










LaunchDarkly has built an impressive feature flag management system that overages more than 200 billion feature flags per day. It has helped companies implement continuous deployment, A/B testing, infrastructure migrations and much more. It also enables canary launches (or dark launches) through its built-in support for percentage-based rollouts.
A few weeks ago we discussed the canary deployment options for AWS Lambda. We discussed the limitations of implementing canary deployments using weighted aliases:
- It uses traffic-based routing, which can mean far more users hitting the new code than we anticipate.
- There’s no support for propagating routing decisions along a call chain, as the user request is processed by several functions.
- Lambda does not publish metrics for each of the versions, so we cannot monitor the performance of the two versions separately.
In this post, we’ll investigate how to integrate with LaunchDarkly from AWS Lambda and see how feasible a solution it is.
AWS Lambda + LaunchDarkly
The LaunchDarkly SDK relies on a persistent connection to their streaming API to receive server-sent events (SSE) whenever feature flags change. Their pricing model is also tied to the number of server connections we need (amongst other things).
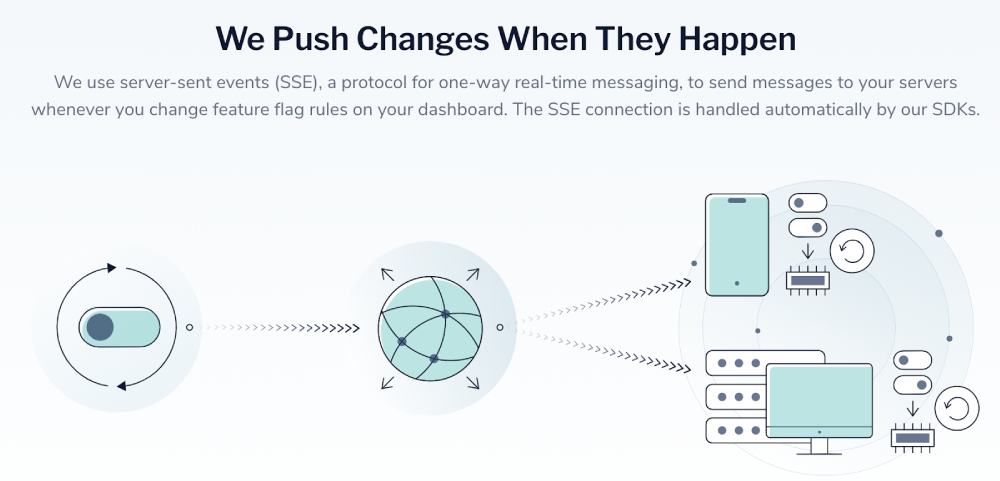
But the Node.js SDK gives us the option to use polling mode instead. More on this later.
The use of persistent connections immediately signals trouble as they don’t work well with Lambda. They are often the source of problems for Lambda functions that have to use RDS. Indeed, a set of practices were necessary to make them bearable in the context of RDS, which is not applicable here.
As an experiment to see how well LaunchDarkly works with Lambda, I set up a project with two functions on the call chain. Both connect to LaunchDarkly via the office Node.js SDK.
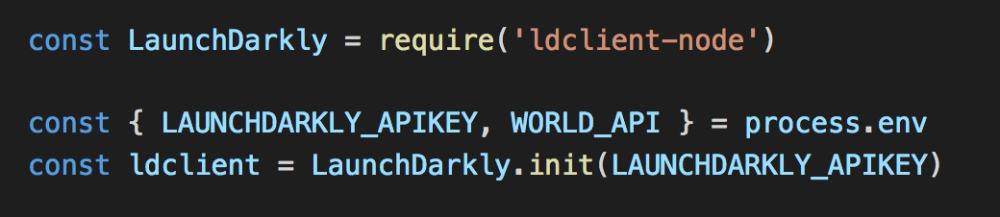
As you can see, the default configuration is used here. According to the documentation, the SDK would maintain a persistent connection and stream updates via SSE.
This is the high-level architecture for the test project.
