










UPDATE 21/06/2020: following the official launch of this feature, we have performed more thorough performance testing to see how mounting an EFS file system affects the Lambda cold start duration and how the read/write performance compares to S3. Scroll down the article for more details.
Today, the AWS Lambda platform has added a new arrow to its quiver – the ability to integrate with Amazon Elastic File System (EFS) natively.
Until now, a Lambda function was limited to 512MB of /tmp directory storage. While this is sufficient for most use cases, it’s often prohibitive for use cases such as Machine Learning, as Tensorflow models are often GBs in size and cannot fit into the limited /tmp storage. Or maybe you’re processing large amounts (say, GBs) of data and need to store them in the /tmp directory for easier access.
This limit became a showstopper for a number of my clients and I’m really excited by today’s announcement as it makes Lambda a great solution for an even wider range of use cases. Not only that, while I think it should be used with care, the EFS integration also makes it possible to have a shared state between concurrent executions of a function or even across multiple functions.
So let’s see how we can create and attach an EFS file system to a Lambda function.
Creating and attaching an EFS file system
First, head over to the EFS console and click “Create file system“.
Next, configure the VPC and Availability Zones for the new file system. Yup, that’s right. You have to be inside a VPC in order to access an EFS file system. Lucky for us that the enhanced VPC networking has been rolled out to Lambda functions globally, so there is no more performance penalty for being inside a VPC! There is still a small chance of ENI and/or IP exhaustion, but these are far less likely.
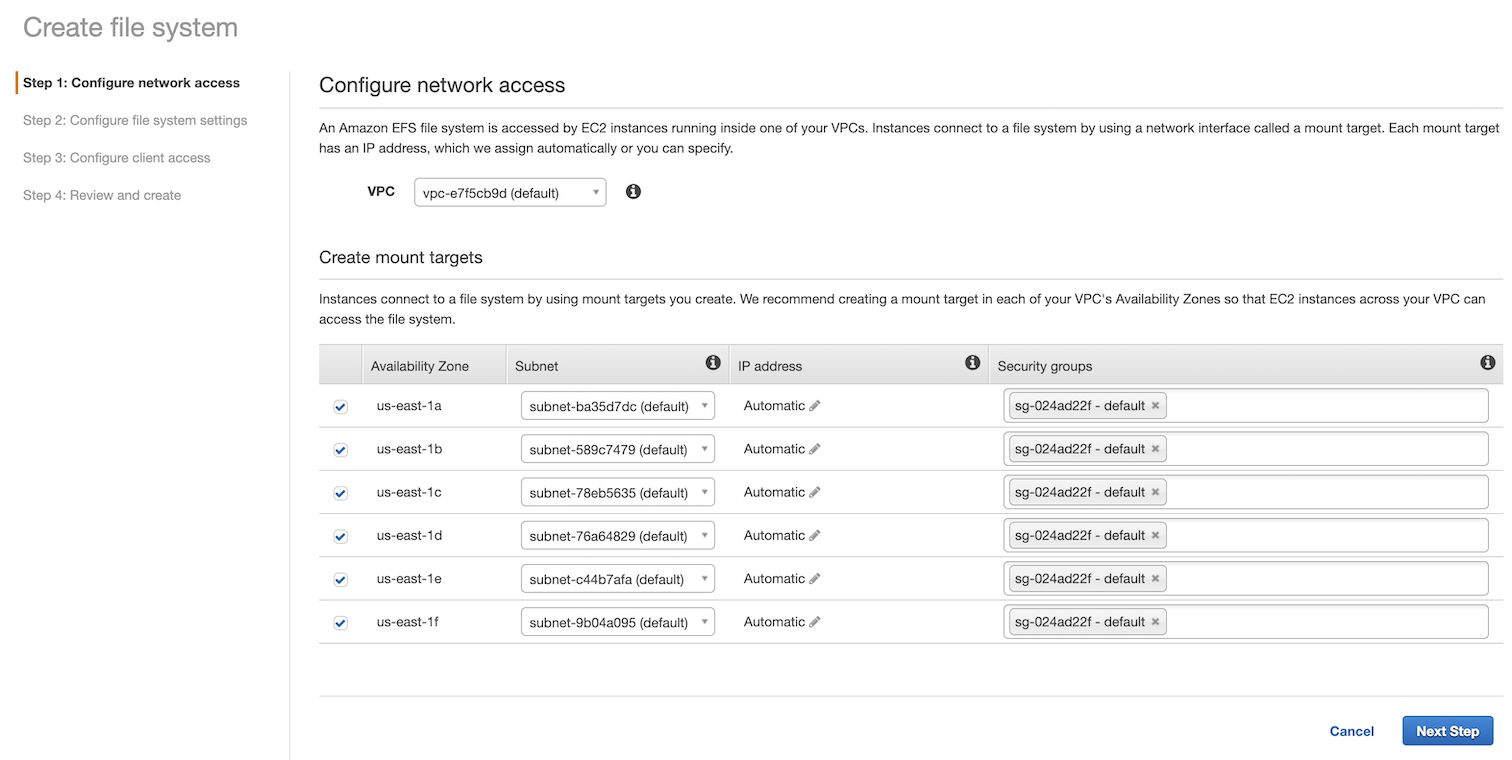
In the next screen, there are some more configuration options. The most important configurations here are the throughput and performance mode. You can read more about these options in the official EFS Performance guide. In a nutshell, Bursting Throughput scales the throughput of the file system with its size – the bigger the file system, the higher its throughput. Whereas Provisioned Throughput gives you predictable throughput (in MiB/sec) but requires additional overhead for managing it, including a 24-hour cooldown period between throughput decreases.
One thing worth noting is that during the private beta we were told to stick with the General Purpose performance mode. This was because the Max I/O mode has higher latencies for file operations, which caused problems with the mount latency from Lambda. It’s possible that this has been resolved by now, but please consult the official documentations for more details. Update 21/06/2020: AWS has confirmed that this is no longer the case and there’s no issue with using Max I/O throughput mode.
