 All Resources
All Resources Docs
Docs Blog
Blog Guides
GuidesAmazon Builders’ Library in focus #2: Using load shedding to avoid overload

In the second of our new series of posts, Yan Cui highlights the key insights from the Amazon Builders’ Library article, Using load shedding to avoid overload, by AWS Principal Engineer (AWS Lambda) David Yanacek.
About the Amazon Builders’ Library
The Amazon Builders’ Library is a collection of articles written by principal engineers at Amazon that explain how Amazon builds scalable and resilient systems.
Disclaimer: some nuances might be lost in this shortened form. If you want to learn about the topic in more detail then check out the original article.
Using load shedding to avoid overload
Definition: brownout = a reduction in availability in a particular area (e.g. a server).
Picking an ideal max connection count is too difficult and imprecise as a way to manage the load on services (to strike the perfect balance between responsiveness and utilization).
The anatomy of overload
When a system is overloaded, its performance tends to degrade quickly (once it goes over a tipping point). Since clients cannot wait for a response forever, we start to experience client-side timeouts.

This negatively impacts the client-perceived availability – even if the system is technically “up”. As far as the client is concerned, it’s still not “available” since it can’t get a response.

Here’s another view of it, where good throughput (goodput) === throughput that can be handled in a timely fashion without errors.
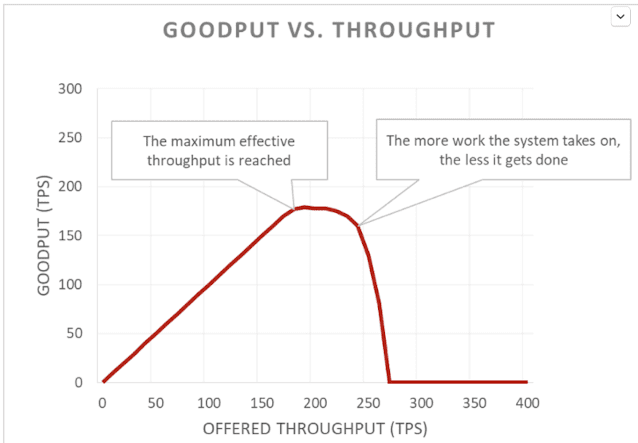
A vicious cycle starts when a system is overloaded – client times out before receiving the response, so work is wasted, then client retries and ends up putting more work on the service.
While shedding excess load reduces the service’s availability, it allows the service to maintain predictable and consistent performance for the accepted requests. This way, the service is able to raise its availability overall by making selective sacrifices.

However, it still takes work to reject excess load, which eventually will still push the service over its tipping point, but at a much later stage.

Testing
Load tests are important for teams to understand the system’s behaviour under load and evaluate the complexity tradeoff of introducing a load-shedding mechanism.
If during a load test, a system’s availability quickly hits zero as throughput increases then it’s a good sign that it needs a load-shedding mechanism. During these tests, it’s important to measure client-perceived availability and latency as well as the server-side latency and availability.
A full end-to-end load test can stress the system AND its dependencies, or you can isolate the test to individual hosts and still see the overload behaviour of the service.
Visibility
When shedding load, record the client and the operation, along with any other contextual information that can help you tune the process. And use alarms to notify the team when a significant amount of load is rejected.
Also, don’t pollute the service’s latency metric with rejected requests – rejected requests usually have extremely low latency which skews the latency of those accepted requests.
If load shedding has a similar config as auto-scaling (e.g. shed load at 85% CPU) then it might prevent auto-scaling from kicking in if load shedding artificially keeps the system metric below the scaling threshold.
This can also have an interesting impact on AZ-wide failures. If you run in 3 AZ then you typically over-provision to handle one AZ failing. This typically means you leave 33% headroom and run at 66% CPU. That way when you lose one AZ the other two can take over the load and run at 99% CPU. But if load shedding kicks in at 85% CPU then you’ll end up dropping lots of requests and be unable to use all of your headroom.
Load shedding can also save cost by shedding targeted, non-critical traffic – e.g. requests from search crawlers – in order to preserve latency for human traffic. This approach requires careful design, continuous testing and business buy-in and can give the false impression of availability drop during an AZ failure.
Load shedding mechanisms
Load test far beyond the point where goodput plateaus to help understand the cost of dropping requests – sometimes it can be more expensive to drop a request than hold on to it (e.g. due to bad socket settings or client-side retries).
When a server is overloaded, it can prioritize which requests to handle. The most important of which is the ping requests from the load balancer. When the system is overloaded, the last thing you want is for more servers to be deemed unhealthy and therefore reduce the fleet of available servers.
If the server knows the client would have timed out partway through a request, then it can skip the rest of the work and fail the request. The client can include timeout hints in each request, and the server can use them to drop doomed requests. The timeout hint can be absolute time or duration, but neither is perfectly precise. In a service call with multiple hops, the “remaining time” should be used as a hint to each downstream system.
For API that returns large dataset, use pagination. However, if the client is going to throw away all the paged results if it sees an error on the Nth page, then the server should prioritize requests for latter pages than requests for the first page.
You probably have several queues in the system – TCP buffer, in-memory queues, web framework executor queues, etc. Track how much time a task has sat in the queues and throw it out if it’s too old (think client timeout). This frees up the server to work on fresh tasks that have a greater chance of success. In extreme cases, Amazon looks for ways to use a LIFO queue instead (HTTP/2 generally supports it).
Load balancers also use surge queues to queue up requests to overloaded servers, which can lead to brownout. In general, it’s safer to fail-fast instead of queuing excess request. ALB does this whereas classic ELB uses surge queues.
You can use load shedding to protect the service in every layer – load balancers, OS, service framework and your code.
HTTP proxies often support max connections but make it difficult to prioritize important traffic, which is why it’s only used as a last resort at Amazon. Amazon’s approach is to set the max connection on load balancers and proxies high, and delegate to the server to implement more accurate load shedding with local information.
Operating system features for limiting server resource usage are powerful and can be helpful to use in emergencies. E.g. OS features like iptable can reject excess connections far more cheaply than any server process.
Other services can also help shed load before they get to the server – API Gateway has built-in throttling, and AWS WAF can also shed load on multiple dimensions and can be used with API Gateway, ALB or CloudFront.
Read part 1 of the Amazon Builders’ Library in Focus series – ‘Timeouts, retires and backoff with jitter’ here.