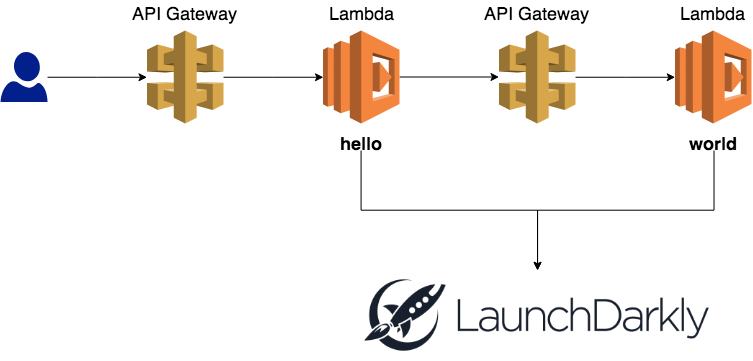
- The hello function receives an identifier for the user via query string parameters.
- It would check the value of a feature flag called “test”.
- It would then call the world function through its API endpoint, and forward the user id along via query string.
- The world function also checks the value of the “test” feature flag.
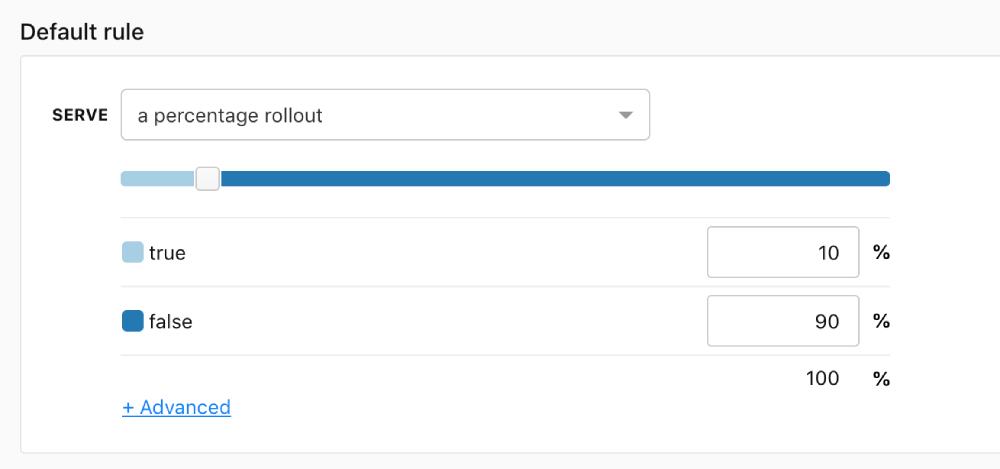
The “test” feature flag is set up with a percentage rollout.
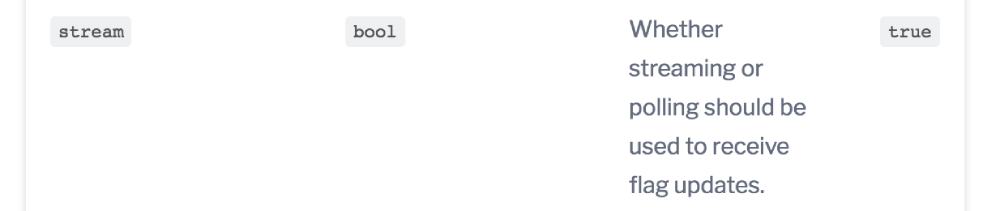
We can ask for the value of this feature flag (a boolean) with this line of code:

10% of the users should receive a value of true, while the rest would receive false.
In this case, both functions received the same answer. And no matter how many times I asked, the answer was always the same for a given user. These two tests proved that routing is done by user and not traffic, which is what we want.

The call to ldclient.variation also created the user profile for me based on the information that was sent along. From this screen, we can also see the value of the “test” feature flag that will be returned for me.
