










Back in 2017, I wrote a post titled “3 pro tips for Developers working with Kinesis streams”, in which I explained why you should avoid hot streams with many Lambda subscribers. When you have five or more functions subscribed to a Kinesis stream you will start to notice lots of ReadProvisionedThroughputExceeded errors in CloudWatch.
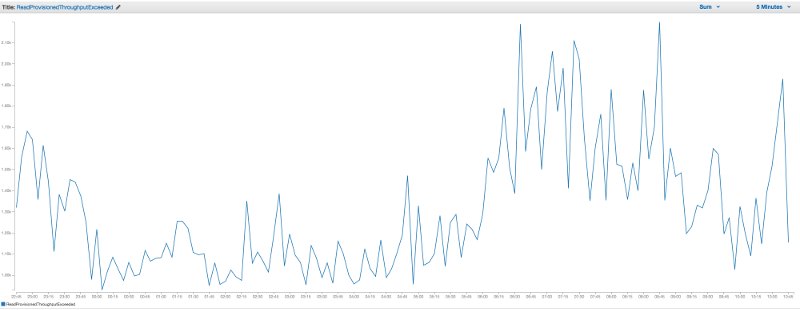
The problem here is that you’re constrained by the five reads per shard per second limit. Adding more shards would not solve the problem since every shard gets one concurrent execution of each subscriber function. The number of read requests per second is therefore proportional to the number of subscriber functions.
Fortunately, you don’t have to handle these errors, they’re handled and retried by Lambda’s internal polling layer for Kinesis. But they can cause occasional delays to events being forwarded to your functions. From experience, I observed IteratorAge spikes over 10s when contentions were particularly high.
Since then AWS has introduced enhanced fan-out for Kinesis streams, which is supported by Lambda natively. With enhanced fan-out, each function would be able to do five reads per second per shard, up to 2MB per second.
So, has it rendered the problems of hot streams a thing of the past? Let’s investigate.
The experiment
As explained earlier, the number of ReadProvisionedThroughputExceeded errors is not important on its own. Instead, we’re interested to understand the impact on IteratorAge which tells us when our functions are lagging behind due to contention.
For this experiment, we subscribed up to 30 functions to a Kinesis stream and monitored the metrics for ReadProvisionedThroughputExceeded and IteratorAge along the way.
As you can see from the diagram below, the number of ReadProvisionedThroughputExceeded errors increased linearly with the number of subscribers. All the while, the IteratorAge was unaffected – the spikes were results of new subscribers catching up with the stream. Also, the peak of the spikes was a measly 3ms and not worth worrying about.
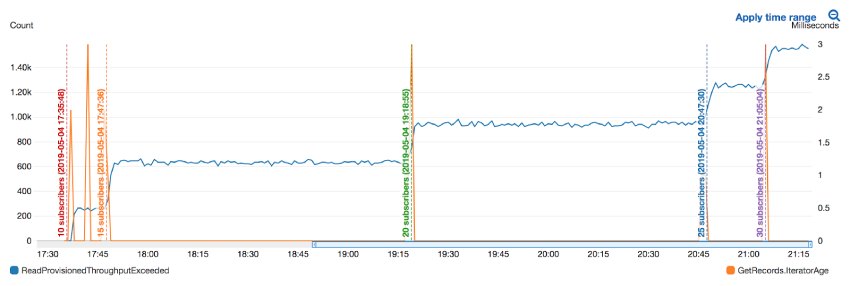
So with 30 subscriber Lambda functions, we still see a consistent number of ReadProvisionedThroughputExceeded errors. Although these no longer seem to affect the performance and throughput of our functions.
However, during the experiment, I encountered an even more serious problem.
After the first 15 functions were deployed and subscribed to the stream, it became almost impossible to deploy any subsequent functions. Every attempt to add another group of subscriber functions was met with ProvisionThroughputExceededException errors during deployment.

I was able to work around this limitation by creating the functions in the console and manually attaching the Kinesis stream as the event source. Even so, I still encountered the same error time and again. It took me numerous attempts to enable the Kinesis event source for every function.
