










As a team that does pure serverless, we place a lot of emphasis on fast deployments. Lately, though, as our codebase has gotten larger, and the number of interactions between the microservices has increased, we have come up against the classic problem of excessively long test execution times in our serverless continuous integration.
It’s a familiar problem: tests are our strongest tool for validating correctness, but the more comprehensive they are, the longer they take. Whenever we push a hot bugfix to the repository, we want it to address the issue in production ASAP, but only after it passes the three levels of testing (unit, integration, and E2E). So, when we reached the extreme execution time of more than an hour-and-a-half for the tests that query our microservices, we were finally prompted to think hard about how we could get back up to top speed with our deployments.
In this blog post, we’ll describe our new methodology that decreases test execution time to less than 40 minutes, without sparing any test, without any invasive code, and without any additional cost.
Our original serverless CI architecture
Here at Lumigo, we’re firm believers in using a multi-repo codebase for serverless, in which each logical repository holds all the microservices that handle that specific issue (you can read more about that here).
We use the Serverless Framework, and each repo has a single `.yml` file that deploys all the necessary services. In addition, there is a common repo that declares the API of the services, and which holds the instructions on how to trigger each one.
The original “Uber” deploy tool
The first step in the testing architecture is to deploy all these microservices; preferably in parallel. Key to achieving this was the tool that we named “the Uber deploy”. This is a CLI tool that manages our multi-repo environment (through local deployment, local tests, CI and deployment). Here’s what it does:
- Clone repos if they do not exist.
- `git pull` the latest changes of any repo.
- Get a branch name as an argument, and `git checkout` to it in every repo (just think of the benefits when a single feature changes many repos!).
- It then assumes the structure of the repos and deploys all the `.yml` files, which are located in predefined locations.
And, importantly, it does all of this asynchronously for each and every repo. Obviously, that means it handles a huge number of async outputs, so it summarizes successful events in an easily digestible format.

The test repository
The repository that handles the integration and E2E tests is a separate one, which has its own services and, thus, `.yml` file. Each test in this repo roughly triggers something on one edge and asserts something on the other. The tests are written in Node.js 12, using mocha, the regular AWS SDK, and special `beforeHook` and `afterHook` that are responsible for rendering the output readable (i.e., suppress output of successful tests).
This is a great KISS mechanism that keeps the tests isolated from one another, but the major downside is that it is simply not scalable to many tests. Every time we added a new test it increased the cumulative test execution time until we got to a critical point where the deployment duration was a major part of the total duration of the task.
Our new serverless CI architecture
In the end, the key to solving our problem was exceedingly simple: to use multiple AWS profiles, thereby creating isolated environments instantly. The profile is the credentials that the SDK uses in order to execute queries to AWS, and this is the key to our scale.
The change was straightforward. We just added more accounts and scaled everything without any additional cost.
The idea is to deploy the same environment on multiple accounts, each account will run a single isolated test, and we can parallelize across the accounts. The deployment should not consume extra time because we’re deploying the same number of services to independent places. By running the tests concurrently across a number of accounts, we reduce the time taken linearly.
And since we are pure serverless, the deployment itself doesn’t cost a penny (three cheers for pay-per-use!). In addition, since we run exactly the same number of Lambdas, and perform the same number of actions (cumulatively over all the accounts), the total cost will always be the same.
The new “Uber” deploy tool
The first change was to add a few new capabilities to the uber deploy tool:
- Get multiple profile names as an argument (and take “default” as default), and deploy them all in parallel.
- Use the flag `–aws-profile` to indicate to Serverless Framework which profile to use.
- Perform fast-failure detection and retries. This is achieved by introducing a new flag `–retry` that indicates the number of retries to perform if the deployment fails.
This was actually already in place but it proved especially useful with our new parallel testing regimen because of the high load of concurrent executions.
We encountered a few unexpected drawbacks when we tried to use `sls deploy` on the same file in parallel:
The first is that SLS uses global directories to hold its state. The `.serverless` directory that SLS opens in the same directory as the `.yml` file is the first problem. We solved it by copying the file to a `mktemp` directory (new directory with a random name).
The second problem was`~/.serverless`, which was solved by exporting a different `HOME` to each profile.
The final problem was the high CPU and memory demands. We run this step on CircleCI’s agents, as part of our CI, and these are limited in resources. By adding the `retry` flag, we overcome this problem instantly.
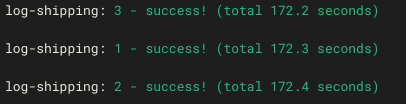
The test repository
We searched for a mocha-equivalent package that could help us by concurrently running the tests itself. The package that we decided to use is `mocha-parallel-tests`, which uses Node.js 12’s workers in order to create parallelism.
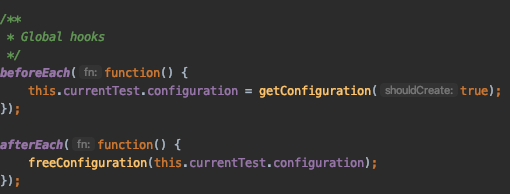
We created global `beforeEach` and `afterEach` hooks to create a mechanism that catches and frees environments, using environment variables. This mechanism synchronizes between the workers so we can ensure that every test runs in an isolated environment.
Before every test, the hook `beforeEach` executes and locks an environment for the test. It changes the profile that this worker will use to this environment, and lets the test run exactly as before (without any code/test change). Once the test ends, the `afterEach` executes and frees the environment for the following tests.
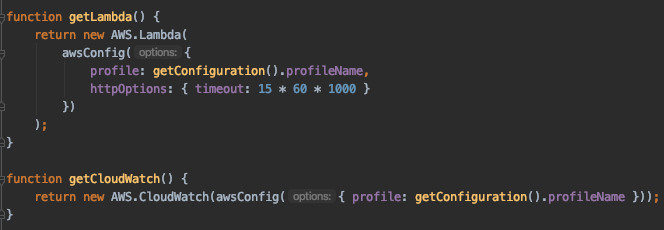
We created a `utils` file that creates the services using the profile:
Summary
Our goal was to improve deployment time by significantly decreasing the runtime of our tests.
As described above, we created a simple but strong mechanism that provides complete parallelism of every integration and E2E test, while preserving the isolation of each test. This mechanism doesn’t increase the cost of executing the tests, and with correct implementation, it contributes to a robust CI/CD process that helps prevent problems quickly, and far away from production.