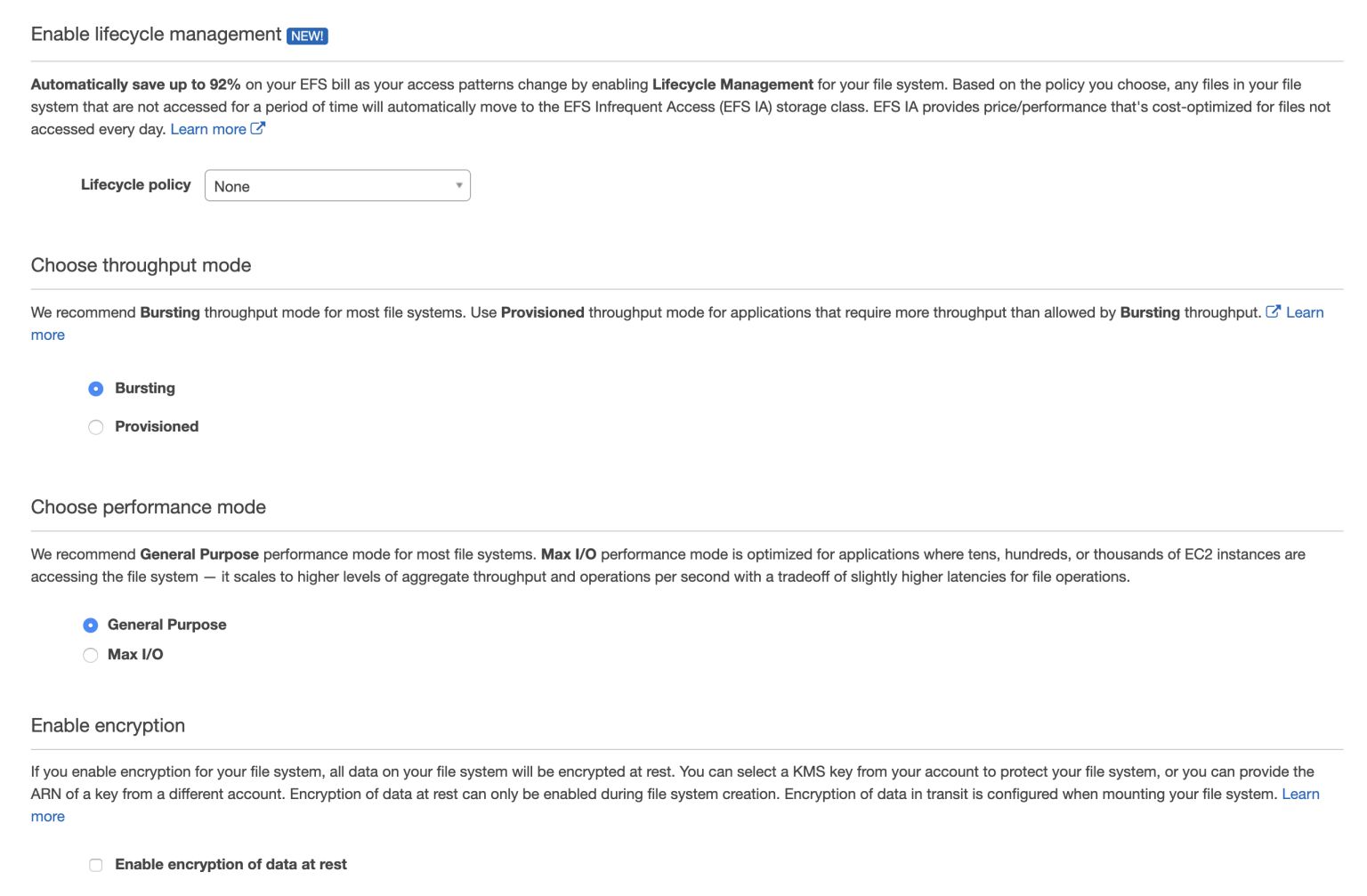
Next you can configure the file system policy. For more details, please check out the official documentation here.
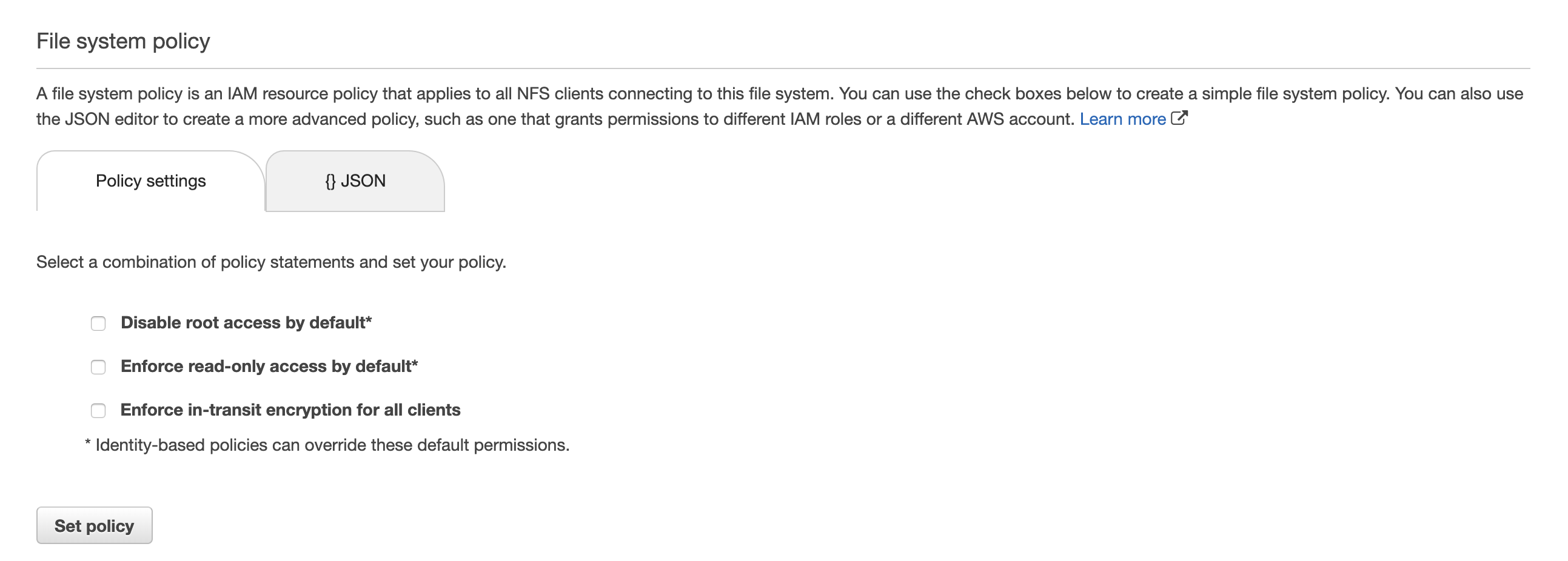
To give Lambda functions access to the file system, we need to create EFS access points. These are application-specific entry points to an EFS file system. In the following example, we created an access point that allows root access to the /test directory in the file system. We can use access points to control what directories on a shared file system a function can access.