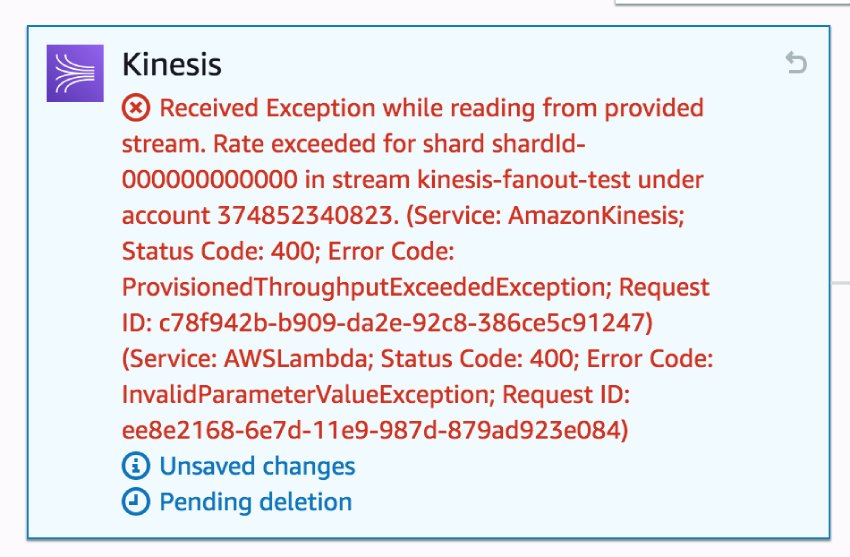
This was an unwelcome nuisance for the experiment. But for a system running in production, it will be an outright showstopper! Most companies rely on an automated CI/CD pipeline to deploy their code through a series of environment. This type of error will stop your CI/CD pipeline dead in its tracks and force you to manually retry failed steps over and over. It makes your CI/CD pipeline unreliable and you have to depend on luck for deployments to succeed. That is simply not acceptable!
Workarounds
So if hot streams are still a problem then what can you do? Here are some design decisions and considerations for you to think about.
One write stream vs many write streams
If having many subscribers to one stream is a problem then how about we write events to multiple streams in the first place? For instance, an e-commerce system might record events related to user profiles, orders and promotions in separate streams. Functions that are interested in these events would subscribe to one of the streams.
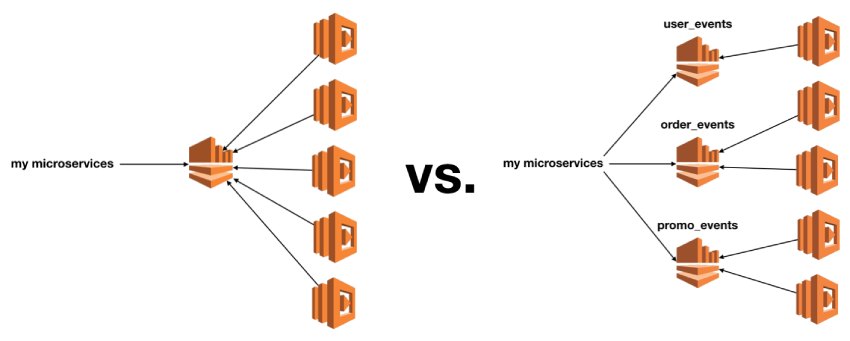
Compared to one centralised stream, this approach spreads the subscribers around. However, it might not be a permanent solution, as it’s still possible to end up with too many subscribers for one of the specialised streams. Just as most of what happens on an e-commerce site revolves around orders, many subsystems would need to listen to the order_events stream. Over time, you could still end up with too many subscribers for one stream.
You also lose ordering across events in different streams. It’s possible for a function to subscribe to multiple Kinesis streams, but the events from the two streams would arrive in different invocations. And you’re not guaranteed to receive them in the same order as they were recorded, even if they have the same partition key (e.g. the user_id). This makes some business logic difficult to implement.
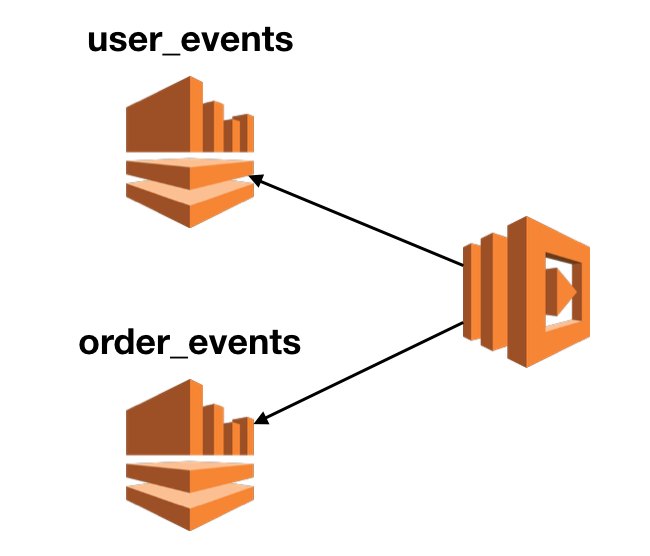
Finally, it creates implicit coupling between the producer and consumer of these events. As practitioners of microservices would tell you, service boundaries are often fluid and can change over time. The same goes for domain events. This approach makes it very difficult to change the stream an event is published to. To migrate an event to a new stream safely and without requiring downtime, you need to publish the same event to both the new and old stream. This lets you maintain backward compatibility and allows the consumers to migrate over to the new stream according to their release schedule. But it also introduces the potential for duplicated events if there’s a consumer that listens to both streams. One such scenario is when you have a Business Intelligence (BI) pipeline that aggregates all the events into Athena for analysis.
