









“Serverless computing is a cloud-computing execution model in which the cloud provider runs the server, and dynamically manages the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application.”
— “Serverless Computing”, Wikipedia
This mundane description of serverless is perhaps an understatement of one of the major shifts in recent years. As a developer, serverless allows you for the first time in history to concentrate exclusively on what you do best: building your product, without worrying about the infrastructure. So what happens when we take the serverless mindset and implement a CI/CD pipeline with the same approach? A supercharged CI/CD flow.
In this post, I’ll describe Lumigo’s journey to using 100% serverless technologies in its CI/CD pipeline, including:
- What is the Serverless mindset?
- How we work without QA
- How we help our developers be confident their changes won’t break anything
- How we push changes to our production environment with a “serverless mindset”
- A review of the tools we use locally and in the cloud
Serverless is different
Serverless is different than traditional architectures and that affects the way CI/CD is managed. Serverless applications are distributed, often with hundreds of components. As a result:
- It’s difficult to orchestrate building serverless environments from scratch each time, especially when you need to instrument the environment for the first time.
- A multitude of components usually entails frequent deployments
- Many components can’t run on a regular Linux machine. SQS, SNS, and Kinesis, for example, are AWS services for which we don’t have a container, only partial mocks, so they must run in the AWS environment.
Guiding principles of serverless development workflows
When we create a serverless development workflow at Lumigo, three principles guide us:
Principle #1: Personal AWS environments
Serverless requires testing on a real AWS environment, mocks of AWS services don’t cut it. Originally we used a shared environment in which each developer used a different prefix to identify their resources. For example dev_john_<lambda_name> but very soon we realized that the developers were stepping on each other’s toes causing problems such as deleting or configuring the wrong resources and being unable to block an account in case it reached its budget threshold.
We quickly moved to an approach in which each developer has a separate AWS environment. with their name, using AWS Organizations to manage it and consolidate billing. In addition, we invest heavily in tools that enable the developers to quickly and efficiently deploy their code to the AWS environment.
Principle #2: Serverless-first
A big part of serverless is the notion that you should outsource everything that isn’t part of the core of your business. We took this mindset and implemented it across our entire technology stack. CI/CD, code quality, security checks — we don’t develop anything that we can outsource in-house.
We will always choose the serverless solution over the non-serverless one. For example, we use Serverless Aurora, not RDS; DynamoDB, not DocumentDB, and so on.
Principle #3: It’s the developer’s responsibility from A to Z
Developers are the sole owners of their developed product, from product management, design, coding, testing, deploying, and monitoring. It does not mean they are the ones who do everything. We have a dedicated product team, but the developers participate actively and have a strong say in the way the product will behave. In addition, we don’t have any specialized QA engineers, instead, all the testing is done by the developers themselves and we invest heavily in testing automation. The same thing goes for our monitoring efforts: the developers monitor the features and bugs they release to production.
A lot of responsibility falls on the developer’s shoulders.
Environments
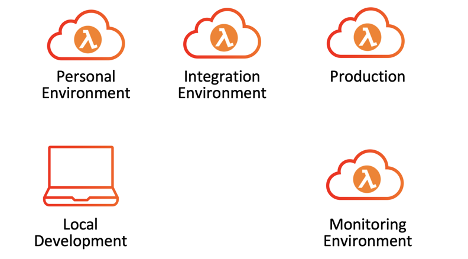
AWS environments in Lumigo do not end only with personal AWS environments. We have a couple of shared integration environments that are part of the automated CI/CD process, and we have two production environments that are composed of an environment our customers use and a monitoring environment that runs our own product that monitors the customer’s environment.
We are eating our own dog food, which helps us both find potential issues ahead of time and sharpen our product. New features have often been added to our product after internal feedback about missing capabilities. We are a serverless power user and we have seen many times that capabilities that were requested internally by our own team were eventually requested by our customers too.
Technical stack
- The bulk of our services are written in Python 3.7, with some additional ones in NodeJS 12
- Jira is our ticket manager
- Github is our source control and code review tool
- Pytest is used for local and integration testing
- Flake8 for linting
- Serverless is our serverless framework
- CircleCI is our CI/CD server
- CodeCov for testing coverage
- Snyk is used for package scanning
- And of course, Lumigo is our monitoring and KPI tool
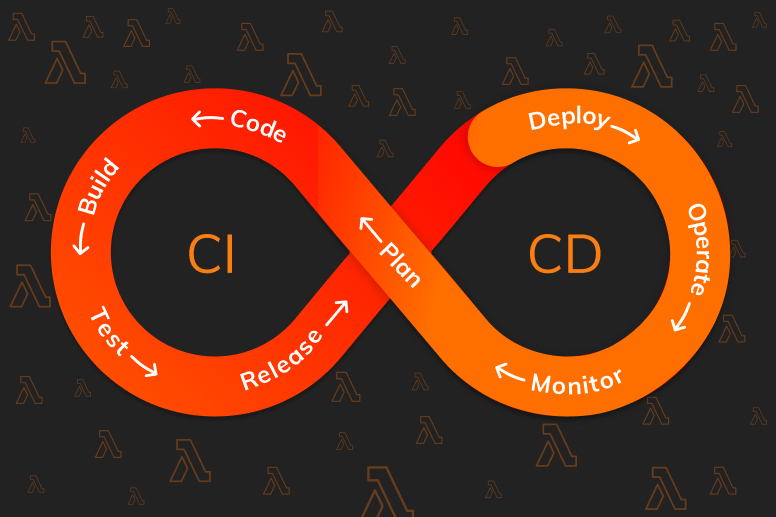
Serverless Development Flow
The famous infinity loop guides us as well in our internal serverless development flow. In this section, I’ll go over each phase and discuss how it affects our development flow.
Plan
When Lumigo just started and we were small we used Kanban to drive our workflow. We had a long list of prioritized tasks and each developer picked the top one. As we grew, management wanted more visibility so we moved to a more traditional Scrum. Now, we use a mix of Kanban and Scrum.
Each of our sprints is a week-long. We keep them short on purpose to keep things moving fast, but we don’t wait for the end of the sprint to deliver. We are very CD-oriented. When a piece of code passes through all of our gates, it’s pushed to production.
Coding
Code storage
We use Github to store our code and the Github flow in which you have only master and feature branches. Each merge from a feature branch to the master means deployment to production.
In the early days, we had a very heated discussion regarding mono vs. multi repo. We chose multi because it was more suited for microservice deployments for the following reasons:
- Each change in the repo means deployment
- It forces the developer to think in a more service-oriented way. You can’t import your DAL library or call regular function methods directly. Instead, you have to use common practices to access remote resources such as API Gateway, Lambda, or queues.
Read more about the mono vs. multi repo issue here.
Linting
Whether we’re dealing with a dynamic or static language, linting is a mandatory step. Lumigo’s linting flow includes:
- Opinionated auto-formatter — something similar to black for Python or io for JS. You shouldn’t work hard to format your code, everything should be done automatically.
- Static type analysis — in dynamic languages such as Python, we run a static type checker such as mypy. With NodeJS, we use TypeScript.
- Static analysis — This is the real “linting” process, we use flake8 for Python and eslint for Node.
We try to run the linting process as early as possible in the build process, and as early as possible means local. Everything is backed into a git pre-commit hook. We use the pre-commit framework, which gives us the ability to run the linting process either manually or in CI environments.
Testing
Orchestrating