Next, review everything and hit “Create File System“.
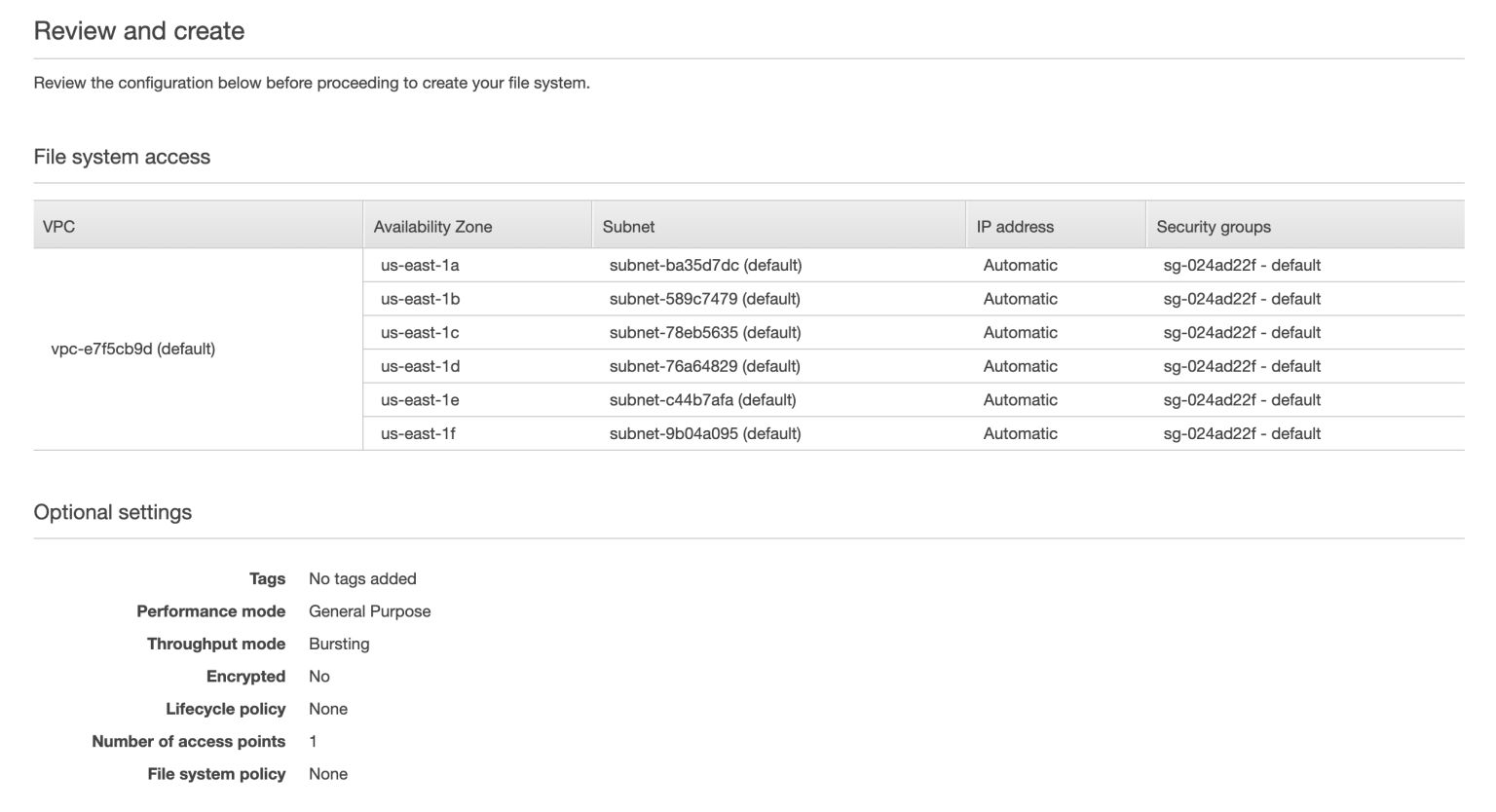
Now that our new EFS file system is ready, head over to a Lambda function.
At the bottom of a Lambda function’s configuration page, you should see the option to “Add file system“.

Before you can attach the EFS file system, you first need to:
- configure the function with access to the file system’s VPC
- give the function IAM permissions for
- ec2:CreateNetworkInterface
- ec2:DescribeNetworkInterfaces
- ec2:DeleteNetworkInterface
- elasticfilesystem:ClientMount
- elasticfilesystem:ClientRootAccess
- elasticfilesystem:ClientWrite
- elasticfilesystem:DescribeMountTargets
Once you have these, then click on “Add file system“.
