 All Resources
All Resources Docs
Docs Blog
Blog Guides
GuidesAWS Lambda Canary Deployment
- Topics
Using Canary Deployments with Lambda
By Yan Cui With AWS Lambda deployment, we get blue-green deployment out of the box. After we update our code, requests against our function would be routed to the new version. The platform would then automatically dispose of all containers running the old code to free up resources.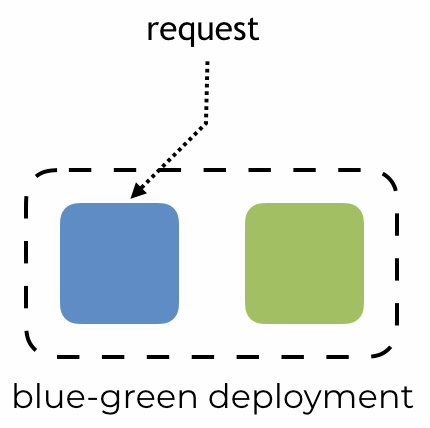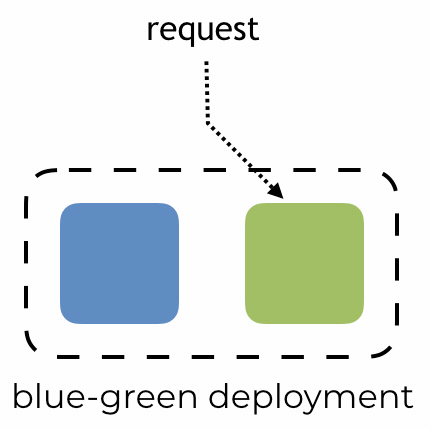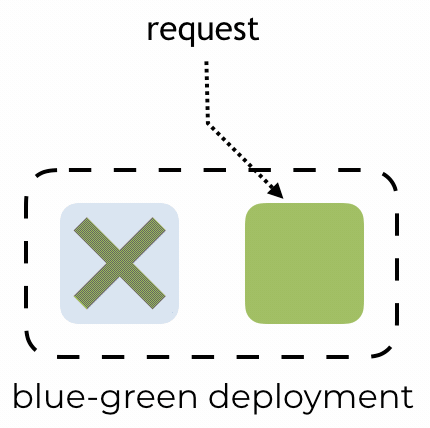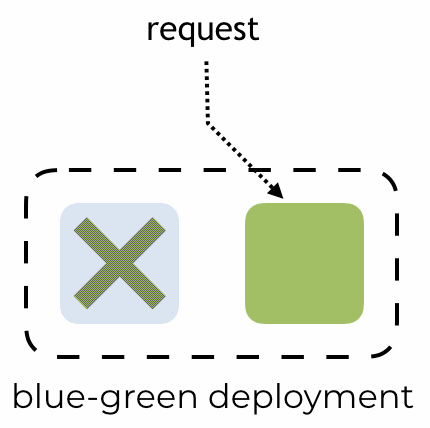
In this article
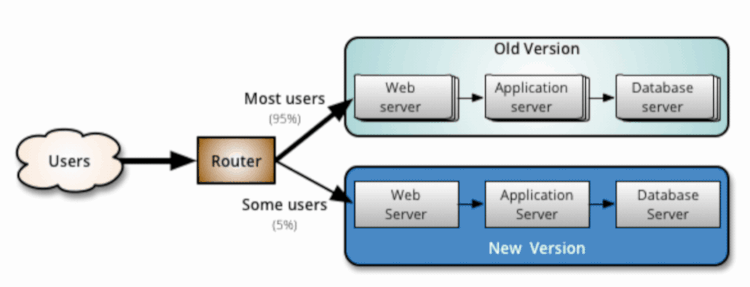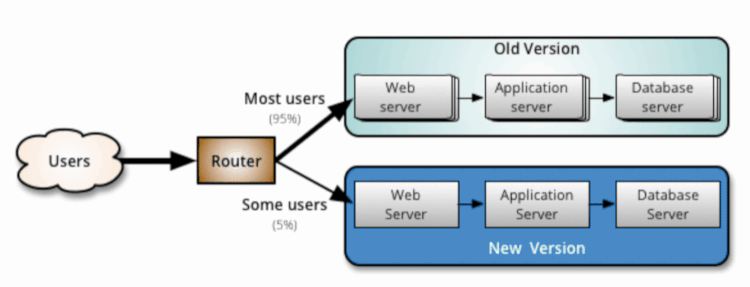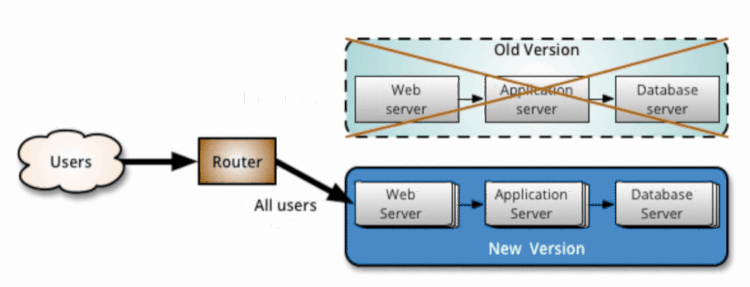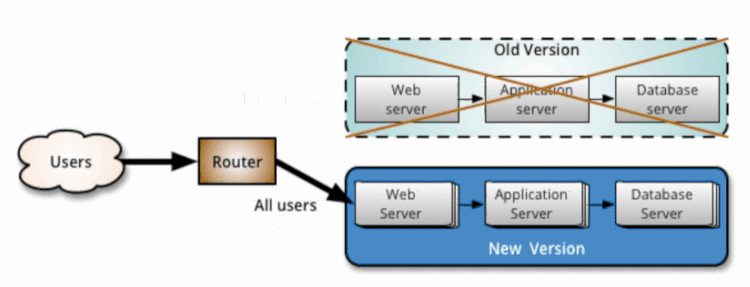