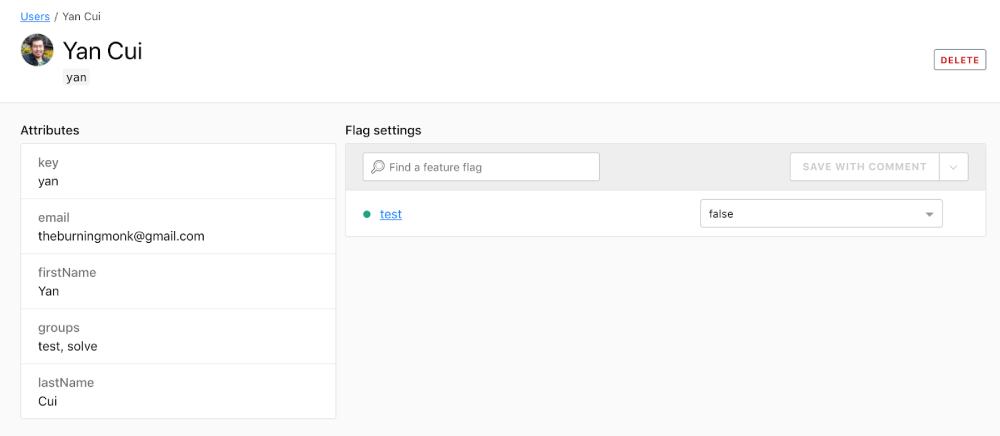
I can update my profile to return true and save the change with a compulsory comment.
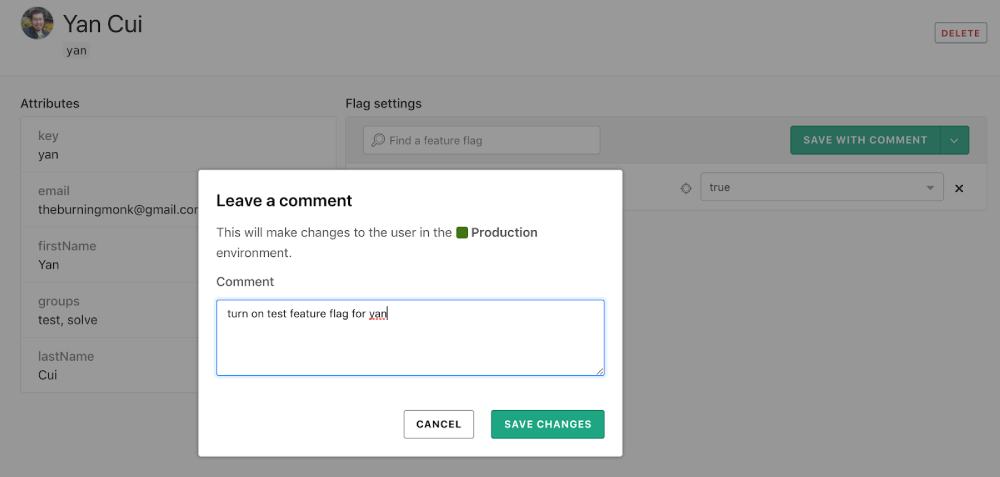
After saving the change, the API response from our endpoints was updated right away.

This is interesting because our functions were not actively running when I made the change. So they couldn’t have received the SSE update from the persistent connection. At this point I tried switching to polling mode and the updates took much longer (30+ seconds) to come through. I also managed to get different responses from the two functions as their polling schedules are probably not in-sync.

Manually changing the flag setting for my profile automatically added me to the list of targeted individual users.
