’s hard to pull off as the number of projects and people grows:
- The amount of knowledge a new joiner needs to acquire grows with the overall complexity of the overall system. Michael Nygard’s post on coherence penalty offers a really good explanation for this.
- It’s easy to create leaky abstractions and therefore accidental coupling between services. Because it’s easy to share code inside the same repo, which has less friction than to share code through shared libraries.
- When sharing code between services this way, it makes tracking changes more difficult. As changes in shared code can mean a change in a service’s behaviour, but it’s hard to correlate these changes outside the service’s folder.
To avoid the pitfalls of the monorepo approach, you need to have strong engineering discipline and support your engineers with great tooling. This is consistent with what I hear from Google and Twitter engineers:
- You need to invest heavily in automation. Without the internal tools these companies have developed, the monorepo approach would never have worked at their scale. Google’s developer tooling division had 1,200 engineers at one point. Although I can’t guarantee the accuracy of this figure, or how much time these engineers actually spent on developing internal tools. Nonetheless, be prepared to invest a non-trivial percentage of developer time on tooling as the organization grows.
- You need engineers who are brave enough to change shared code and create pull requests to hundreds, even thousands of services. If engineers are not willing to do this, then these shared code would end up being duplicated all over the place and create a massive maintenance headache.
Another important question to ask is, “If monorepos present such organizational challenges at scale, why did these companies start with it in the first place?”
The simple answer is that, the monorepo approach is very productive when you are a small team. It removes a lot of the boilerplate and plumbing involved with setting up new repos. Since the number of people involved is small, there is very little coherence penalty. It’s therefore great for small teams to get started and allows them to move quickly. As these companies (Google, Twitter, etc.) all went through a period of rapid growth, it was simply unfeasible to split the monorepo at that point.
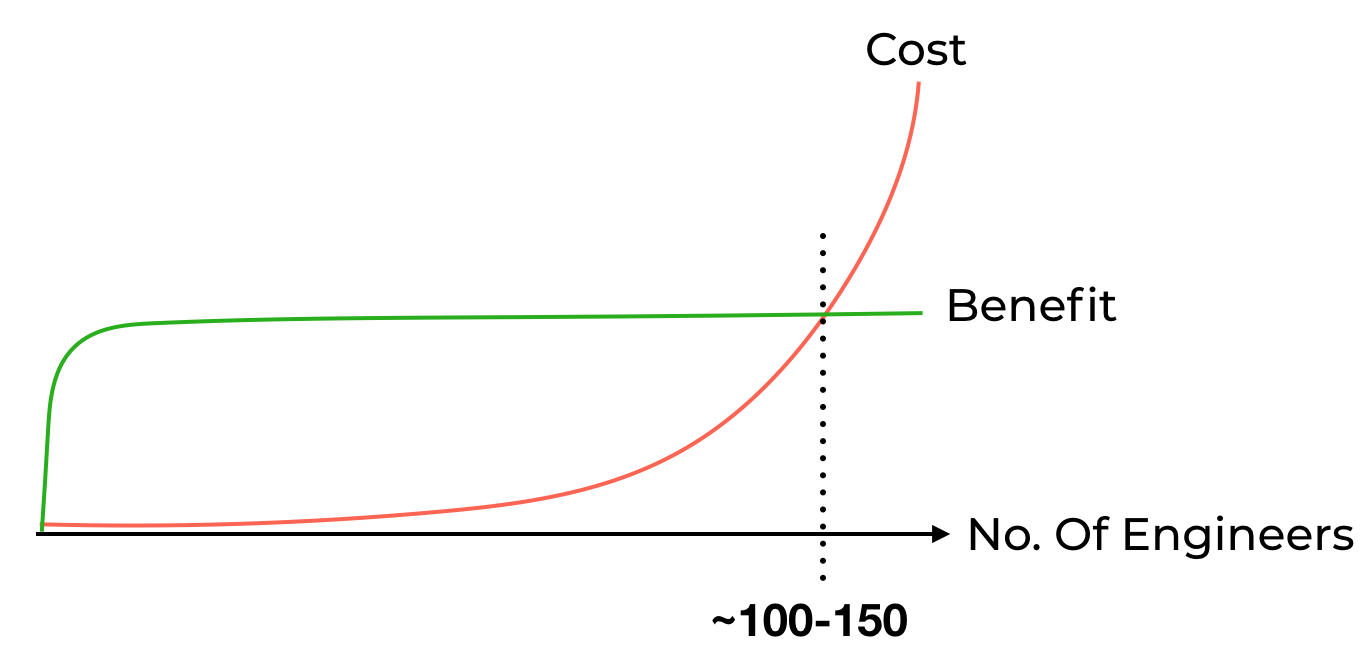
Engineers who have gone through this journey have told me that, the cost of maintaining a monorepo follows an exponential curve. The cost starts to quickly outweigh its benefits after the organization grows to around 100-150 people.

One repo per service
The “one repo per service” is as its name suggests. Every service is put into its own repo, with its own CI/CD pipeline, and corresponding CloudFormation stack, and so on.
A frequently asked question is “how do I share resources between services, and how do services reference each other’s stack output?”. It’s worth pointing out that these challenges are not specific to one repo per service. Unless your system is small enough that everything fits into the same CloudFormation template then you will face the same challenges with monorepos too.
My preferred solution is to manage the shared resources separately, away from the services that depend on them. This can be done with an infrastructure repo, with its own deployment pipeline and CloudFormation template. To allow other services to reference these shared resources, remember to add outputs (ARNs, SQS queue urls, DynamoDB table names, etc.) to the CloudFormation template.
