










AWS introduced Lambda Layers at re:invent 2018 as a way to share code and data between functions within and across different accounts. It’s a useful tool and something many AWS customers have been asking for. However, since we already have numerous ways of sharing code, including package managers such as NPM, when should we use Layers instead?
In this post, we will look at how Lambda Layers works, the problem it solves, and the new challenges it introduces. And we will finish off with some recommendations on AWS Lambda use cases in which to use it.
In this article
How does Lambda Layers work?
If you have logged into the Lambda console recently, you might have noticed this “Layers” section just under the function name.
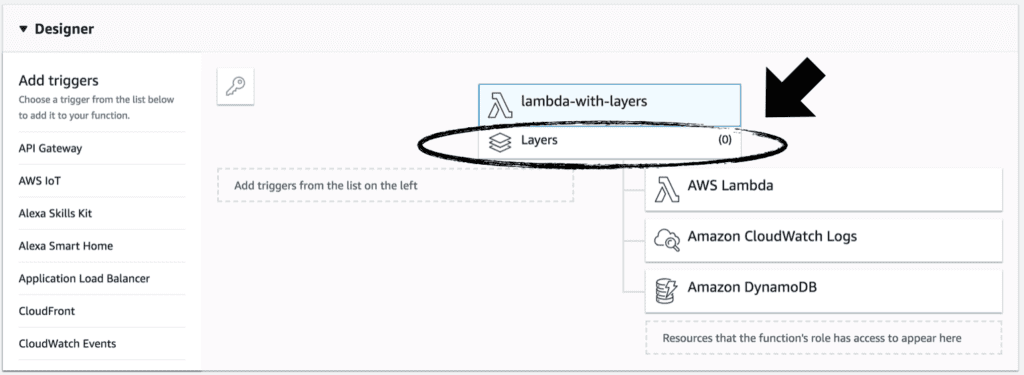
You can add up to five layers. The console will list layers in the current region of your AWS account, which are compatible with the function’s runtime.
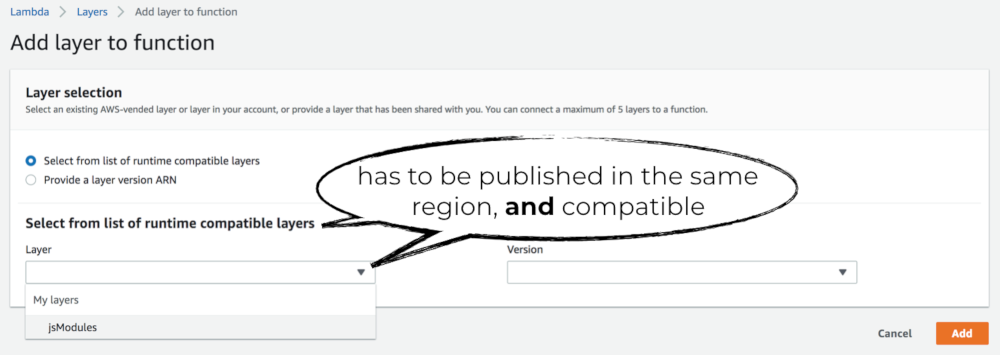
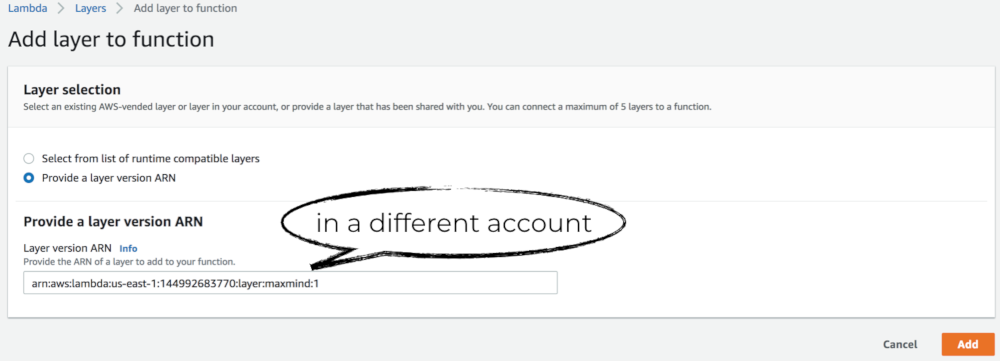
Alternatively, you can enter the ARN for the layer directly. This ARN can point to layers in a different AWS account (but has to be in the same region). This allows you to use layers published by third-party vendors.