Canary deployment for AWS Lambda
AWS Lambda has built-in support for canary deployments through weighted aliases and CodeDeploy.Weighted aliases
With a weighted alias, you can control and route traffic to two versions of the same function based on your configured weighting.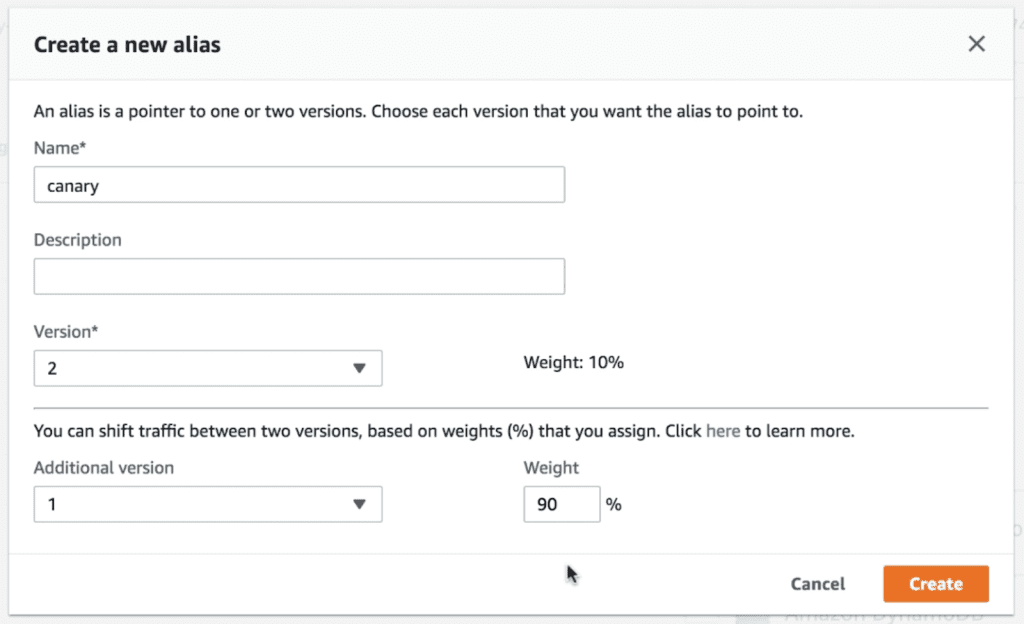
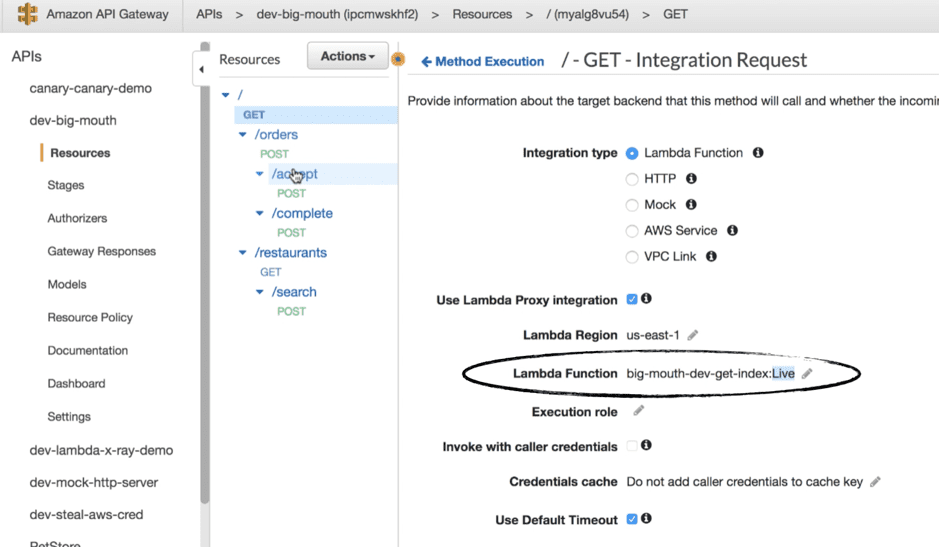
CodeDeploy
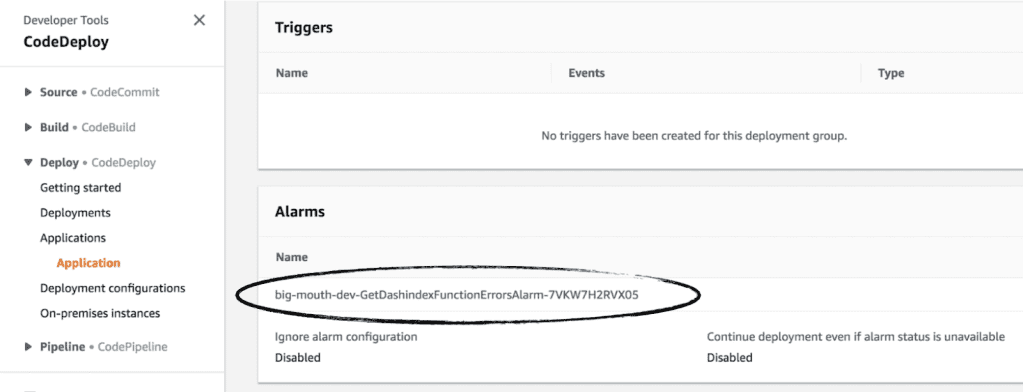
During a canary deployment, we need to monitor the system and adjust the traffic routing configuration only when we are satisfied the new code is working properly. If the performance or health of the system degrades, then we need to stop and