










I have been an AWS customer since 2010 and in the early days I, along with just about everyone else on AWS, spent a lot of my time just managing infrastructure. Patching AMIs, configuring load balancers, updating auto-scaling configurations, and so on. It was the sort of thankless task that no one cared about until something went wrong! The very definition of what Werner Vogel often refers to as “undifferentiated heavy-lifting”.
For the longest time, I hoped for a better way. When AWS launched the Lambda service at re:Invent 2014 and its subsequent integration with API Gateway in 2015, it was a huge turning point for me. I have worked almost exclusively with serverless technologies since 2016. These days, I find myself more productive than ever and the systems I build are more reliable, more scalable and more secure.
But, it’s not a free lunch, and I have had to make many mistakes and learn many lessons along the way. After all, with serverless, you’re building cloud-native applications that utilize the cloud to its maximum potential. To that end, we need to use AWS effectively and develop ways of working that help us get the most of what AWS has to offer.
In this post, let me share with you the five most important lessons I have learnt from running serverless workloads in production for the last five years.
Observability from day one
You can’t build a reliable application if you can’t debug it effectively. Period.
What is observability?
Observability has become a buzzword in the last few years, and to me, it’s a measure of how well the internal states of a system can be inferred from its external output. You know, how well can you tell what your cloud-hosted application is doing at any moment in time?
How much observability you have in your serverless application depends on the quantity and quality of the external outputs you are collecting from it. Outputs such as metrics, logs, distributed traces and so on. And how well you are able to analyze and make sense of these data to identify patterns of behavior and outliers or to troubleshoot live issues.
Logs are overrated
And no, logs and metrics are not enough.
In fact, I have come to the conclusion that logs are overrated. They have their use, but they are hardly the most effective way to troubleshoot problems. Especially when you’re under time pressure to identify and resolve the problem quickly, as is the case with most production outages.
At the best of times, searching through the mountains of log messages can feel like an exercise of finding a needle in a giant haystack. And there’s a long list of challenges and decision points you have to deal with:
- How to make sure everyone writes structured logs?
- How to make sure everyone logs data consistently, e.g.
- naming of fields
- what data to capture – Lambda invocation payload, request and response body for IO calls, duration of IO calls, exception message and stack trace, etc.
- How to capture and forward correlation IDs so you can easily find related log messages? For example, where a user transaction touches multiple Lambda functions chained together via events.
- What log aggregation platform to use? How to forward the logs from CloudWatch?
- How do you sample debug logs in production to keep the CloudWatch cost in check? It’s common for AWS customers to spend 10x more on CloudWatch than they do on Lambda.
It takes a lot of work to build out a logging solution that is both cost-efficient and effective at helping developers understand what is going on in their applications. It often takes having a dedicated “platform” team to build and own these custom solutions. And these in-house solutions often cause as many problems as they solve and create frictions in the organization. Because the people that develop these solutions often aren’t the same people that need to use them every day and don’t experience their pain.
I’ve been there and seen this happen many times…
My observability strategy
Nowadays, I use a combination of:
- Lumigo for the bulk of my debugging and alerting.
- Few, but high-value structure logs to cover the blind spots in Lumigo.
- Metrics and alerts in CloudWatch for system metrics for AWS services such as API Gateway integration latency or DynamoDB user errors. Check out this blog post if you’re wondering what alerts you should set up for serverless applications.

This strategy is simple to set up and works very effectively. Here’s why.
Lumigo has built-in alerts and integration with tools such as Slack or PagerDuty. Combined with the CloudWatch alerts I have in place, I will be alerted as soon as any issues arise.