Fan-out to multiple reader streams
I think a better approach is to push all events to a centralized stream and then use this technique to fan-out to multiple reader streams. This can be done at an “as needed” basis and allows you to localize those decisions to each reader. It also supports cases where you need to combine different types of event in the same stream in order to maintain overall ordering.
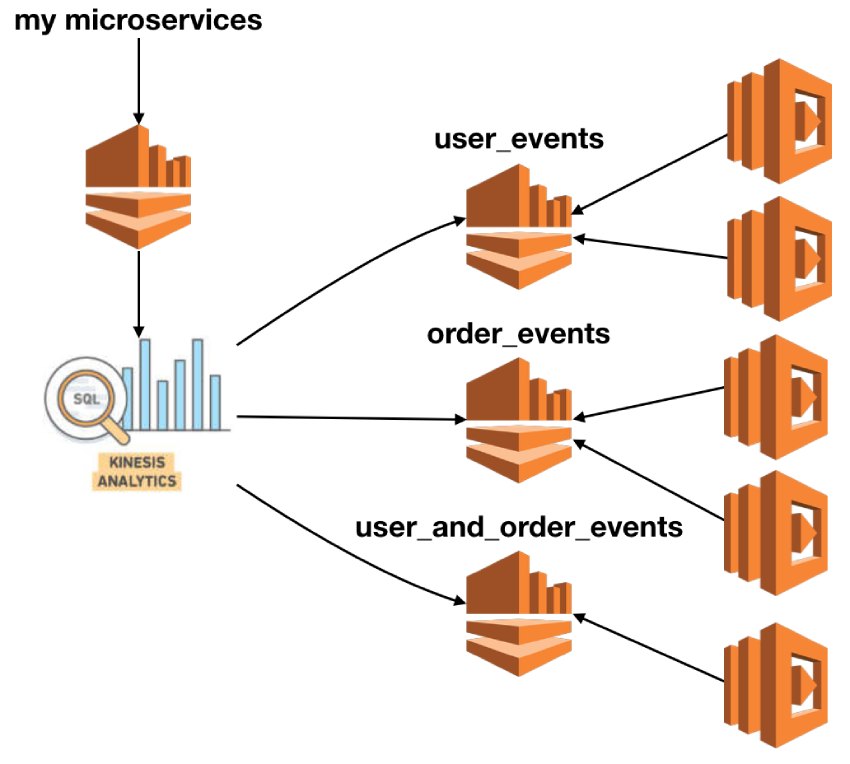
I like this approach because it offers a lot of flexibility to how you want to slice and dice events into streams. It enables team autonomy as producer and consumer services are not tightly coupled by the decision of “where to publish event X to”.
The main downside to this approach is cost. In addition to the centralised stream, you will also pay for data processing for Kinesis Analytics as well as all the specialised streams. Notice that I shied away from suggesting one stream per consumer because that will incur the biggest cost overhead. In most cases, I believe it’s sufficient to group events into domain areas. This offers a good compromise between scale (no. of subscribers) and cost.
Summary
In this post, we looked at the effect Kinesis enhanced fan-out has on the number of subscribers you can have on a stream. While things have improved a lot since 2017, the problem still persists when you have more than a dozen subscriber functions. The problem might have shifted to your ability to reliably deploy your functions.
We looked at ways to work around this limitation and considered the approach of using multiple streams instead of a centralised one. We discussed the problems with this approach:
- You can still end up with too many subscribers on one of the specialised streams.
- You lose ordering of related events when they are published to different streams.
- It’s difficult to change your mind later and publish an event to a different stream.
Instead, I propose a different approach to address this issue of hot streams – by using Kinesis Analytics to fan out events to specialized streams. This offers you a lot more flexibility at the expense of additional cost incurred for running the extra Kinesis streams. However, when thinking about cost, you should focus on the Total Cost of Ownership (TCO) and not just your AWS bill. It is too often the case that any saving on your AWS bill is dwarfed by the loss of productivity (e.g. engineering time) and focus on the part of the company. Incidentally, it’s something that many people get wrong when they think about the cost of serverless!