The content of the layer would be unzipped to the /opt directory in the Lambda runtime. For example, if you are using the Serverless framework to publish layers, then the content of the maxmind folder (see below) would be mapped to the /opt directory.
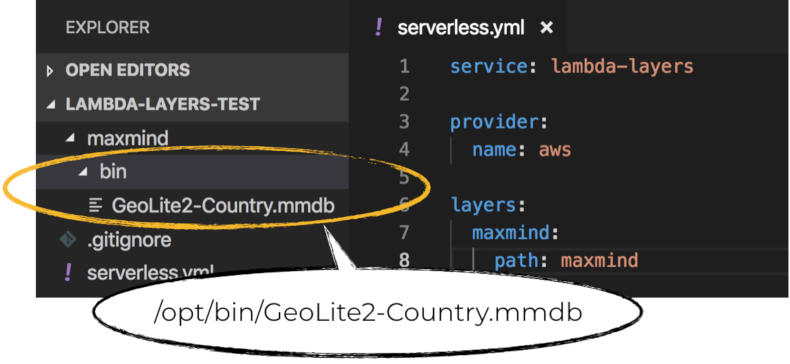
You would then be able to load the MaxMind database file as follows.
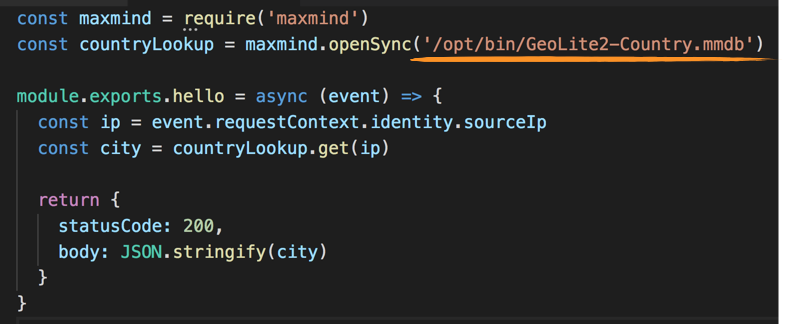
When a new version of the layer is published, you would need to deploy an update to the Lambda functions and explicitly reference the new version.

Layers introduces new challenges
Although they have some fantastic uses (more on this later), Lambda Layers also introduces new tooling challenges and requires additional security considerations.
Harder to invoke functions locally
Having dependencies that only exist in the execution environment makes it harder to execute functions locally. Your tools need to know how to fetch relevant layers from AWS and include them in the build process before executing the functions locally. At the time of writing, AWS SAM is the only framework that supports layers when invoking functions locally. Before invoking a function, the SAM CLI would fetch the layers and cache them. The content of the layers would then be available in the container SAM uses to invoke the function with.
Harder to test functions
You need to mimic SAM’s behaviour when testing your functions with unit tests and integration tests. As part of the set up for these tests, you can use the AWS CLI or AWS SDK to download the layers in question. But this adds a lot of complexity to our tests.
Alternatively, you can mock or stub the layers during these tests. But that’s not the same as actually executing your handler code with the layers. When we write our handler code, we make assumptions about the behaviour of code we depend on via layers. The same assumptions are used to create the mocks and stubs. The tests therefore cannot tell us if our assumptions are wrong! They become a self-fulfilling prophecy.
Doesn’t work well with static languages
For static languages such as C# and Java, the compiler needs to have all the dependencies at hand before it’s able to compile the DLL or JAR respectively. This means you have to have the layers locally to be able to compile your project.
While it’s possible to load additional DLLs or JARs at runtime, you lose the static guarantees and intellisense support when you do this. This practice is also not idiomatic to these languages and not how developers would like to work.
Dealing with changes in the layer is not straightforward
When a layer is deleted, functions that were deployed with the layer would continue to work. However, you would no longer be able to update this function. This is the case even if the layer is still available, but the specific version you depend on is not.