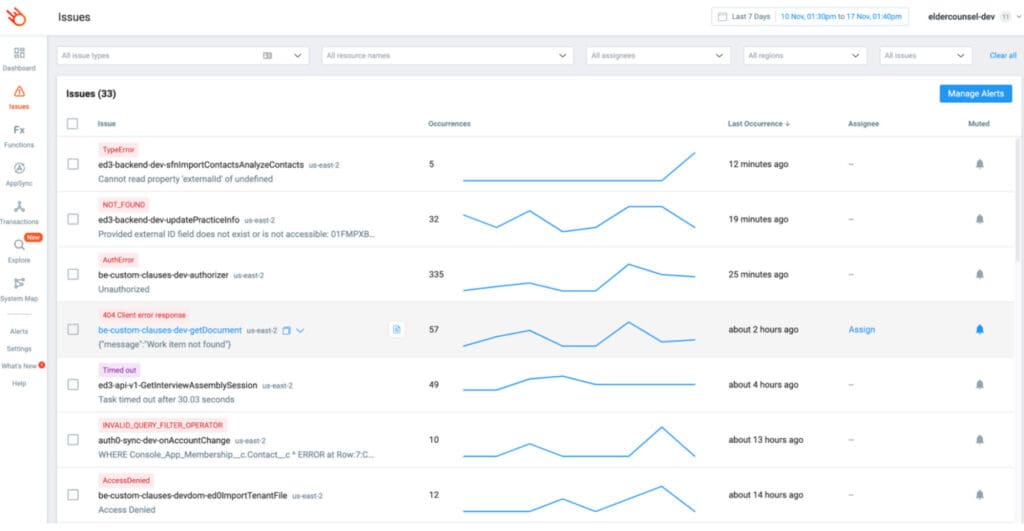
On the micro-level, if I need to investigate a problem then there’s a good chance the problem is already captured in Lumigo’s issues page. Where all the recent issues are organized by function and error type.
Out of the box, Lumigo captures most of the information I will need to be able to infer the internal state of my application:
- The Lambda invocation events.
- Environment variables that were present in the Lambda invocations.
- The latency as well as the request and response bodies for every outbound call (e.g. to other AWS services).
- Error message and stack trace for failed invocation.
These give me a lot of insights into what’s going on inside my application and as such I don’t need to log very much myself. So the only time when I tend to write logs is to cover what I don’t see in Lumigo – when my code is doing complex data transformation or business logic.
Luckily for me, Lumigo shows me my logs side-by-side with everything else, even when the user transaction involves multiple Lambda functions.
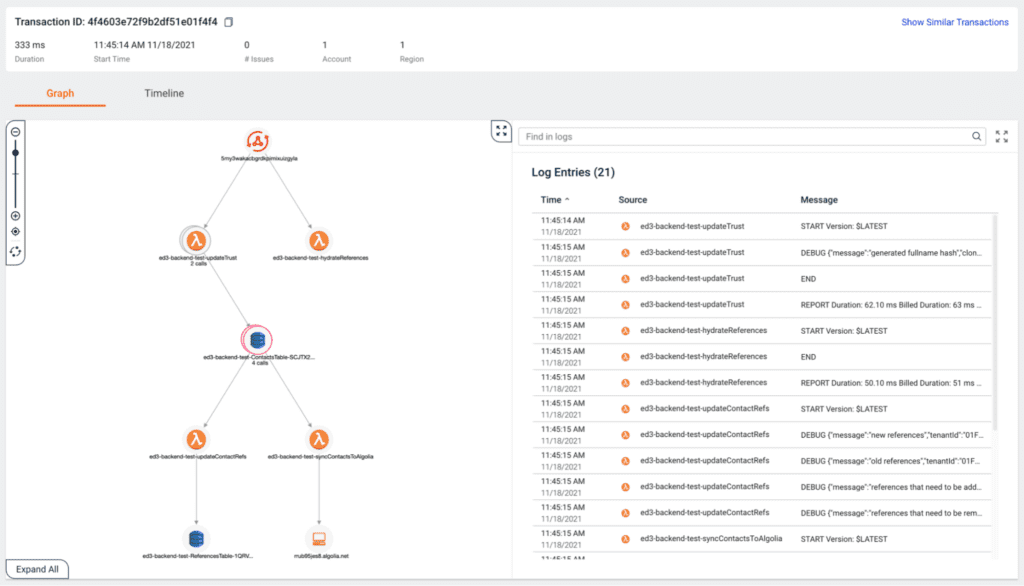
Having all this information in one place and easily accessible makes it much easier to troubleshoot problems in complex serverless applications. And the best thing is that it takes only a few minutes to set up Lumigo, especially if you’re using the Serverless framework and the serverless-lumigo plugin.
There is no manual instrumentation required, and you get a ton of values right away. Of all the things I have learned and adopted in the last few years, this observability strategy has given me by far the most mileage and helped me become a better developer.