rollback the change before it impacts any more users. CodeDeploy can automate the entire process for us, and integrates directly with both CloudWatch and Lambda’s weighted alias. To enable automatic rollback, you need to configure CloudWatch alarms for the deployment. If any of the alarms are triggered during the deployment, then the current deployment would be stopped and rolled back to the previous version.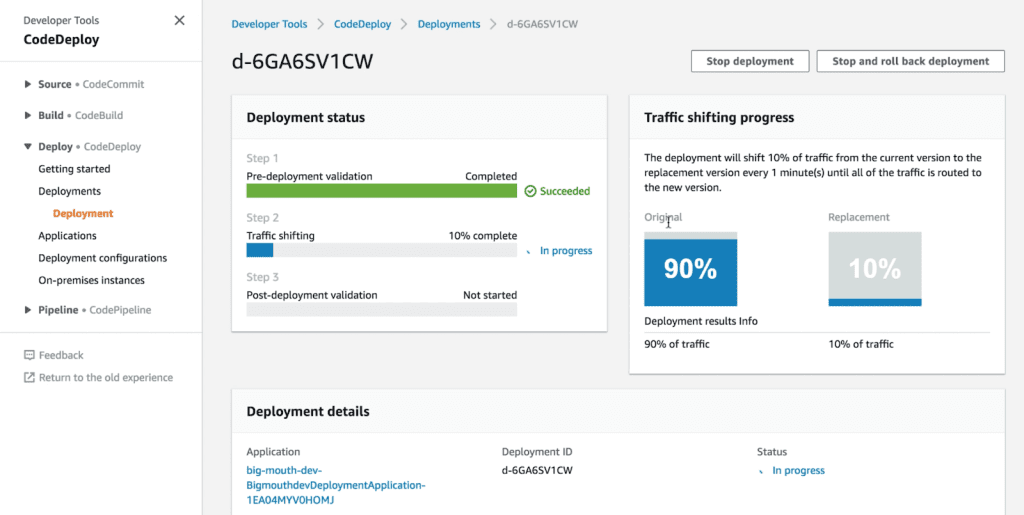
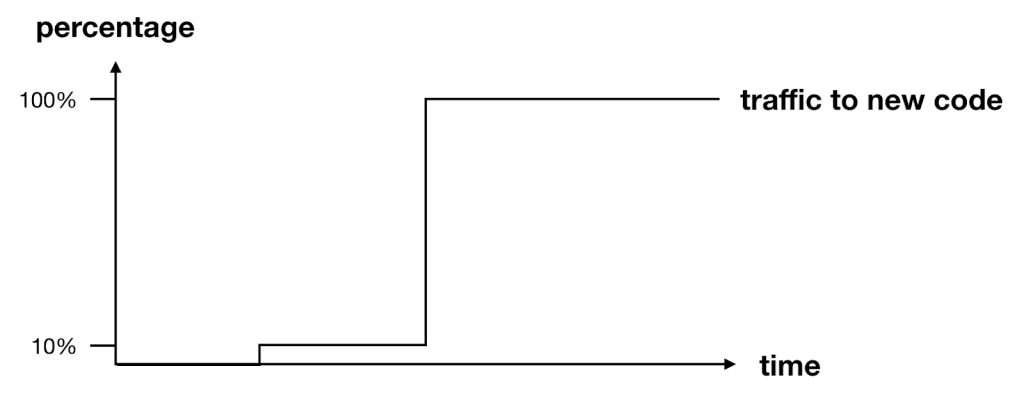
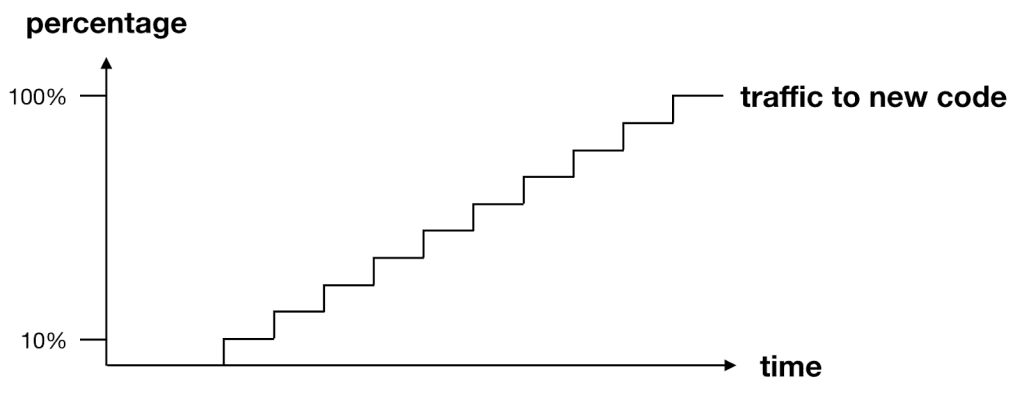
Limitations
I think these built-in tools are good enough for most people’s use cases. However, Lambda’s weighted aliases route traffic by request, not by user. That is a subtle, but important difference in at least two ways.Route users, not traffic