And choose the file system and access point we had created earlier. Another important piece of configuration here is the Local mount path. This is where the /test directory (which we set up in the access point) would be mount to in the Lambda execution environment. It’s also worth noting that the local mount path must start with /mnt/.
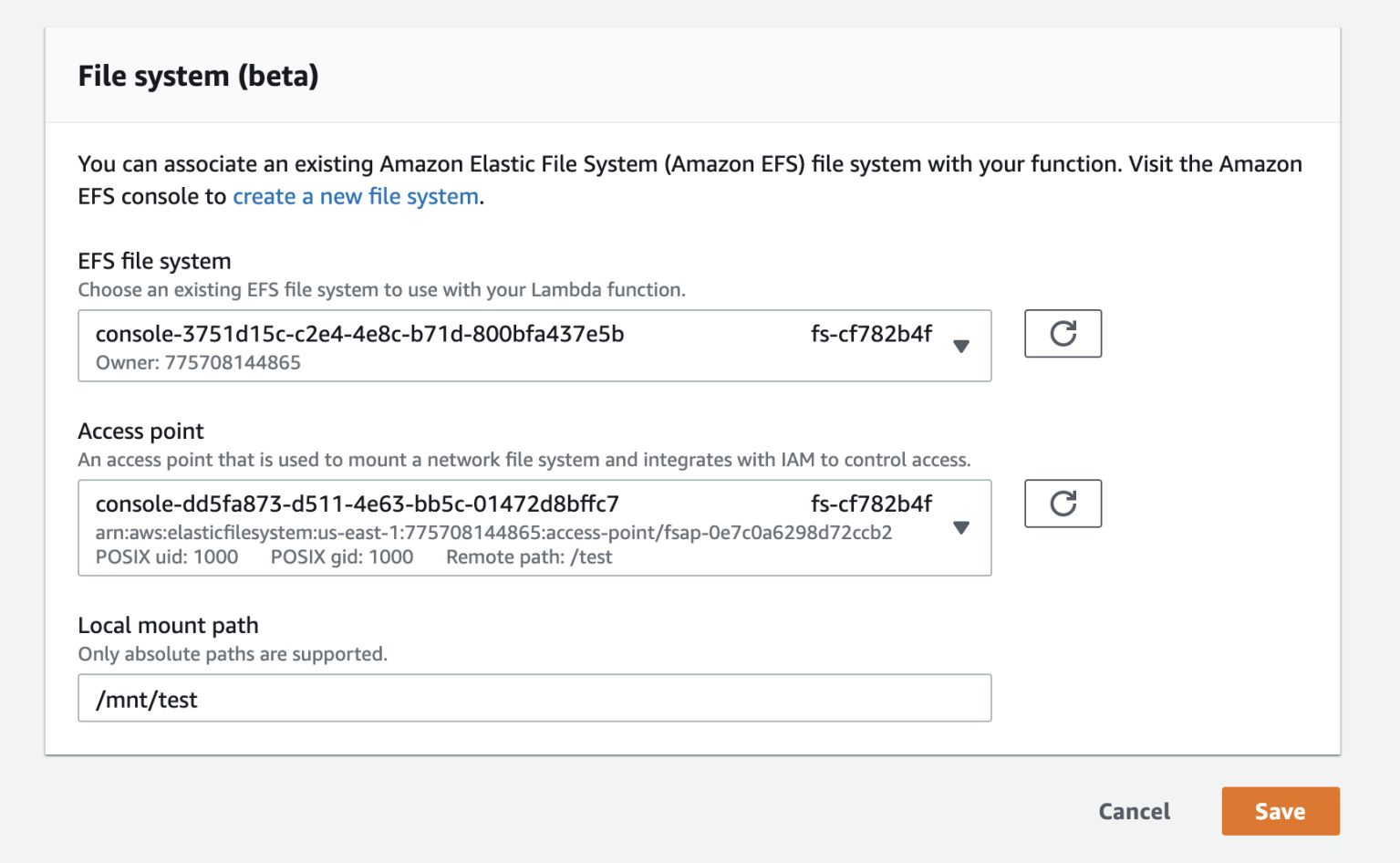
Once mounted, you will be able to read and write files on the EFS file system against the local mount path. For example.
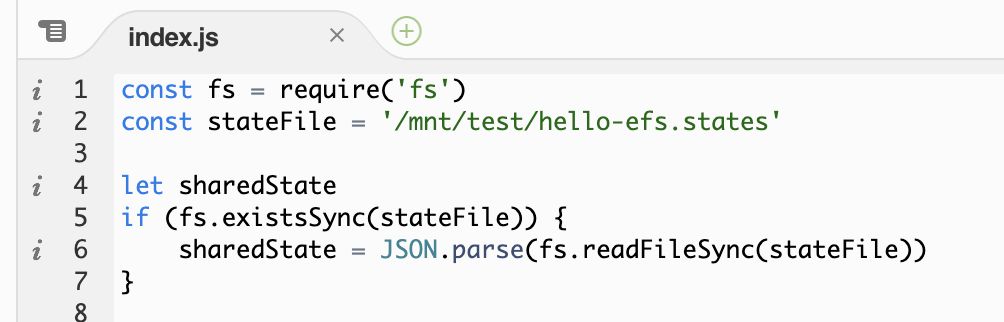
Files written by one concurrent execution would be accessible by another, which allows you to share files across concurrent executions and functions. This opens up some interesting opportunities beyond the ability to go past the 512MB of /tmp storage limit.
Caveats
While the EFS integration is another exciting step in the evolution of the Lambda platform, it’s worth considering a few limitations before you drink the koolaid.
File watchers don’t work
Firstly, while you can easily access files on the EFS file system using normal file system operations, such as fs.readFile in Node.js. It’s not possible to listen to file changes with a file watcher and trigger a callback during the next invocation. At least I couldn’t make it work during my testing. Please leave a comment below if you figure out how it could work and let us know any use cases you might have.
