










Lumigo CEO Erez Berkner shares the seven guiding principles that shaped his development team’s serverless CICD pipeline.
The DevOps infinity loop is a visualization that everyone reading this article is likely familiar with, and one that comfortably predates serverless computing. Yet despite the peculiarities of developing within the serverless paradigm, it’s still what guides our approach to CICD.
But while the zoomed-out view might be the same, when it comes to adjusting for serverless, the devil is in the details.
Image source

Coding – Multi-repo is the best choice for distributed systems
The debate between the monrepo and multi-repo approaches rages on. But in our experience with a 100% serverless backend, multi-repo makes more sense because it’s simply a better match to a distributed CICD pipeline.
The one thing you need to be aware of – if you choose the multi-repo route – is dependency correlation. It can be easier to handle cross-repo dependencies, or common packages, when everything is in one bucket like in a monorepo setup. Some find that multi-repo can be a bit more cumbersome, but it becomes much easier if you maintain a well-organized pipeline that’s easily duplicable.
Read Yan Cui’s view on the multi-repo vs monorepo debate here.
Testing #1 – Distributed environments should be tested in the cloud
Sure, you can test code logic locally (it’s certainly quicker and easier), but the moment you want to test against something proprietary to the service, say a DynamoDB call, you’ll never know that everything works as it should unless you test against DynamoDB.
At Lumigo we believe in testing in an environment as close as possible to the real thing. And the closest thing to a serverless cloud environment is… a serverless cloud environment. Local mocks for AWS and third-party services are available, of course, but you would have to be brave (or reckless) to rely too heavily on them. The fact is, they sometimes break, or they’re not a true match because the cloud provider has changed how the service works in some way.

Testing #2 – Integration tests are crucial in distributed systems
Integration testing is critical in a serverless environment because your application is composed of so many small components – Lambda functions, AWS-native services and third-party services – that all have to play nicely together.
Our integration environment runs on native cloud and is completely automated. Every time new code is pushed to GitHub, CircleCI takes that code, puts it together with the existing stack, then runs a series of predetermined tests.
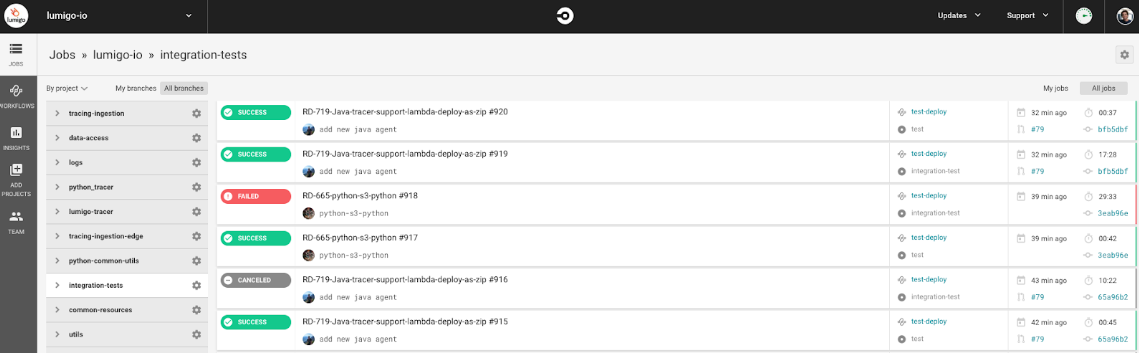
One thing to bear in mind is that you’re not testing on production traffic, which can introduce unexpected behaviors that your integration tests cannot take into account. There can also be issues with scale, and you wouldn’t normally do load balancing because of cost and other factors.
For more on this topic, read Avishai Shafir’s Serverless testing – Adapt or cry