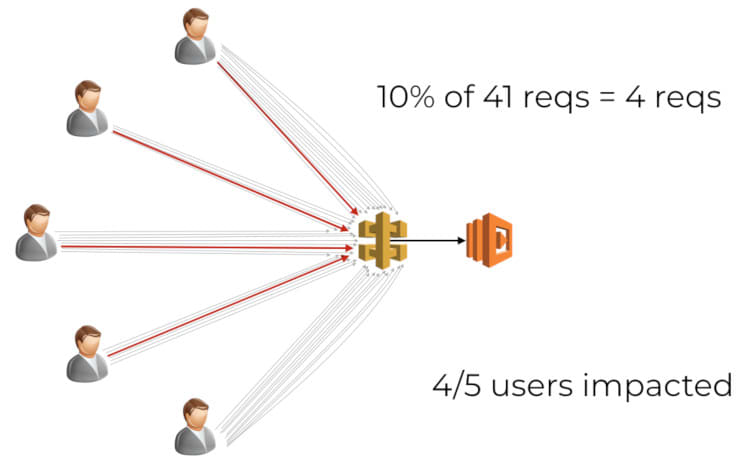
First, you cannot predicate how the requests are distributed amongst the users. In the below example, we received a total of 41 requests from 5 concurrent users.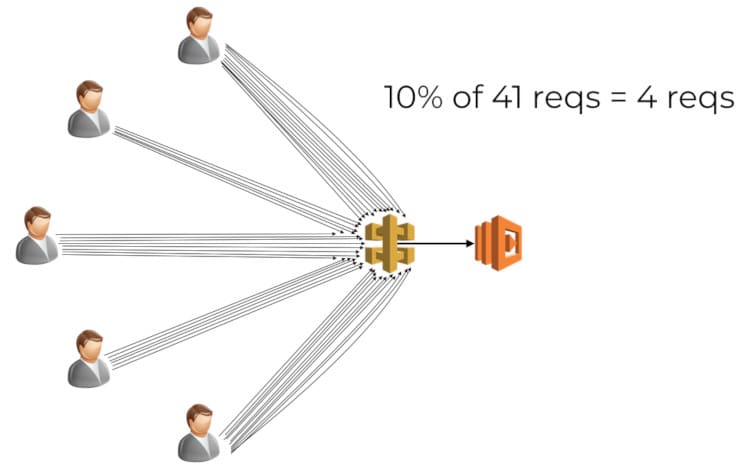
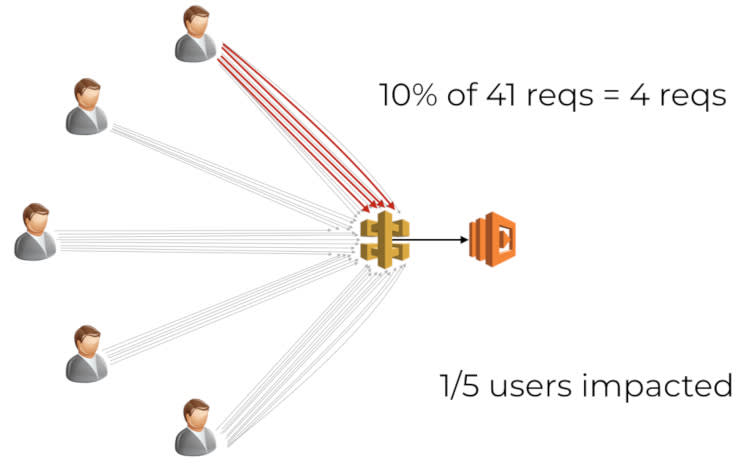
Propagate routing decisions
Another consequence of routing by request instead of user is that there is no way to propagate the routing decision along the call chain. This impacts you when multiple functions are involved and chained together through some means. Each function would route traffic between old and new code by request