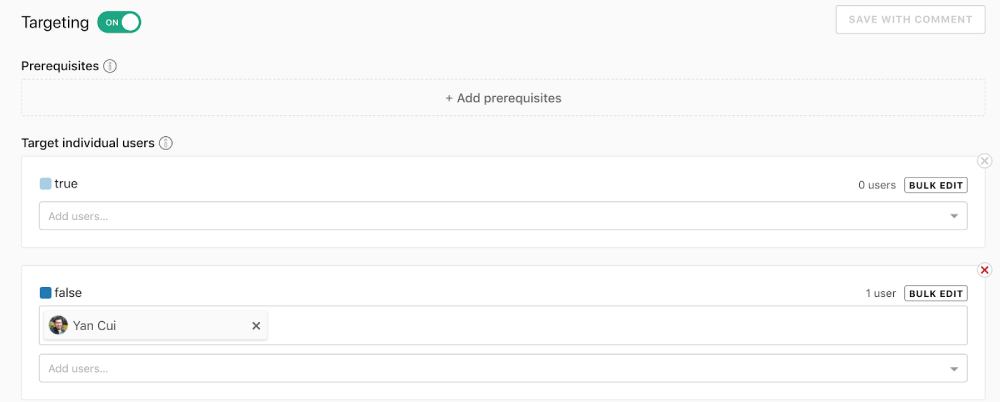
In addition to targeting specific users, we can also set up rules that target groups of users. We can do this against any of the users’ attributes, or against any user segments that we have set up.

What value is returned for a user is determined with the following priority:
- Settings for targeted users have the highest priority.
- Settings for users targeted by match rules.
- Default rule (percentage-based rollout in this case) for the feature.
That’s how LaunchDarkly works, in a nutshell. Out of the box it seems to work well with AWS Lambda although the use of persistent connections would still be a problem. The Starter package limits us to a measly 5 server connections. Even the Professional package only allows for up to 25 server connections.
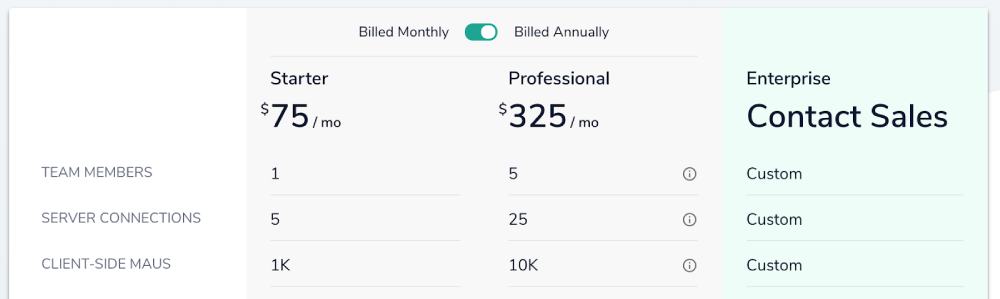
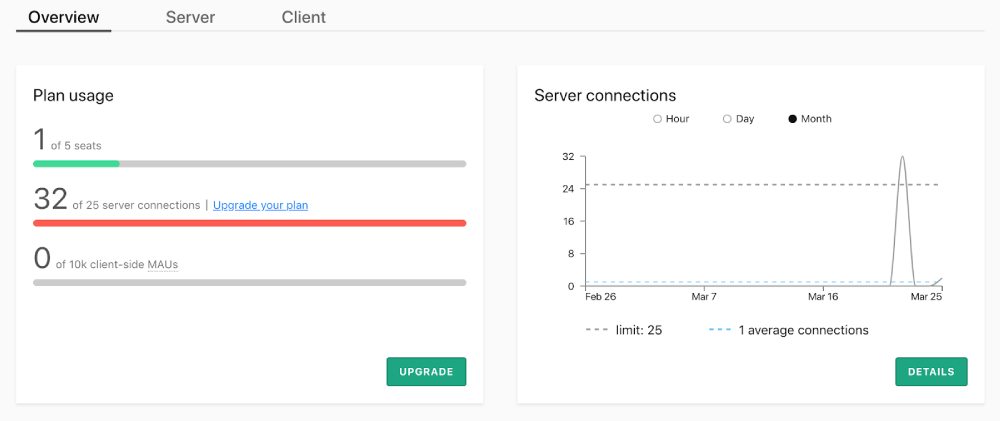
Since every concurrent execution of our functions would need a server connection, we can easily exceed these limits. With 16 concurrent requests and two functions in the call chain, I was able to exceed the 25 server connections limit. All my requests still completed successfully, there was no throttling. But I did get a prompt in the Usages screen to upgrade my plan. One would assume that new connections would be throttled at some point to prevent DDOS attacks.