Release – don’t leave the gate open!
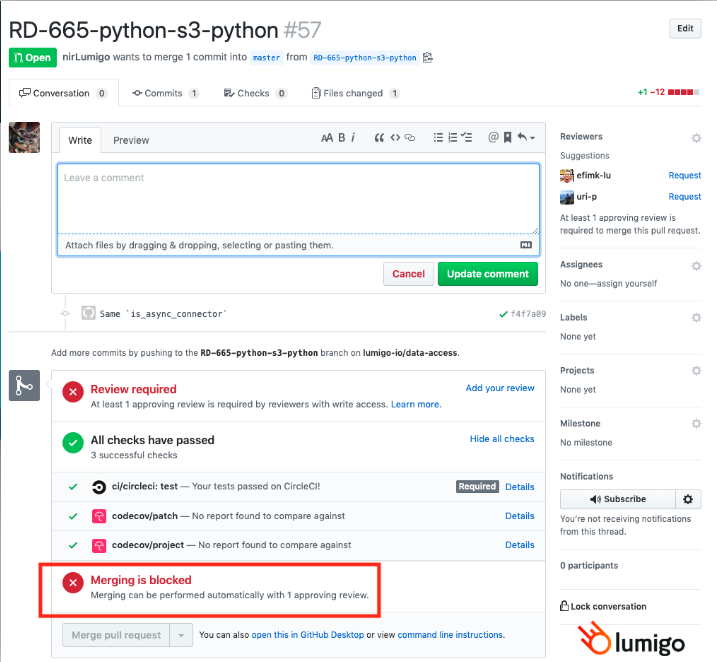
Automated Gates are the best way to prevent you from merging faulty code into production.
We do this via GitHub. It automatically runs through a checklist when a developer wishes to merge code, and unless all the statuses are good, it won’t let you merge.
Gates can be used to enforce code coverage thresholds, as well as successful completion of unit tests, linting, integration tests, and last but not least – code review.
Deployment – be predictable
As your environment gets more complex, with an increasing number of resources, it’s a good idea to have a very formalized way to update it. We use the same deploy scripts to both the integration environment and when we deploy to production.
A deploy script takes care of the automation of the technical commands and takes your built code and uploads it to a server, or tells the environment: this is the new code for this particular Lambda.
This way there is less code to manage and maintain, and it helps you to have reproducible code. It’s impossible to overstate the importance of predictability as your environment gets more complex. Your integration and production environment should be as similar as possible.
One of the reasons we chose CircleCI, even though it’s less mature than some other services, is because it’s completely serverless, meaning you don’t have to manage the servers doing the work, you don’t have to worry about scaling, or managing servers at the OS level. You can feel it was built with distributed architecture in mind. CircleCI is very native to serverless.
Learn how to create an advanced serverless CICD pipeline with CircleCI here.

Operation – Never change code in production
Let’s move on to the day-to-day, when your code is already in production.
The key concept when it comes to Operation in serverless is ‘immutable infrastructure’. When you deploy a computing component, such as a Lambda, you should avoid in-situ changes. If you want to change an existing function, just destroy it and create a new one.
We’ve moved away from nurturing our servers like pets, now with a Lambda you simply dispose of the old and create a new one. It’s not special.
Actually, with Lambda functions there isn’t even anything to get rid of! Since they’re completely ephemeral, they don’t even exist if they’re not in use.
When the Lambda service gets a request to invoke a particular Lambda, it is done by reference code.
So, now you simply write the new code and then, when you deploy it, you go to the place where the service would find it and tell it, “Forget the old code, this is the code to run now when you’re requested to invoke it.”
Immutable infrastructure means we no longer have to worry about configuration management tools.
Serverless is short lived so it doesn’t get the chance to get sick, which makes Operation much easier.
So, does that mean we’ve finally reached the point of ‘NoOps’?
Well, NoOps is not an inevitable byproduct of moving to serverless. One of the premises of serverless is offloading as much responsibility as possible to the cloud provider. But that doesn’t mean you’re only left with business logic, there are still things you have to watch for. Serverless is a big step forward, but it doesn’t mean you won’t have to take care of things like scaling.
When you’re using cloud infrastructure, it’s very easy to scale, but that makes it easy to scale wrongly. It’s something that requires vigilance.
There’s a lot less operations work, but we’re not at NoOps yet. LessOps isn’t quite as catchy, though 😉
Monitoring – Change your tools and your mindset
And now we arrive at Monitoring, the final stop on our journey around the infinity loop before we return to the beginning and continue around again, and again, and again…
This is an apt place to end our journey, though, as it’s where we at Lumigo entered the world of serverless in the first place.
It wasn’t long into our first enthusiastic forays into serverless computing that we realized that this is a paradigm that requires a completely new approach to monitoring.
Put simply, your old tools won’t work for serverless. Monitoring is a much greater challenge in a distributed, event-driven architecture where code is ephemeral and each request might pass across several third-party services over which you have little control.
Distributed tracing – a way to follow those requests along those complex webs from end to end – is a must for any production-scale (or business critical) serverless environment.
While the serverless market is still relatively young, there are already a range of options available, from native AWS tools, like CloudWatch and X-Ray, to open source tools such as Zipkin and Jaeger. These tools will answer many of your needs, but do require a reasonable amount of work to set up and maintain.
If you’re at a scale, or if there’s a great deal of complexity to your system, it’s a good idea to test drive a commercial tool like Lumigo. Setup and maintenance are much less time consuming, and you get things like performance and cost metrics, correlated logs, virtual stack trace, alerting, and real-time mapping that all work out of the box.
Serverless CICD is still not clearly defined
While the principles of CICD remain the same for serverless as they ever were, the implementation of those principles, and the tools we use, have changed.
There still isn’t a clearly defined rulebook for serverless CICD. The technology is young and the community of developers using it is still growing.
In this article, we’ve outlined our approach. As a company with more than two years working on purely serverless architecture we’ve had more time than most to optimize our processes, but we’re keenly aware that we don’t have all the answers. We just carry on making our way around the infinity loop, hopefully making incremental improvements each time around!
We hope this article contributes to the conversation around serverless CICD. Share your thoughts on Twitter.