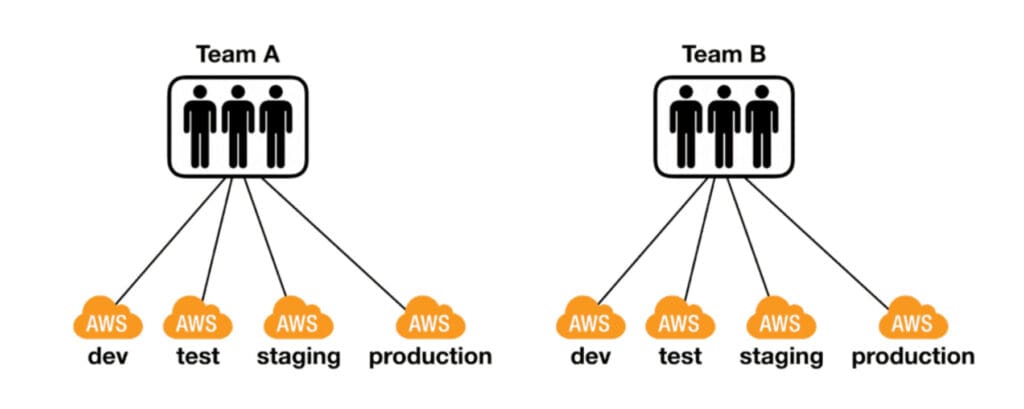
Use multiple AWS accounts
The second most important lesson I can impart to you is to use multiple AWS accounts. Ideally, at least one account per team per environment.
Mitigate AWS Limits
AWS services all have many limits, some are adjustable (aka, “soft limits”) and some are not (“hard limits”). But even the soft limits usually have an upper limit, such as the no. of IAM roles you can have in a region.
Some limits restrict the number of resources you can have in an account. For example, the number of DynamoDB tables or S3 buckets.
Other limits restrict the amount of throughput your application can handle in a region. For example, API Gateway has a default limit of 10,000 requests/second per region, and Lambda has a default limit of 3000 concurrent executions per region.
These throughput limits can have a big impact on the scalability of your application, and they can vary greatly between regions. So you need to know what the limits are for your region and factor them into your architectural design. If you know your production workload demands a certain level of throughput then you should proactively ask AWS to raise the limits for your account.
Having multiple AWS accounts for different teams and environments would greatly mitigate the risk of running into these limits.
Compartmentalize security breaches
Having multiple accounts also acts as bulkheads and can help compartmentalize security breaches. For example, if an attacker is able to gain access to one of your dev accounts, then at least they won’t gain access to your user data in production.
Insulate teams and workloads from each other
Having one account per team per environment lets you insulate each team and environment from others. So you don’t have situations where one team’s service uses up too much throughput and causes problems with other teams’ services.
If a team owns multiple services you might also want to isolate the more business-critical or high throughput services to their own accounts.
Manage many AWS accounting with org-formation
You can use AWS Organizations and AWS Control Tower to help you manage all these AWS accounts you end up with.
But in the case of Control Tower, I find it’s too much clicking stuff in the console. And while it has an account factory feature that lets you create landing zones using CloudFormation templates, this too feels limited. There’s no way to create resources in different accounts and reference them in the same template. CloudFormation, after all, is an account-level service.
This is why I prefer to use org-formation instead. An open-source tool that lets you use infrastructure-as-code to configure and manage your entire AWS organization and its landing zones. It has allowed me to set up complex AWS environments in a few hours on my own, which would have taken a team weeks to accomplish with custom scripts.
If you’re interested in how org-formation works, then check out this webinar we did with its creator, Olaf Conijn.
Securely load secrets at runtime
When it comes to security for serverless applications, there are two really important topics to talk about. The first is how you securely store and load secrets at runtime.
At this point, most AWS users know they can put secrets in SSM Parameter Store or Secrets Manager and encrypt them at rest with AWS KMS. If you want to know how these two services differ, then I have also compared them in this YouTube video.
Where many people get things wrong, is how to make these secrets available to the Lambda functions at runtime.