Canary deployment with LaunchDarkly
To implement canary deployment with weight aliases, you run two different versions of your code side-by-side. The weighted alias would distribute traffic to the two versions.
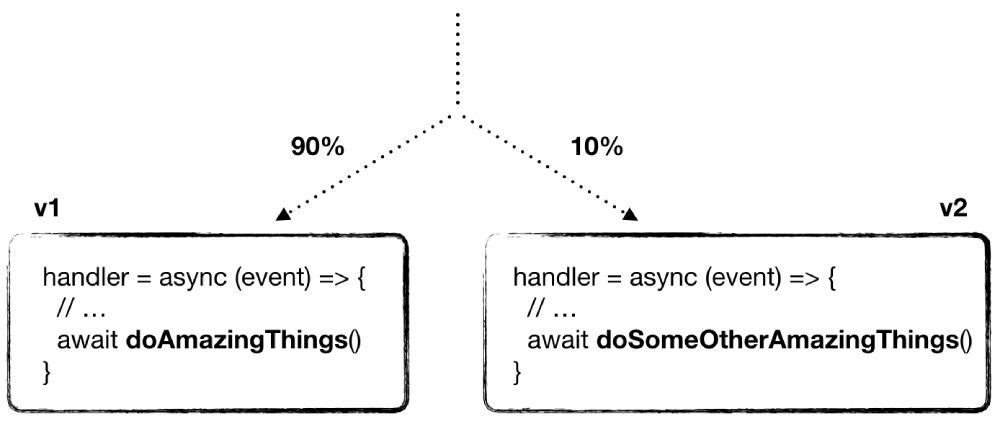
With LaunchDarkly, you will implement canary deployments with feature toggles. You will have just one version of your code running. Which execution path a user would take is determined by the configuration of the “canary” feature.

We will add the if statement the moment we start working on the new behavior. Since the feature has not been configured in LaunchDarkly, the variation request would always return false (the default value we set in the request). Since the new behavior is safely tucked away behind the if statement, we can continue to deploy changes to the current behavior. Users won’t be accidentally exposed to the new code.
For extra safety, we can also initialize the LaunchDarkly client in offline mode so it’ll always use the hardcoded default.
When we’re ready to roll out the new code gradually, we will set up the “canary” feature in LaunchDarkly using a “percentage rollout”. Just as before, we will keep an eye on the metrics to make sure the new code is working as intended. And when we’re confident the new code is behaving correctly we will turn on the change for all users.
The same process would work for one function as well as multiple functions on a call chain. As we saw earlier, all functions get near-instant update to the status of features. This ensures all the functions would follow the same routing decision with regards to enabling the new code path.
Summary
In this post we discussed how LaunchDarkly works and how you can integrate with it from AWS Lambda. While it worked out of the box, the fact that the SDK requires persistent connections is a concern. As the number of concurrent executions increases, you can easily exceed the max no. of server connections to LaunchDarkly.
There is a polling mod. But it doesn’t affect the number of server connections required. In cases where there are multiple functions on a call chain, we want all functions to follow the same feature toggling decision. Polling introduces large time windows where inconsistencies can exist between these functions, which is undesirable.
Finally, we looked at how we can implement canary deployments using feature toggles and how it differs from the approach with weighted aliases.
Overall, I really liked the development experience with LaunchDarkly. It was easy to integrate with and the configuration of features was intuitive. However, the concern with persistent connections remain.
Out of the box, LaunchDarkly is not designed for Lambda-based backend systems. However, there are workarounds available in the form of the node-dynamodb-store and ld-relay projects. They allow you to create a proxy layer (using Docker containers) that relays updates LaunchDarkly to a DynamoDB table. The Lambda functions can then use the node-dynamodb-store library to fetch updates from DynamoDB. Removing the need for the function to maintain a persistent connection to LaunchDarkly’s streaming API altogether.

The main downside to this workaround is that you will need to manage some containerized infrastructure. But I think the return on investment is worth it. LaunchDarkly can do so much more for your product development than just facilitating canary deployments. And you can delegate much of the operational responsibilities of running the relay to Fargate.