









Serverless applications require a whole new approach to development workflow. In this article, Lumigo Director of Engineering Efi Merdler-Kravitz details the guiding principles and tools used at a 100% serverless company to ensure the most efficient workflow possible.
What is a development workflow?
We are not going to talk about product development flow (no product managers were harmed during the making of this post!).
Instead, we’re framing the process starting from the moment you as a developer have a well-defined feature (note that what constitutes a “well-defined feature” is the topic of another lengthy post), continuing through to the point where the feature is deployed in production.
Remember: this is a very opinionated workflow! This may very well not be the best for your specific situation, and that’s okay.
Why are serverless development workflows different?
Serverless changes a lot — but in this context, it can be distilled down to two distinct points.
Mindset. Serverless is not simply about using functions, it is about adopting a state of mind where you’re constantly pursuing the most efficient route to providing business value. That means enthusiastically embracing managed services wherever possible, leaving you free to spend as much of your time as possible on work that directly provides that value.
But wait, there’s more! In our model, serverless also means all or most of your toolchain is in the cloud; thus someone else is managing it. That includes your git repositories ✓, code quality and linting ✓, CI/CD engine ✓, development and testing environment ✓, etc.
Tooling. The moment your tools are also in the cloud, your workflow needs to accommodate that and make it easy for developers to make a quick transition (while developing) from local to remote and vice versa.
Guiding principles
When creating a serverless development workflow three principles should guide what you build:
1. You should aim to detect problems as early as possible in the development cycle. We all know that fixing a bug in production is more expensive than fixing it during development , but in our case, it is also cheaper to detect bugs locally on the developer’s laptop than on a remote testing environment. Local is faster than remote (for the time being).
2. No dedicated QA department — ohhhh this is a contentious point! I don’t have anything against QA, but I do believe that developers are the sole owners of their developed product (note I didn’t call it “code”), from the moment it is first conceived until the moment customers use it and love/hate it, from top to bottom. There is room for QA in places where automation is too expensive to build, but this is the exception, not the norm. Existing QA teams can also serve as a valuable source of guidance, to help developers in thinking about cases that require testing. Create tools that allow developers to test easily both locally and remotely and try to automate the testing process as much as possible.
3. Developers are responsible for monitoring — Again, this a painful point. Now, I’m not saying that there is no room for devops in the organization, but developers are usually the folks best positioned to know if their developed product is behaving normally. They’re also generally the product owners who are best positioned to define the right KPIs for the product. Bake product visibility into your development workflow.
High-level view
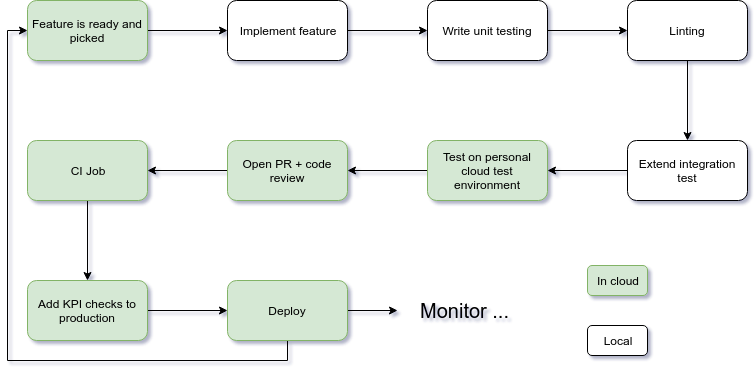
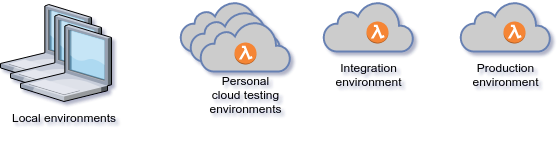
Technical Stack
- The bulk of the services are written in Python 3.7 . Some in NodeJS 8.10
- Jira as our ticket manager
- Github as our source control and code review tool
- Pytest for local and integration testing
- Flake8 for linting
- Serverless as our serverless framework
- CircleCI as our CI/CD server
- CodeCov as our testing coverage
- lumigo.io and logz.io as our monitor and KPI tool
Drill down
Task management
We chose Jira, mainly due to the power of inertia. Our biggest complaint is its slowness. It is important to mention that we use a combination of Kanban and weekly sprints as our product process. The main benefit that we see is the ability to pick a feature, develop it and push it to production without the need to wait for a “formal” sprint ending.