High latency on file operations* (updated 21/06/2020)
While I was testing the feature, I also noticed that it took an average of 8ms to read a 30bytes JSON file, and 30ms to write the same file back to the mounted EFS file system. For a more details look on EFS performance from Lambda, please see the Performance section below. In general, EFS is a bit faster and more predictable than S3, but the read/write latency is still orders of magnitude higher than working with the /tmp directory (i.e. local file system).
What’s more, increasing the function’s memory setting didn’t yield any measurable differences. Nor did switching over to Provisioned Throughput mode and dialling up the throughput to 10 MiB/sec (which will incur a cost of $60/month).
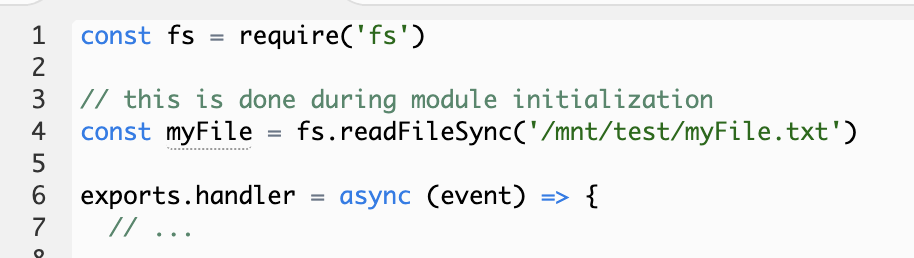
This latency essentially rules out EFS for any latency-sensitive applications, unless you enable Provisioned Concurrency on the Lambda function. Provisioned Concurrency initializes the Lambda function module before putting into active use. In this case, you can load the files from EFS outside the handler function (see below), so they’re performed before the Lambda container is put into active use so your users don’t experience the extra latency.
Performance (updated 21/06/2020)
Cold Start performance