independently. This opens you up to problems related to compatibility between different versions of your code. Imagine a food ordering system, where the order flow is implemented in an event-driven fashion. There is an API entry point to place an order, and different events are published into a centralized Kinesis stream, for example, order_placed, user_notified, etc. This stream has multiple subscriber functions, each handle a different type of event.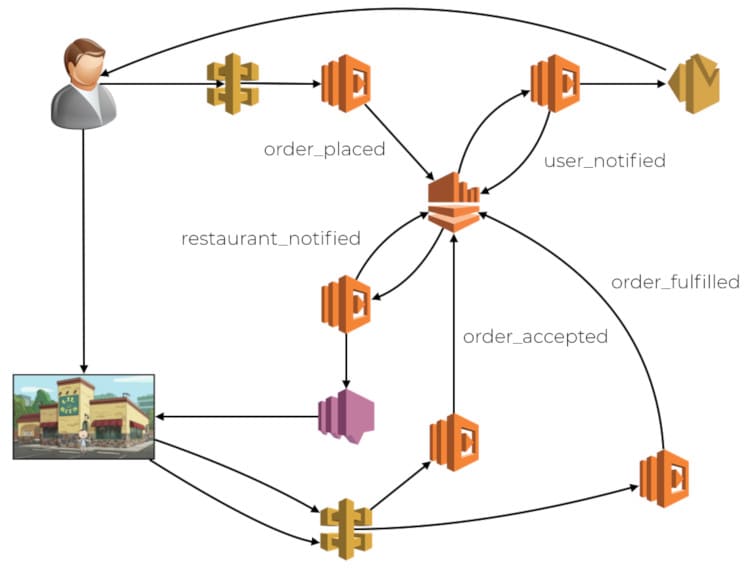
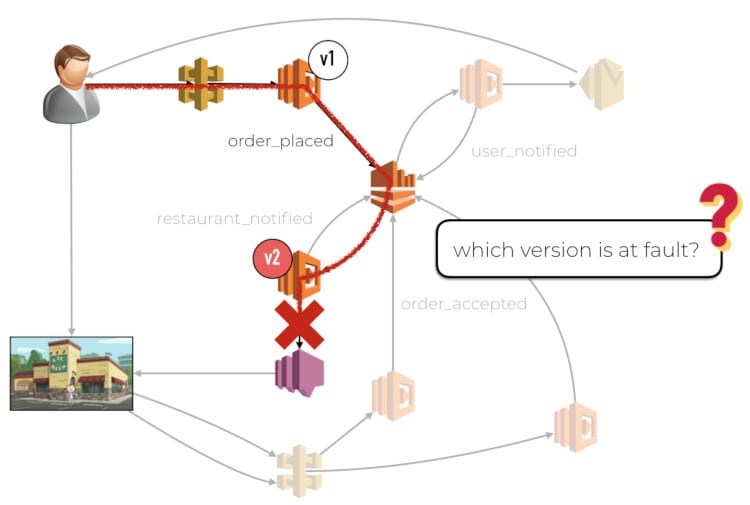
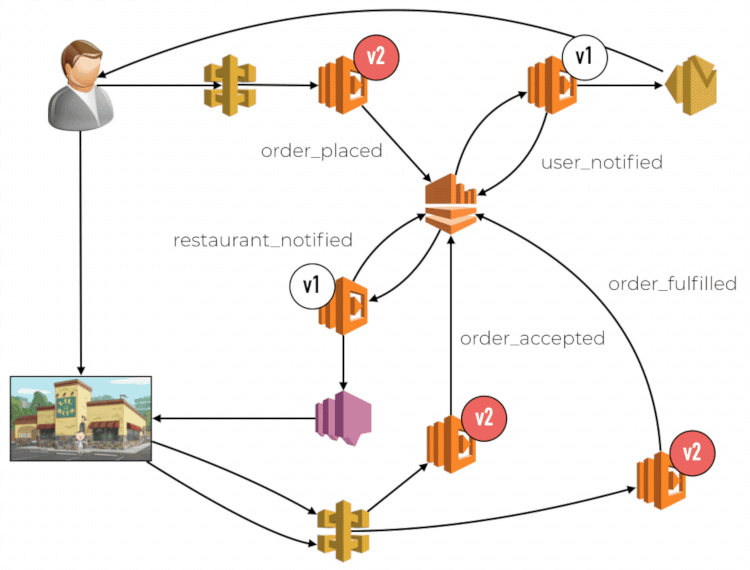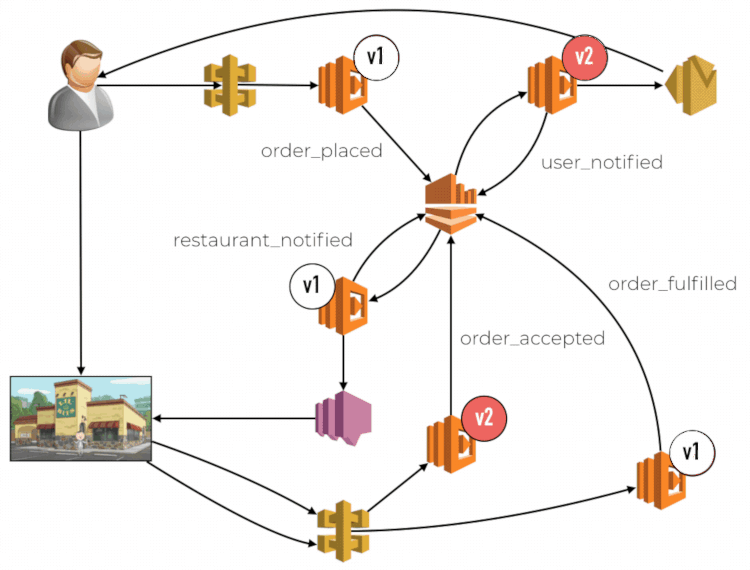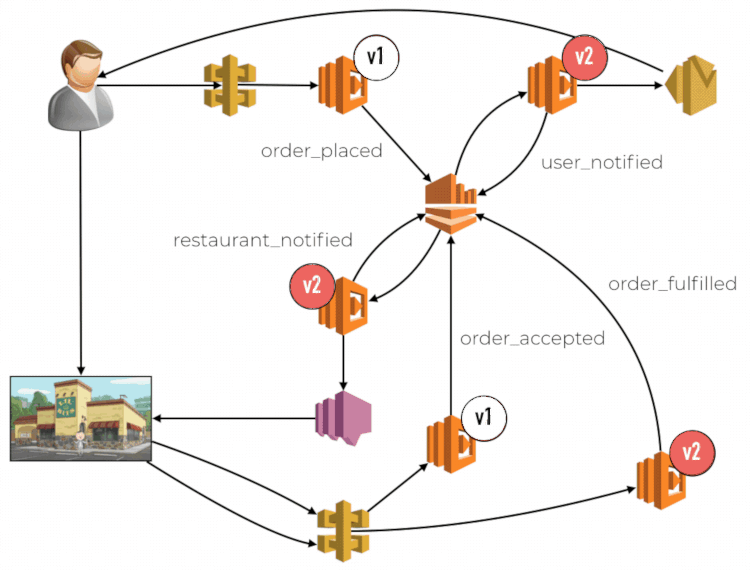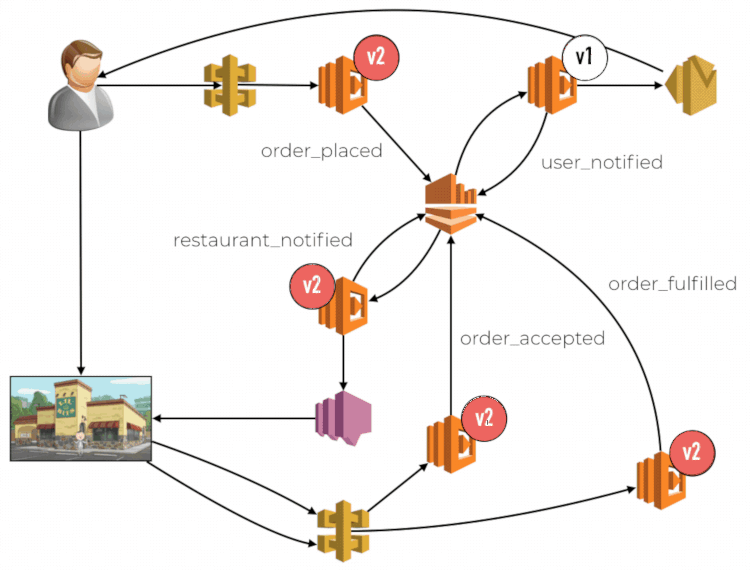