With the one repo per service approach, you do incur the overhead with setting up plenty of new repos. This overhead can be largely amortised with scaffolds and smart defaults. These scaffolding tools are easy to develop and can be shared across the whole organization.
On the flip side, it’s easier to onboard new joiners as they only needs to concern themselves with what’s in the service repo. Shared code is published to package managers such as NPM, and consumers of the shared code can manage their own upgrade path.

Which approach should you choose?
As we have discussed in this post, the monorepo approach offers small teams a great opportunity to gain early momentum. But you need to keep in mind that the cost of this approach would skyrocket as the organization grows beyond a certain point.
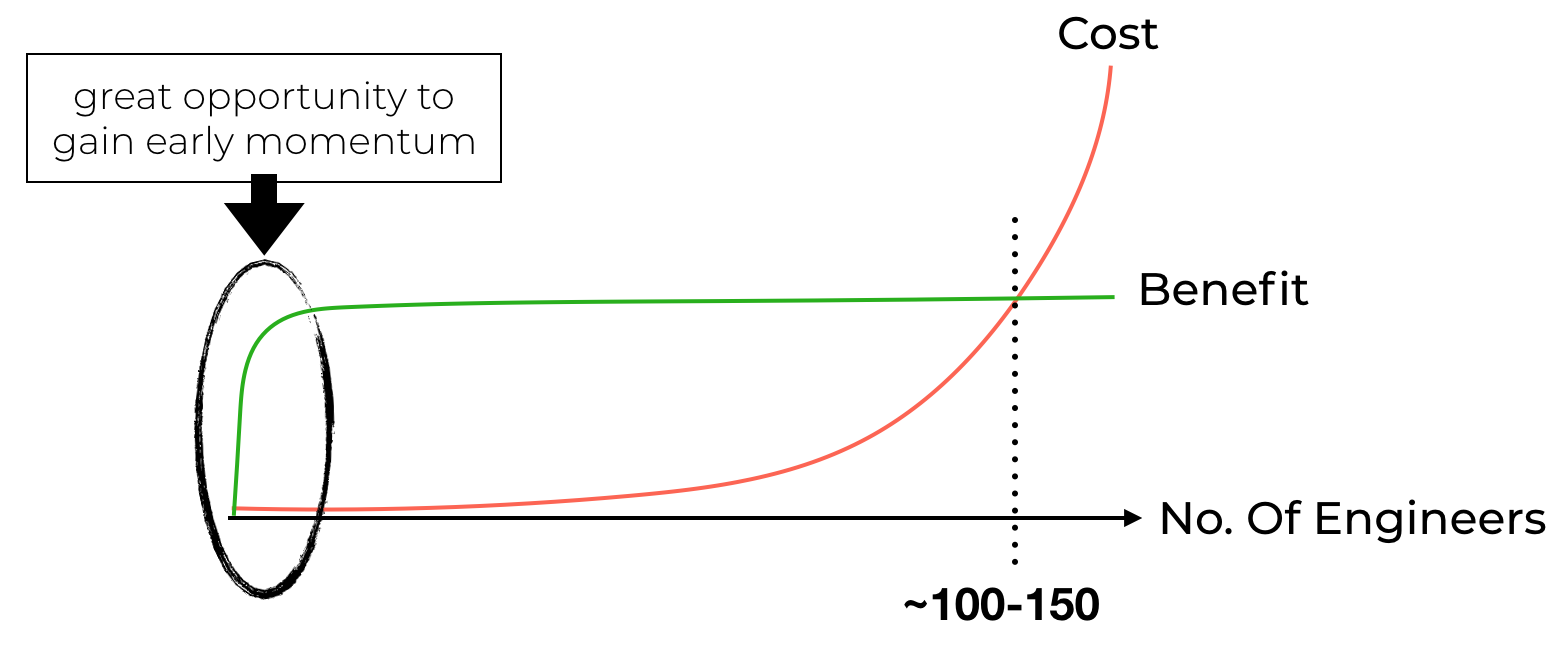
By comparison, the one repo per service approach doesn’t have these extremes. There is a constant and small overhead for bootstrapping new repos, but the approach scales well as the number of engineers goes up.
As a startup, a good approach would be to start with a monorepo. And when the organization grows and the cost of coherence penalty becomes too high, then split the monorepo. However, as discussed earlier, companies that have to grow up rapidly (hopefully due to initial market success!) might never have the time to do this. For example, Uber grew by 500 engineers in a single year around 2015. In the face of such growth, and the market pressure to deliver that goes with it, you likely won’t have the time and energy to also go through with the transition.
With serverless, you have far less infrastructure responsibilities on your shoulders. Most organizations are therefore able to get more done with fewer engineers. Which means you’re less likely to reach the point where a monorepo becomes too expensive to maintain. This also makes the monorepo approach very appealing.
In a nutshell, if you’re a small company that is starting out and velocity is the single most important thing to you then monorepo can be a great fit.
However, the picture can look very different if you’re an enterprise and migrating your existing workload to serverless. You already have lots of engineers and have an establish way of organizing your code.
If you are not using a monorepo already then you probably shouldn’t switch to one at this point. The coherence penalty for switching would be too great, and you won’t have the time to develop the necessary automation tools before your engineers run into serious problems.
Conversely, if you are using a monorepo and experiencing the problems outlined earlier, then you should also consider splitting up the monorepo. While it can be disruptive in the short-term, it might still work out cheaper and less disruptive in the long run. Good automation takes time to develop and mature, and your teams will continue to experience daily disruptions while that happens.