Firstly, we found that mounting an EFS file system has no impact on a function’s cold start duration. Using the Lumigo CLI’s measure-lambda-cold-starts command, we can see that there is no difference between a control function (no VPC, no EFS, etc.) and a function with an EFS file system.

It’s worth noting that the measure-lambda-cold-starts command only measures the initDuration (that is, the time it takes the function module) portion of the cold start time.
You may have also noticed that the two functions had different memory size and therefore CPU resources. This did not affect the measurements because for “unprovisioned” (that is, functions that do not have Provisioned Concurrency) functions, module initialization is always performed at full CPU. You can see more information about this behaviour in this article by Michael Hart.
File read/write latency
We compared the read/write latency of EFS against S3 for a variety of file sizes: 1KB, 100KB, 1MB, 10MB, 100MB and 400MB.
On each invocation, the Lambda function would read the file from EFS, and then write its content back to EFS, as a separate file.

As you can see from the results we collected below, EFS is both faster and more predictable (i.e. lower Standard Deviation) compared reading and writing from/to S3.

But something was weird about the EFS read latencies – there’s a big jump around the 95th percentile latency values. So we dug into the results to try to understand what’s going on.
As you can see below, the EFS read latency always “spikes” during a cold start. You can identify these by looking at the first latency value for each unique log stream (which has a 1:1 mapping with Lambda containers). This is consistent for all the file sizes.
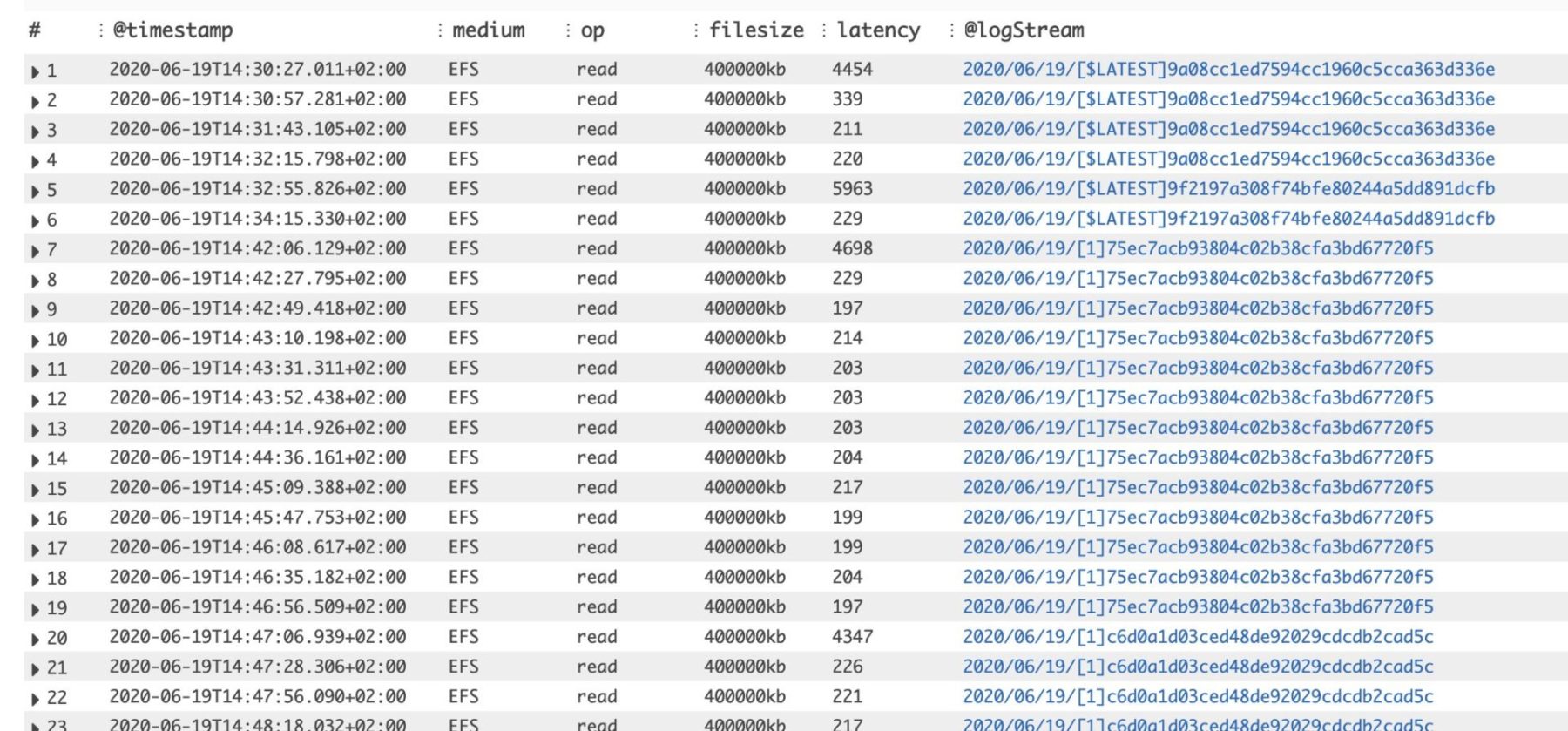
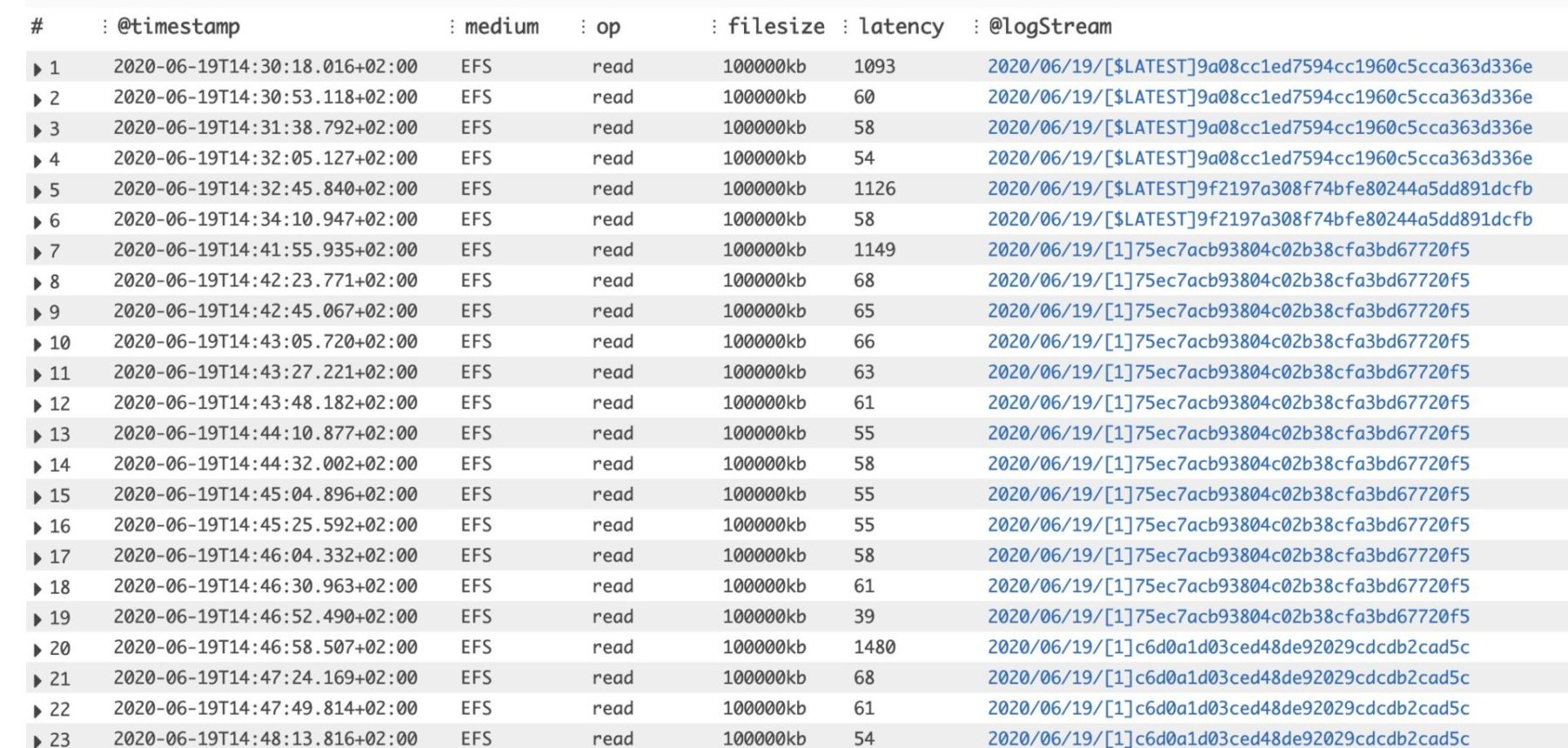
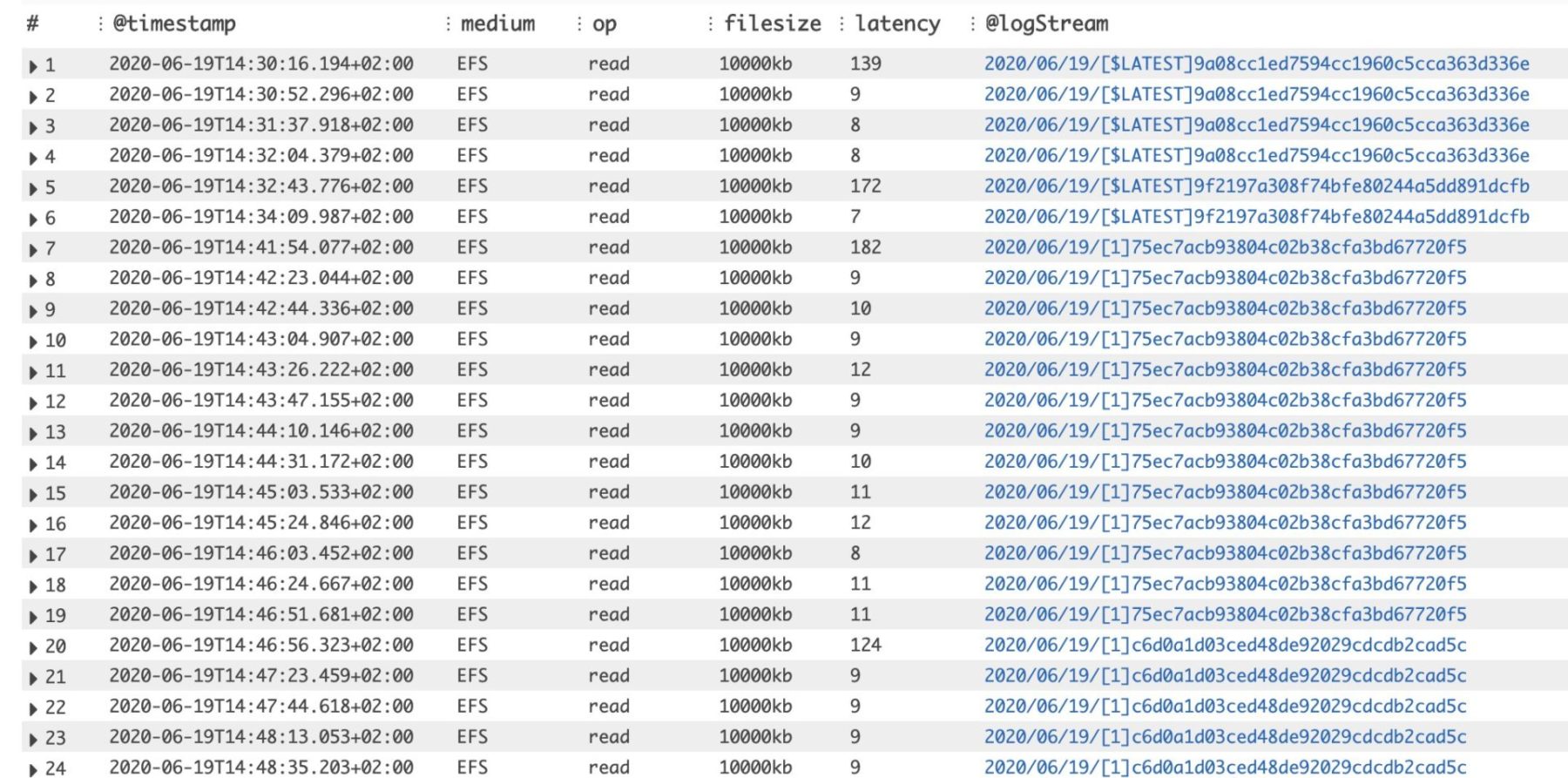
As Marc Brooker (Principal Engineer on the Lambda team) explained, this is likely due to OS-level caching. This means if you need to read the same file repeatedly, then you only experience the “full” read latency on the first try.
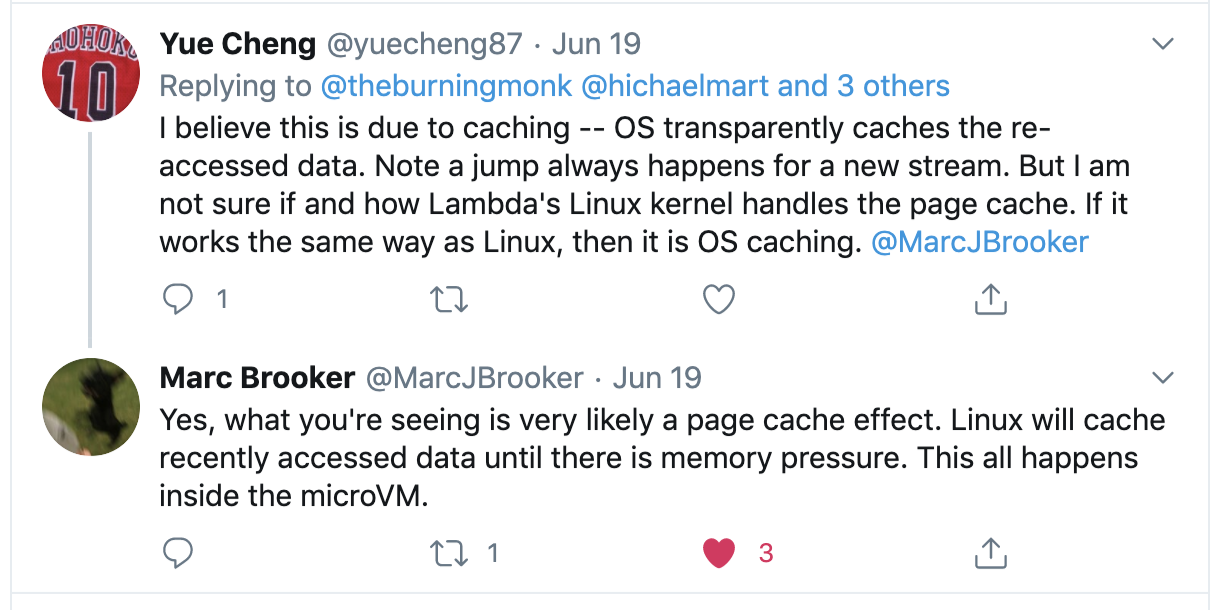
What if that’s not your use? What if you need to read files that are frequently changed by other components, e.g. by another Lambda function or EC2 instances?
To remove these cached reads, we reran the test, but this time we introduced another Lambda function to update the files on each iteration. As you can see, the EFS read latencies are now much more uniform and also closer to S3’s latencies.

The take away here is that EFS’s read/write performance is both faster and more predictable compared to S3. However, the actual read latency you will experience depends on your usage pattern and how it intersects with OS caching.