The best way to test our code is in an actual AWS environment. In the beginning, orchestrating our code deployment was very manual, but as the number of services grew, as well as their inter-dependencies, a special tool was built internally to orchestrate the deployment. We call this tool uber-deploy.
Uber-deploy enables our developers to easily install these services in their environment, so no one needs to know the various dependencies.
The uber-deploy tool Works like this:
- It pulls relevant code from git, depending on the branch you choose
- It then installs relevant requirements for each service
- It reduces deployment time by installing in parallel the various services according to a predefined order and only those services that changed
Writing tests
As part of feature design, each developer decides which type of tests should be added.
We use three types of tests:
- Unit tests, which the developer runs locally
- Integration tests, which the developer runs on their AWS environment and run as part of the CI in a dedicated environment
- End-to-end testing with Cypress which also runs in the AWS environment.
Because testing in the cloud is slower than testing locally, we prefer to detect as many issues as possible before pushing to remote. As mentioned above, we use pre-commit for unit testing and linting.
Non-serverless resources usually run on a local container so you can easily test your end-to-end flow locally. We tried to do the same for serverless resources, but it didn’t work well.
Why?
- Some services that we use don’t have good mocks. They don’t mimic the true behavior of the service and don’t always include the latest APIs.
- Some mocks’ infrastructures (e.g., localstack) are complicated and require a lot of work.
- Some of these mocks have bugs. It has happened to us more than once that things didn’t work well with the mocks, but we later found out that they work perfectly running on AWS. We prefer not to waste time on debugging mocks.
So as a rule, we don’t use service mocks, we always run things in an AWS environment. However, for local unit testing, we do use moto.
Releasing
Staging
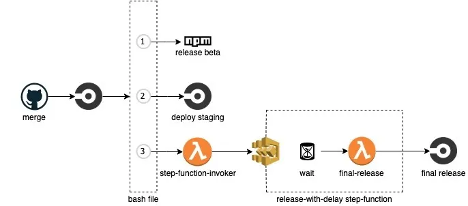
One of our system’s components is an SDK, which our customers need to embed. The SDK is very sensitive and a bug there means the Lambda will crash. So we use one of our internal systems as a staging environment for the SDK. As I said, we believe in eating our own dog food.
We created an automated flow that releases an alpha version to NPM, which is then deployed to our staging environment. After a successful deployment, a step function is triggered which waits 2 hours before making a full release of the SDK. The step function gives us the possibility to stop the deployment at any moment in case we identify an issue.
You can read more about this flow here
Gating
The code was written and we are ready to release, but not so fast. Merging to master means automatic deployment to production. There are several gates the pull request has to pass through before the developer can merge to master. Except for code review, which is a manual process, everything else is automated. Automation includes:
- Unit testing
- Linting
- Integration tests
- End-to-end testing
- Security checks
- Code coverage
Monitoring
Monitoring is hard in serverless for several reasons:
- There are many microservices and you need to track the flow across all of them to get the full story. The root cause of an issue might be anywhere down the stack across multiple services.
- No servers to ssh, and as a result it’s hard to collect the relevant details to better help you understand what’s going on.
- Old monitoring metrics are not good enough. Suddenly disk space and CPU do not play a role, however, a lot of new metrics are added, such as timeouts, cold starts and various latencies.
To address monitoring, and perform root cause analysis, we obviously use the Lumigo platform, a monitoring and debugging tool built from the ground up for serverless. You too can use Lumigo for free — get your free account.
To learn more — join my live webinar
On Wednesday, Feb 24, I’ll be hosting a live webinar in which I go in-depth on using CI/CD with serverless. Please join me! Register here.

Get a free cool serverless t-shirt!
All webinar attendees who connect a Lumigo tracer to their Lambdas will receive one of these cool serverless-themed t-shirts.