For example, if you use the ${ssm:…} syntax in the Serverless framework to reference an encrypted secret from SSM Parameter Store or Secrets Manager and assign it to a Lambda function’s environment variable. In this case, the secret would be decrypted during deployment and the decrypted value would be assigned to the Lambda function as an environment variable.
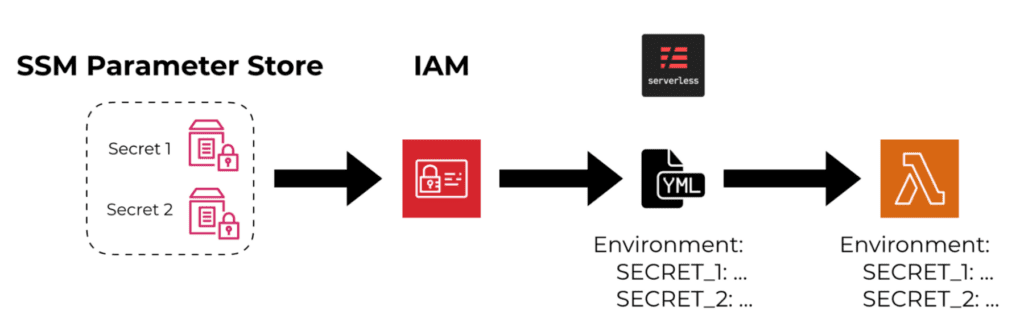
This makes the secret easily accessible to your code at run time. But it also makes it easily accessible to attackers in the event of a compromise because environment variables are low-hanging fruit to them. Historically, many people have put sensitive data in environment variables, including database connection strings and API keys. And this is not limited to serverless or even applications running in the cloud. The problem is prevalent in all walks of software engineering and many attackers would target and steal information from environment variables.
My rule of thumb is to never put secrets in plain text in environment variables.
Instead, you should fetch secrets from SSM Parameter Store or Secrets Manager and decrypt them at runtime during cold start.
To avoid making repeated calls to these services at every invocation, you should also cache the decrypted values (but not in environment variables!). You should also invalidate the cache every so often so you can rotate the secrets without having to redeploy your functions.
For Node.js functions, you can use the middy middleware engine to implement this behaviour through the built-in ssm and secrets-manager middleware. And it only takes a few lines of code!
module.exports.handler = middy(async (event, context) => {
… // do stuff with secrets in the context object
}).use(ssm({
setToContext: true, // save the decrypted parameters in the “context” object
cacheExpiry: 60000, // expire after 1 minute
fetchData: {
accessToken: '/dev/service_name/access_token'
}
}))
Follow the principle of least privilege
The other important security consideration is that you should follow the principle of least privilege and give your Lambda functions the minimum amount of permissions necessary
For example, if your function needs to save data into a DynamoDB table then only give it the permission to do that and nothing else. This is arguably the most important thing you need to do to reduce the blast radius of a security compromise event.

Zero-trust networking
The traditional approach toward network security focuses on hardening around the network boundary. It monitors the traffic going in and out of the network and stops malicious actors from getting into our network.
But inside the network, we have a full-trust environment where everything can access everything else. The risk here is that a single compromised node would give attackers access to our entire system. This renders our security to be as good as the least secure component inside the network.