Imagine you are in a situation where you need to apply a hotfix to a function in production. How infuriating would it be if you were stopped in your tracks because of something completely unrelated to the hotfix itself… I know, I have been there many times before! This is especially likely when dealing with systems that haven’t been updated for a while.
With layers, this is a risk that you need to consider, especially when dealing with third-party controlled layers where you have no control over their release cycle. If the third-party retires an older version of their layer, then you would not be able to update your function until you upgrade to the latest version. Since there is no semantic versioning support, we cannot easily tell if there are breaking changes between the two versions. We also need to treat layers with the same level of scrutiny as we do with other dependencies and make sure that:
- The integration between our code and the new version is still working correctly.
- There is no malicious code embedded in the new version (as it might have been compromised).
But, as we discussed earlier, testing functions that depend on layers is a lot harder and would require more effort. We also need to scan layers to look for vulnerabilities and malicious code, just like we do for other application dependencies. But I’m not sure how you can integrate existing tools such as Snyk and Veracode into the process, and make them work with layers.
When you should use Lambda Layers
Given all these challenges, what are the AWS Lambda use cases for using Lambda Layers? Well, let’s start by looking at other ways of sharing code between functions already.
- To share code between functions in the same project, use shared modules in the same repo. For example, I like to structure my projects so that shared modules are put inside a lib folder. Functions in this project can reference these shared modules directly since they are packaged and deployed together.
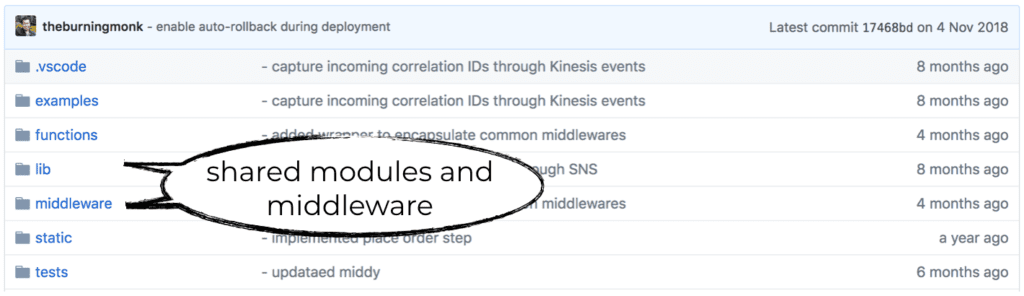
- To share code between functions across projects, publish the shared code as libraries to package managers such as NPM. Where it makes sense, you can also wrap the shared code into a service. Have a read of this post to see a more detailed comparison between shared code and shared service.
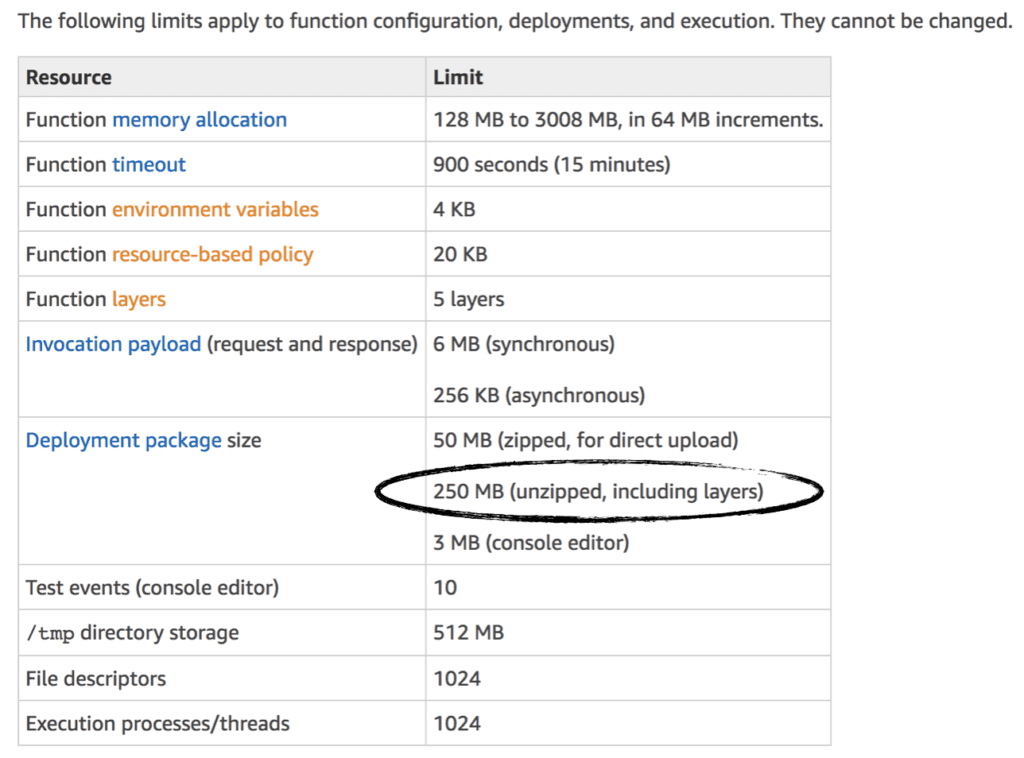
As Gojko Adzic pointed out in this post, one reason for using layers is that it allows you to deploy large dependencies (such as FFmpeg and Pandoc) less frequently. By moving these dependencies into layers, you can drastically reduce the size of your deployment package for Lambda. This makes the Lambda deployments quicker and reduces the amount of code storage space used (remember, there is a regional, 75GB soft limit on Lambda code storage). That said, layers still count towards the 250MB hard limit on the unzipped deployment package size.
Lambda Layers also play an important role in enabling custom runtimes for Lambda. But as Paul Johnston mentioned in this post, you should only be reaching for a custom runtime in a “last resort” scenario.