Implementation
During this phase, it is the developer’s responsibility to define KPIs. There are two types of KPIs that should be taken into consideration:
- Product KPI — Is the feature being used? How it is being used? What is the impact of it to the organization?
- Technical KPI — Are there any operational errors? What is the latency of each request? How much does it cost?
Unit testing
Of course, it depends on whether you use TDD or not, so writing tests might come before the implementation step. The point here, though, is that you cannot move forward in your flow without finishing unit tests. Remember, test locally whenever you can. It’s faster. A word of caution about mocks: we prefer to avoid mocking services with “emulator” mocks, e.g. mocks that actually do something behind the scenes like DynamoLocal from AWS due to two main reasons:
- Interfaces changes frequently, so testing against local implementation does not guarantee it will work in production.
- Setting up your local development environment becomes very cumbersome. For more details, you are welcome to read my thoughts about testing in a serverless environment
Automatic linting
No matter if we are talking about dynamic or static languages, linting is a mandatory step. Linting should include at a bare minimum:
- Opinionated auto-formatter — something similar to black for Python or prettier.io for JS. I do not want to work hard to format my code, so everything should be done automatically.
- Static type analysis — in dynamic languages like Python we run static type checker like mypy.
- Static analysis — This is the real “linting” process, pylint for example.
What do I mean by automatic? Simply put, everything is backed into a git pre-commit hook. We are using the pre-commit framework, which gives us the ability to run the linting process either manually or in CI environments. This is our .pre-commit-config.yaml file and a bash script the developer can use to run the linter flow.
Extend and/or run your integration test
Running integration tests are mandatory in serverless environments. For those too lazy to click, this is because many interfaces are not under your control and you need to test continuously to ensure that nothing is broken. Running is mandatory, but extending is not. My rule of thumb for whether a change in code requires addition of an integration test is whether it is a new flow (no need for an integration test for a bug), and whether it is a critical path. In other words, if it breaks does the customer leave us?
Test on a personal cloud environment
Committing your changes without testing them on an actual native cloud environment means that you won’t really know if your code actually works.
Here at Lumigo, each developer prepares their own cloud environment during their first few days in the company.
A script enables the developer to push changes to his or her cloud environment and run either manual or automated testing on it.
The developers have now reached a point where they trust their code to do what it is intended to do and that it doesn’t break anything. It’s time to move the changes up the ladder!
Open PR + CI job
We use the GitHub flow in conjunction with CircleCI . When a developer opens a PR, two things happen in parallel:
- Code review is done through GitHub’s wonderful interface. Code review is mandatory and the developer can not merge to master without doing it.
- A bunch of tests are conducted, ensuring that nothing bad is being merged into master. Let’s go over our CircleCI script:
Line 8 – We use the “commands” attribute to build and reuse our own custom commands
Line 22 – At the end of each deploy we tag a release in master. Tagging creates a new event in CircleCI, which in turn causes another build of the repository. To avoid the infinite loop we check whether it’s a tagged commit and in such a case exit the build gracefully.
Line 55 – One of the cool features of CircleCI is the ability to run specialized dockers for your own environment. We are using the Python docker, therefore we need to install NodeJS as a prerequisite for the serverless framework. We do intend in the future to create a unique “Lumigo” docker in order to avoid the extra installation time.
Line 63 – Most of our workflows are quite simple and are composed from testing phase and deploy phase, when deployment is being done only on merge to master (GitHub flow)
Pushing to production
If all tests and prerequisites passed we are ready to push changes into production. Only the relevant functions will get updated, not the entire application.
When creating scripts, we try to adhere to a couple of guiding principles:
1. Scripts should be usable both by the CI system and by developers
2. Make sure scripts are easy to run for developers
For example, the script above is using Serverless Framework to update an AWS environment. When using it to update the developer’s cloud environment all they have to run is ./deploy.sh , The CI environment will use ./deploy.sh –env prod.
Fin
Defining a development workflow is an art, not a science. Each development team has its own quirks and preferred way of working. That said, I do believe that core values of using serverless tools and testing in the cloud is a sensible default that should be shared among all serverless developers.
As I wrote at the beginning of the post, this is a very opinionated workflow that works quite nicely for us. Please get in touch on Twitter to share your thoughts or alternate development workflow!