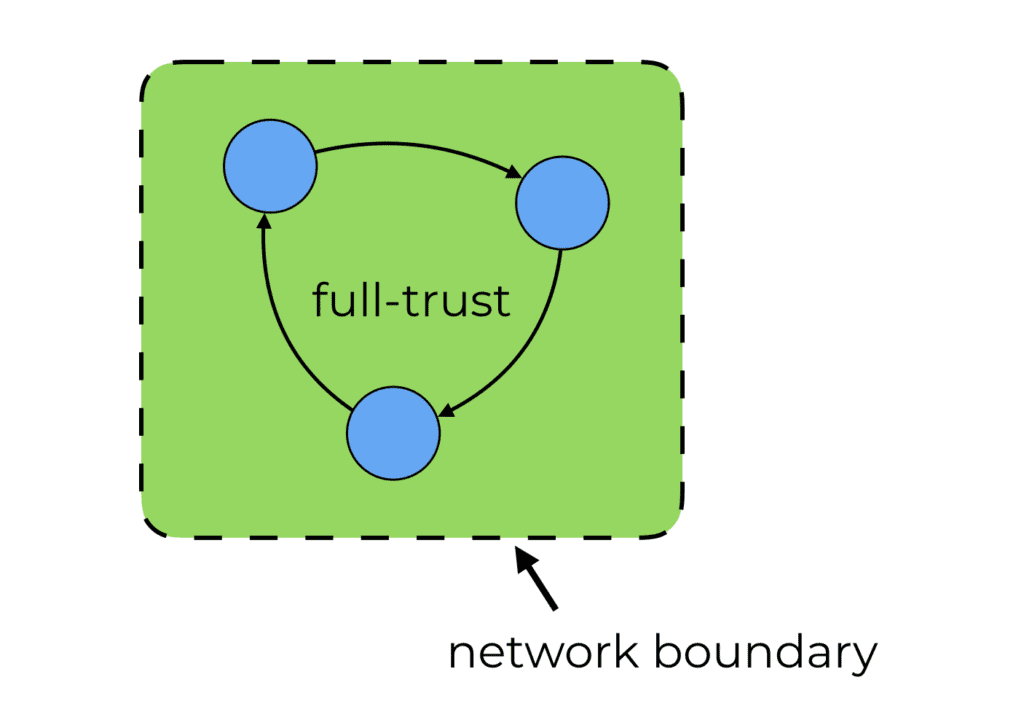
With zero-trust networking, we throw away the notion that anyone inside the network is inherently trustworthy and should be granted access to all our data.
Instead, every request to every system has to be authenticated and authorized.
This means that even for internal APIs that are used by other services in our AWS environment, we still need to authenticate these requests. Luckily, we can do this easily with API Gateway and AWS_IAM authorization. This protects the internal APIs and makes sure the caller has the necessary IAM permissions to access these APIs.
You should still use VPCs (where it makes sense) and apply traditional network security practices as an extra layer of security. But they shouldn’t be your only defence against malicious traffic.
Optimize cold starts
When it comes to performance for Lambda functions, cold starts are the first thing that pops to mind.
The good news is that with Provisioned Concurrency, there is a native solution that can mitigate cold starts in most cases. I covered the use case for Provisioned Concurrency extensively in this blog post and it’s a feature that I was, and still am, very excited to have as an option.
The bad news is that it’s not a free lunch and comes with its own drawbacks:
- In low throughput scenarios, using Provisioned Concurrency can significantly increase your Lambda cost because you’re paying for up-time as well as invocations.
- Provisioned Concurrency is subtracted from the available regional concurrency (which, as we mentioned above, starts at 3000 in most regions). Which necessitates careful concurrency management to ensure you have enough concurrency for other functions to scale into on-demand.
- Provisioned Concurrency doesn’t work with the $LATEST alias so you likely have to work with custom aliases.
For these reasons, Provisioned Concurrency is best considered as a solution to address specific problems rather than something that you should use by default.
In my opinion, you should first try to optimize your Lambda function’s cold start performance so it’s within acceptable parameters. And only when that proves unfeasible should you consider Provisioned Concurrency as the solution.
In this blog post, I explore three ways to improve Lambda performance including some tips on how to improve Lambda cold starts:
- Remove dependencies that you don’t need. Smaller deployment artefacts make faster cold start times.
- If many of the functions (in the same project) require different dependencies, then consider packaging them separately so each has a smaller deployment artefact.
- For Node.js functions, using a bundler such as webpack can reduce module initialization time (because it removes many sys IO calls whenever you require a module).
- Putting your dependencies in a Lambda layer. But do this as a deployment optimization, don’t use Lambda layers as a package manager (here’s why).
These tips are not groundbreaking and you might have heard many of them before. They might be boring, but they are effective. If doing all of these is still not enough, then consider using Provisioned Concurrency!
Wrap up
So these are the five most important lessons that I have learnt from running serverless in production:
- Think about observability from the start.
- Use multiple AWS accounts.
- Don’t put secrets in plain text in environment variables.
- Follow the principle of least privilege.
- Monitor and optimize Lambda cold start performance.
Many of these lessons are applicable to any application running in AWS, not just serverless. And I hope these lessons help you make better use of AWS and serverless technologies and hopefully, avoid some of the mistakes I had to make along the way!