I think Lambda Layers is also a good way to distribute dependencies such as the MaxMind database. To get the latest version of the MaxMind database, you have to download it from their website. At the same time, these updates do not introduce any behavior or API changes, but frequent data changes.
For other application dependencies, I would recommend sticking with package managers such as NPM. As discussed, Lambda Layers introduces a number of challenges and require additional tooling support. For dependencies that you can easily distribute through NPM, Lambda Layers just do not yield enough return on investment to migrate to.
Although Lambda Layers is a poor substitute for package managers, it really shines as a way to optimize the deployment time of your application. By using something like the serverless-layers plugin you can bundle all of your dependencies as a Lambda layer and automatically update the Lambda functions to reference this layer. On subsequent deployments, if the dependencies haven’t changed, then there’s no need to upload them again. This produces a smaller deployment package and makes deployments faster. If you want to learn more about this pattern, then please give this article a read.

Related content: Read our guide to aurora serverless.
Related content: Read our guide to aws step functions.
Conclusions
In this post, we looked at how Lambda Layers works and the challenges it poses to our existing development flow:
- Most of the tools do not support fetching layers before invoking functions locally.
- It’s harder to run unit and integration tests for functions that depend on layers.
- They don’t work well with static languages such as C# and Java, which requires all the application code as well as dependencies during the compilation process.
- The versioning scheme is basic and does not support semantic versioning. So one cannot easily tell whether it’s safe (from a compatibility point of view) to upgrade to a new version of a layer.
- When a layer or a version of a layer is deleted, functions that depend on them can continue to operate. But you cannot update the functions until you upgrade to a newer version or migrate off of the layer.
Hence my recommendation is to not use Lambda Layers as a way to distribute shared code, except for the following AWS Lambda use cases:
- Large dependencies that are difficult to distribute otherwise and seldom change. Examples include the FFmpeg and Pandoc executables.
- Dependencies that are difficult to distribute otherwise and mostly contain data changes only. Examples include the MaxMind database or SQLite database files.
- Custom runtime for Lambda.
But Lambda Layers is a great way to improve the deployment speed of your application. Think about all the network bandwidth and time that are wasted when you package and upload dependencies that haven’t changed between deployments. Tools such as the serverless-layers plugin (for the Serverless framework) can detect when your dependencies have changed and automatically bundle and publish them as a Lambda Layer and update the relevant Lambda functions to reference it. This is a great way to improve the speed of deployment without the hassle of managing the Lambda layer yourself. Talk about having the cake and eating it!