Unlocking new use cases
The ability to read and write large files opens up use cases for machine learning (ML) as we often have to work with very large (> 1GB) models. However, as discussed, the EFS latency can be problematic here if you have to load a large file during initialization. Fortunately, you can work around this issue with Provisioned Concurrency, which you can read more about here where we detailed how it works, and its limitations and tradeoffs.
Given the caveats of using Lambda with EFS, should you run your machine learning workload there instead of an ECS cluster, Fargate or plain EC2 instances? Well, it depends on a lot of different factors. For example:
- How familiar are you with containers and container orchestration systems such as EC2 or Kubernetes?
- How quickly are you able to reach the required level of scalability and resilience with your container-based solution?
- When do you need to run your machine learning model? Is it triggered by HTTP requests, or would you also need to build the event trigger yourself, e.g., a Kinesis consumer app or something that forwards messages from IoT devices?
- How often do you need to run your ML model? Are you making good utilization of the underlying compute resources? That is, would the solution be cost-efficient?
- How much do you care about the operational cost of running your ML model vs the time it takes to deliver a working solution?
Adding Provisioned Concurrency to a Lambda function is straightforward and doesn’t require code changes to your application. Doing so allows you to take advantage of the instant scaling and built-in redundancy Lambda gives you. Not to mention the ability to run your Machine Learning model in response to many types of events: HTTP requests, IoT messages, processing events in real-time with Kinesis Data Streams and so on. For many cases, this makes Lambda and EFS a better option over a containerized solution.
You might also be asking “Can I not use S3 for storing these large files instead?” Absolutely. In fact, S3 supports multi-part upload and download to help you speed up the transfer of these large files. However, EFS can be much more cost-efficient in some cases, especially with Bursting throughput mode where there are no bandwidth or request charges. In Bursting throughput mode, you are charged a fixed fee of $0.30 per GB per month for Standard Storage. See here for more details on EFS pricing, with some pricing examples, and here is a good comparison of EFS vs S3.
Loading large dependencies
If you have run into the 250MB deployment package size limit with Lambda – again, it’s quite common in machine learning workloads because the size of the libraries you often have to use (such as Tensorflow) – then EFS can help you work around those too. The same caveat around read latency applies and you do need Provisioned Concurrency here too.
For a Node.js function, to load dependencies from EFS:
- Write your dependencies to the EFS file system. You can do this through an EC2 instance that connects to the same file system. For example, if you write the dependencies to /test/node_modules.
- Override the NODE_PATH environment variable to include the node_modules folder on the EFS file system, e.g. /mnt/test/node_modules.
- Require the dependency as normal and the Node runtime would check the EFS file system for your dependencies.
This works because the NODE_PATH environment variable is an unreserved environment variable (see here for the list of built-in environment variables). The same approach can be applied to Python and other runtimes too.
However, keep in mind the effect the EFS latency has on your cold starts. As an example, a lightweight dependency such as fs-extra took a whopping 1.3s to load from EFS. Larger dependencies with many more files and transient dependencies would take even longer to fetch. The AWS SDK, for instance, took over 7s to load from EFS during initialization.

Again, to make this work, you need to use Provisioned Concurrency.
Sharing data
I’m not crazy about the idea of sharing data between concurrent executions, but I can see how this might be useful in some specific cases.
For instance, if you have to download a large payload from a third-party system and then perform Map-Reduce tasks on it. Then it can be quite handy to store the payload onto the EFS file system before fanning out the invocation to many concurrent executions (perhaps through an SNS topic). Each execution can access the payload through the EFS file system and write their results back to the EFS file system. And when all the executions have finished, you can run a reducer function over the results by simply iterating through all the result files on the EFS file system.
As mentioned before, S3 can also be used in these situations. But it’s worth considering the cost of EFS (GB/month, no bandwidth and request charges) vs S3 (bandwidth, request and GB/month) for your specific workload.
You can also use a shared EFS file system to share other types of data, such as configuration files or even the state of circuit breakers. All of these can already be centrally controlled and managed by other services such as SSM Parameter Store, or DynamoDB, or Elasticache, or whatever! These services offer comparable, if not faster (e.g. Elasticache can give you sub-ms read latency) access to your shared data than EFS. So why would you ever consider using EFS instead?
The most compelling reason that I can think of is – it’s just easier to manage if they’re all in one place. Rather than spreading your shared data across many different services, each requires a different access pattern, code change, IAM permissions and configurations, it’s just easier to put them all in a shared EFS file system.
I don’t think it’s a good argument, but I definitely see its appeal. SSM Parameter Store and Secrets Manager, for instance, both give you built-in audit trails to see when configurations have been changed and by whom. These are important characteristics for application config and secrets, and EFS won’t give you that because it’s just a file system. Although, it does have built-in lifecycle management and encryption at-rest out-of-the-box. So it’s not a bad place for these shared data, it just might not be the best place for all of them.
Summary
In this post, we looked at how we can create and attach an EFS file system to a Lambda function.
We also looked at some caveats to keep in mind when you’re working with EFS and Lambda. The main one to watch out for is the latency of file ops. In terms of latency, it’s nothing like a local file system. In fact, the latency I experienced during my tests was comparable to S3.
The high latency means it’ll be unsuited for any latency-sensitive applications unless you also apply Provisioned Concurrency to the Lambda functions in question. And as we discussed before, while Provisioned Concurrency is a powerful tool in our toolbox, it does come with a number of drawbacks itself, including the fact that you won’t be able to use the $LATEST alias anymore.
But despite its drawbacks, I think it’ll still unlock many use cases for Lambda, which is hamstrung by various storage-related limitations today, such as the 250MB deployment package size limit or the 512MB /tmp storage limit. While these limits are generous for most use cases, they are often showstoppers for folks who are trying to run machine learning workloads on Lambda.
And by the way, Lumigo fully supports the new EFS capabilities. If you don’t have a free account yet, you should get one.
I hope with the launch of the EFS integration with Lambda today, many more of you would be able to use the power of serverless to accelerate feature development and make your solutions more scalable, resilient, and secure!