Limitations with CodeDeploy and CloudWatch
When you are using a weighted alias, the CloudWatch metrics are not tracked against the specific version that was used. The metrics would report a dimension for the alias, but not the version. This means we are not able to monitor and isolate problems to the new code. It can lead to false positives triggering unnecessary rollbacks. Similarly, it can also mask performance issues with the new code. If the new code (v2) is performing poorly compared to the current production code (v1), as determined by the respective 95th or 99th percentile latencies. The fact that v2 only accounts for 10% of the traffic means its performance woes become less obvious when we look at the overall latency metric for the weighted alias.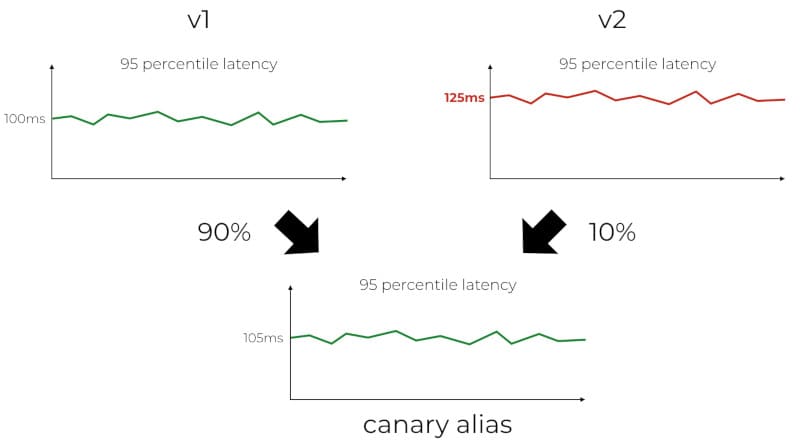

Alternative approaches
If the aforementioned limitations are a show stopper for you, then here are two possible alternatives for you to consider.Client-side traffic routing
The simplest alternative is to move the routing to the client. In this setup, you will deploy the new code under a different entrypoint. It might be a different domain altogether (e.g. canary.example.com), or a versioned path (e.g. example.com/v2/my-endpoint). You then need to give the client application a way to discover:- all the available URLs for each action, and
- whether the current user is in canary channel
Integrating with a third-party service such as LaunchDarkly
LaunchDarkly is the best known service for implementing feature toggles and can be used to support A/B tests. However, application server would traditionally keep a live socket connection to LaunchDarkly. This is how they discover changes to feature toggle settings from the control plane. Further investigation is needed to see how feasible it is to use LaunchDarkly from AWS Lambda.Conclusions
In summary, we discussed in this post:- The difference between blue-green deployment and canary deployment.
- How Lambda weighted alias and CodeDeploy works.
- The limitations and problems with weighted alias and CodeDeploy.
- Two alternative approaches to consider.